 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to Basics: Deep Reinforcement Learning in Traffic Signal Control
Paper and Code
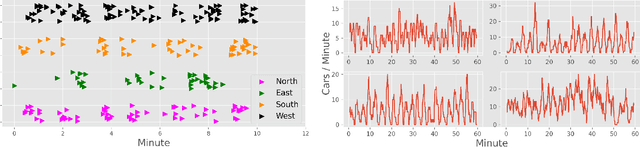
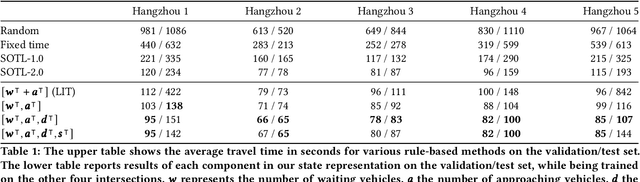
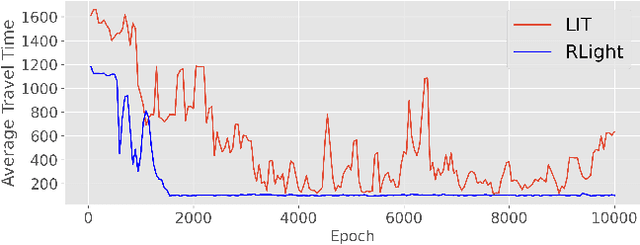
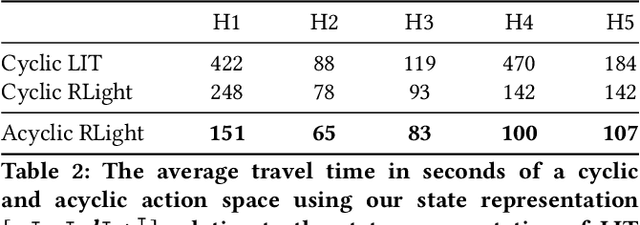
In this paper we revisit some of the fundamental premises for a reinforcement learning (RL) approach to self-learning traffic lights. We propose RLight, a combination of choices that offers robust performance and good generalization to unseen traffic flows. In particular, our main contributions are threefold: our lightweight and cluster-aware state representation leads to improved performance; we reformulate the MDP such that it skips redundant timesteps of yellow light, speeding up learning by 30%; and we investigate the action space and provide insight into the difference in performance between acyclic and cyclic phase transitions. Additionally, we provide insights into the generalisation of the methods to unseen traffic. Evaluations using the real-world Hangzhou traffic dataset show that RLight outperforms state-of-the-art rule-based and deep reinforcement learning algorithms, demonstrating the potential of RL-based methods to improve urban traffic flows.