 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulating, Fast and Slow: Learning Policies for Black-Box Optimization
Jun 06, 2024
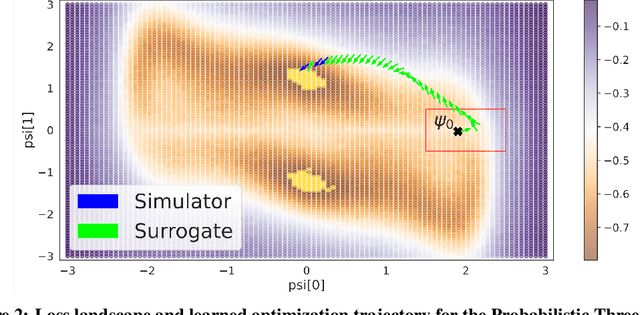
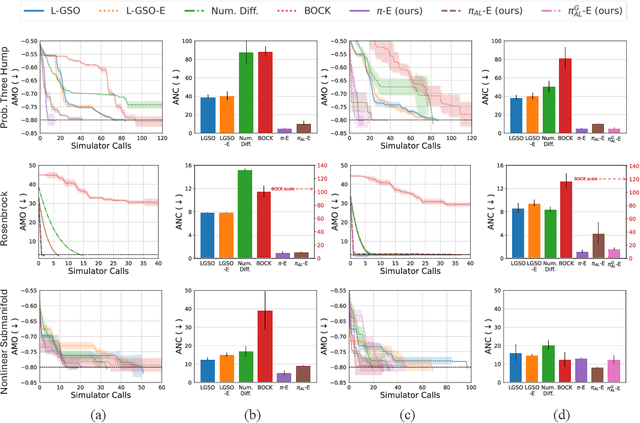
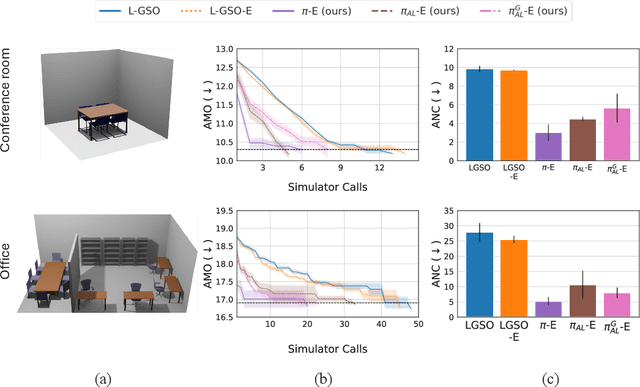
In recent years, solving optimization problems involving black-box simulators has become a point of focus for the machine learning community due to their ubiquity in science and engineering. The simulators describe a forward process $f_{\mathrm{sim}}: (\psi, x) \rightarrow y$ from simulation parameters $\psi$ and input data $x$ to observations $y$, and the goal of the optimization problem is to find parameters $\psi$ that minimize a desired loss function. Sophisticated optimization algorithms typically require gradient information regarding the forward process, $f_{\mathrm{sim}}$, with respect to the parameters $\psi$. However, obtaining gradients from black-box simulators can often be prohibitively expensive or, in some cases, impossible. Furthermore, in many applications, practitioners aim to solve a set of related problems. Thus, starting the optimization ``ab initio", i.e. from scratch, each time might be inefficient if the forward model is expensive to evaluate. To address those challenges, this paper introduces a novel method for solving classes of similar black-box optimization problems by learning an active learning policy that guides a differentiable surrogate's training and uses the surrogate's gradients to optimize the simulation parameters with gradient descent. After training the policy, downstream optimization of problems involving black-box simulators requires up to $\sim$90\% fewer expensive simulator calls compared to baselines such as local surrogate-based approaches, numerical optimization, and Bayesian methods.
Learning Objective-Specific Active Learning Strategies with Attentive Neural Processes
Sep 11, 2023



Pool-based active learning (AL) is a promising technology for increasing data-efficiency of machine learning models. However, surveys show that performance of recent AL methods is very sensitive to the choice of dataset and training setting, making them unsuitable for general application. In order to tackle this problem, the field Learning Active Learning (LAL) suggests to learn the active learning strategy itself, allowing it to adapt to the given setting. In this work, we propose a novel LAL method for classification that exploits symmetry and independence properties of the active learning problem with an Attentive Conditional Neural Process model. Our approach is based on learning from a myopic oracle, which gives our model the ability to adapt to non-standard objectives, such as those that do not equally weight the error on all data points. We experimentally verify that our Neural Process model outperforms a variety of baselines in these settings. Finally, our experiments show that our model exhibits a tendency towards improved stability to changing datasets. However, performance is sensitive to choice of classifier and more work is necessary to reduce the performance the gap with the myopic oracle and to improve scalability. We present our work as a proof-of-concept for LAL on nonstandard objectives and hope our analysis and modelling considerations inspire future LAL work.
E-Valuating Classifier Two-Sample Tests
Oct 24, 2022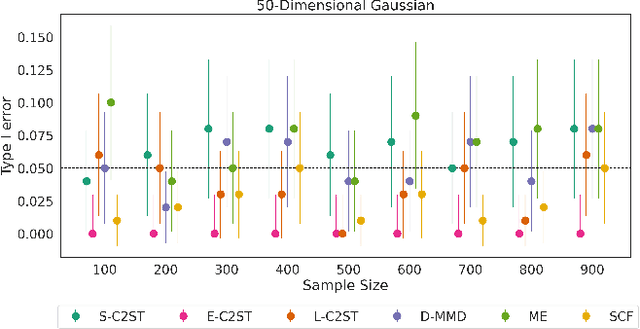
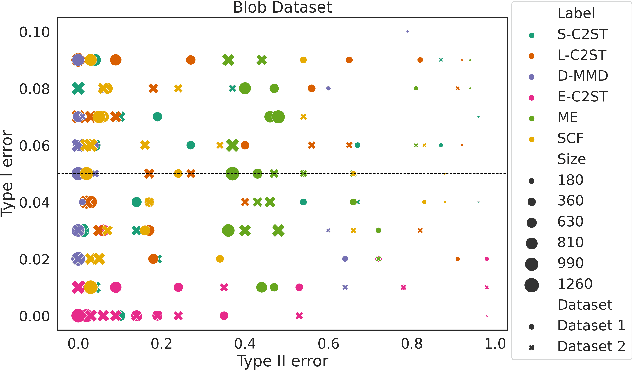
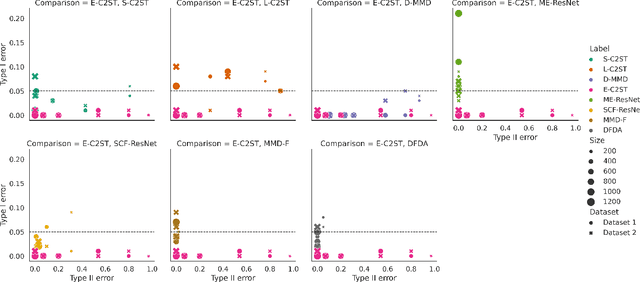
We propose E-C2ST, a classifier two-sample test for high-dimensional data based on E-values. Compared to $p$-values-based tests, tests with E-values have finite sample guarantees for the type I error. E-C2ST combines ideas from existing work on split likelihood ratio tests and predictive independence testing. The resulting E-values incorporate information about the alternative hypothesis. We demonstrate the utility of E-C2ST on simulated and real-life data. In all experiments, we observe that when going from small to large sample sizes, as expected, E-C2ST starts with lower power compared to other methods but eventually converges towards one. Simultaneously, E-C2ST's type I error stays substantially below the chosen significance level, which is not always the case for the baseline methods. Finally, we use an MRI dataset to demonstrate that multiplying E-values from multiple independently conducted studies leads to a combined E-value that retains the finite sample type I error guarantees while increasing the power.
On learning adaptive acquisition policies for undersampled multi-coil MRI reconstruction
Mar 30, 2022

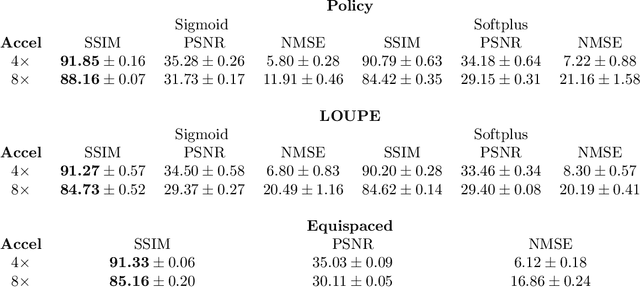

Most current approaches to undersampled multi-coil MRI reconstruction focus on learning the reconstruction model for a fixed, equidistant acquisition trajectory. In this paper, we study the problem of joint learning of the reconstruction model together with acquisition policies. To this end, we extend the End-to-End Variational Network with learnable acquisition policies that can adapt to different data points. We validate our model on a coil-compressed version of the large scale undersampled multi-coil fastMRI dataset using two undersampling factors: $4\times$ and $8\times$. Our experiments show on-par performance with the learnable non-adaptive and handcrafted equidistant strategies at $4\times$, and an observed improvement of more than $2\%$ in SSIM at $8\times$ acceleration, suggesting that potentially-adaptive $k$-space acquisition trajectories can improve reconstructed image quality for larger acceleration factors. However, and perhaps surprisingly, our best performing policies learn to be explicitly non-adaptive.
Back to Basics: Deep Reinforcement Learning in Traffic Signal Control
Sep 15, 2021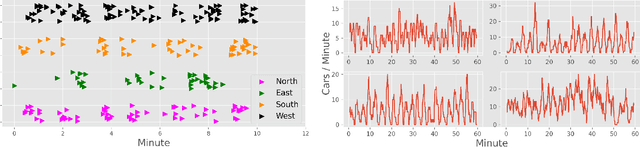
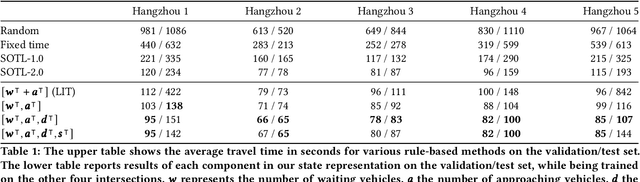
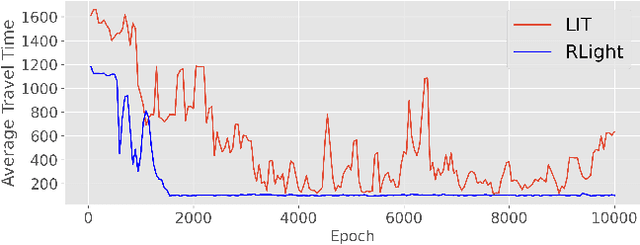
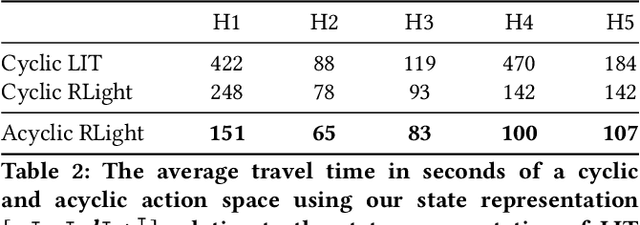
In this paper we revisit some of the fundamental premises for a reinforcement learning (RL) approach to self-learning traffic lights. We propose RLight, a combination of choices that offers robust performance and good generalization to unseen traffic flows. In particular, our main contributions are threefold: our lightweight and cluster-aware state representation leads to improved performance; we reformulate the MDP such that it skips redundant timesteps of yellow light, speeding up learning by 30%; and we investigate the action space and provide insight into the difference in performance between acyclic and cyclic phase transitions. Additionally, we provide insights into the generalisation of the methods to unseen traffic. Evaluations using the real-world Hangzhou traffic dataset show that RLight outperforms state-of-the-art rule-based and deep reinforcement learning algorithms, demonstrating the potential of RL-based methods to improve urban traffic flows.
Experimental design for MRI by greedy policy search
Oct 30, 2020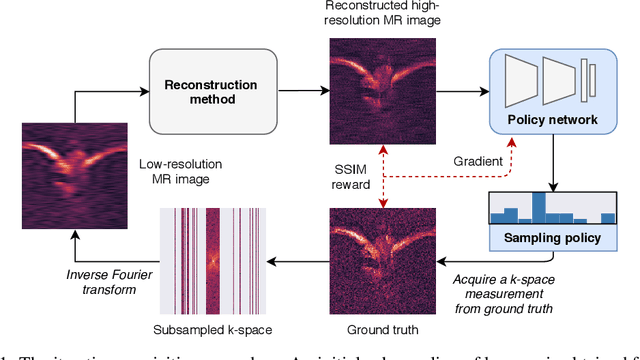
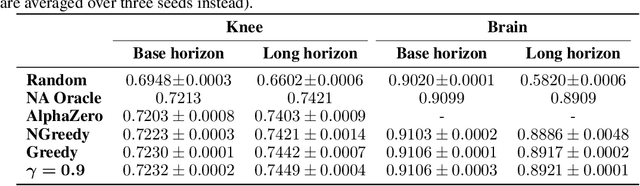
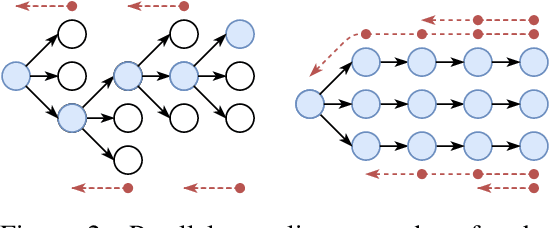
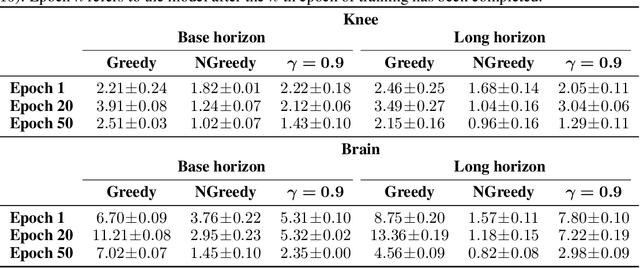
In today's clinical practice, magnetic resonance imaging (MRI) is routinely accelerated through subsampling of the associated Fourier domain. Currently, the construction of these subsampling strategies - known as experimental design - relies primarily on heuristics. We propose to learn experimental design strategies for accelerated MRI with policy gradient methods. Unexpectedly, our experiments show that a simple greedy approximation of the objective leads to solutions nearly on-par with the more general non-greedy approach. We offer a partial explanation for this phenomenon rooted in greater variance in the non-greedy objective's gradient estimates, and experimentally verify that this variance hampers non-greedy models in adapting their policies to individual MR images. We empirically show that this adaptivity is key to improving subsampling designs.