 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetermining Accessible Sidewalk Width by Extracting Obstacle Information from Point Clouds
Nov 08, 2022Obstacles on the sidewalk often block the path, limiting passage and resulting in frustration and wasted time, especially for citizens and visitors who use assistive devices (wheelchairs, walkers, strollers, canes, etc). To enable equal participation and use of the city, all citizens should be able to perform and complete their daily activities in a similar amount of time and effort. Therefore, we aim to offer accessibility information regarding sidewalks, so that citizens can better plan their routes, and to help city officials identify the location of bottlenecks and act on them. In this paper we propose a novel pipeline to estimate obstacle-free sidewalk widths based on 3D point cloud data of the city of Amsterdam, as the first step to offer a more complete set of information regarding sidewalk accessibility.
Back to Basics: Deep Reinforcement Learning in Traffic Signal Control
Sep 15, 2021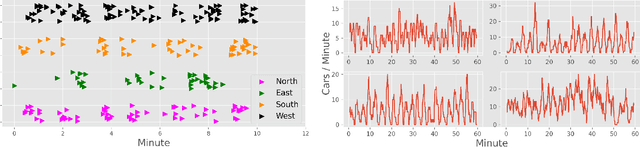
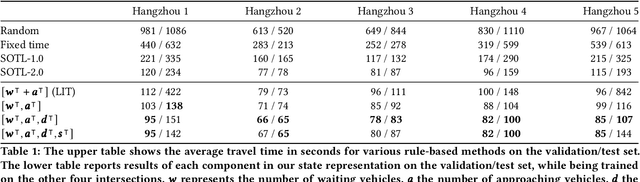
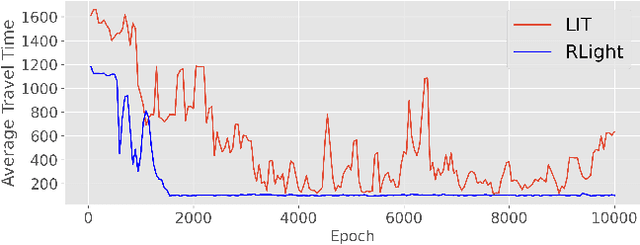
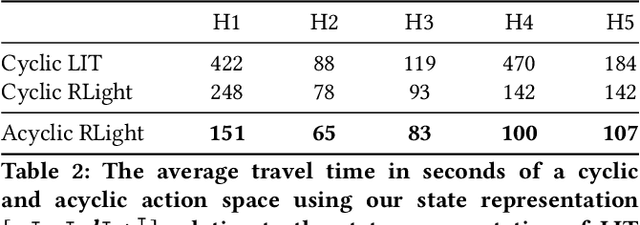
In this paper we revisit some of the fundamental premises for a reinforcement learning (RL) approach to self-learning traffic lights. We propose RLight, a combination of choices that offers robust performance and good generalization to unseen traffic flows. In particular, our main contributions are threefold: our lightweight and cluster-aware state representation leads to improved performance; we reformulate the MDP such that it skips redundant timesteps of yellow light, speeding up learning by 30%; and we investigate the action space and provide insight into the difference in performance between acyclic and cyclic phase transitions. Additionally, we provide insights into the generalisation of the methods to unseen traffic. Evaluations using the real-world Hangzhou traffic dataset show that RLight outperforms state-of-the-art rule-based and deep reinforcement learning algorithms, demonstrating the potential of RL-based methods to improve urban traffic flows.
Automatic labelling of urban point clouds using data fusion
Aug 31, 2021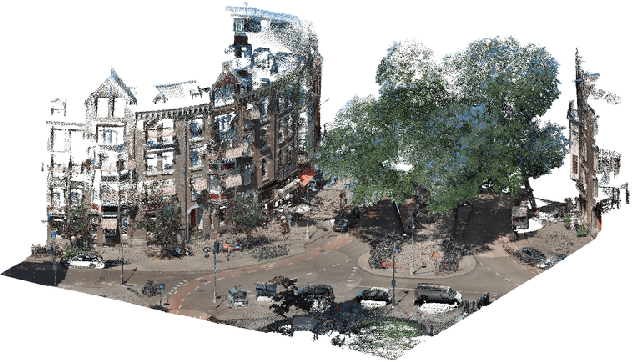

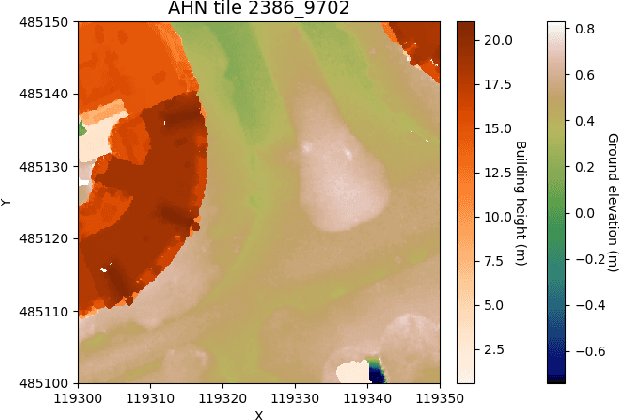
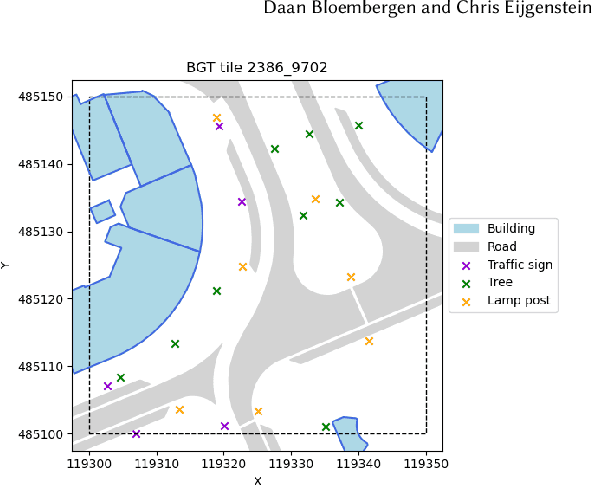
In this paper we describe an approach to semi-automatically create a labelled dataset for semantic segmentation of urban street-level point clouds. We use data fusion techniques using public data sources such as elevation data and large-scale topographical maps to automatically label parts of the point cloud, after which only limited human effort is needed to check the results and make amendments where needed. This drastically limits the time needed to create a labelled dataset that is extensive enough to train deep semantic segmentation models. We apply our method to point clouds of the Amsterdam region, and successfully train a RandLA-Net semantic segmentation model on the labelled dataset. These results demonstrate the potential of smart data fusion and semantic segmentation for the future of smart city planning and management.
Robust temporal difference learning for critical domains
Jan 23, 2019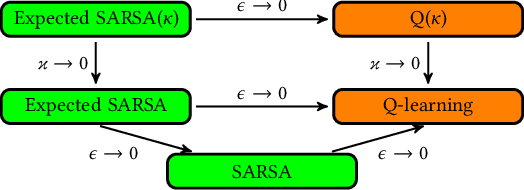

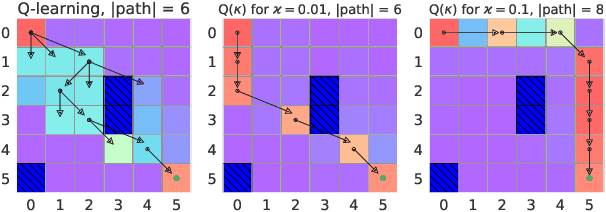
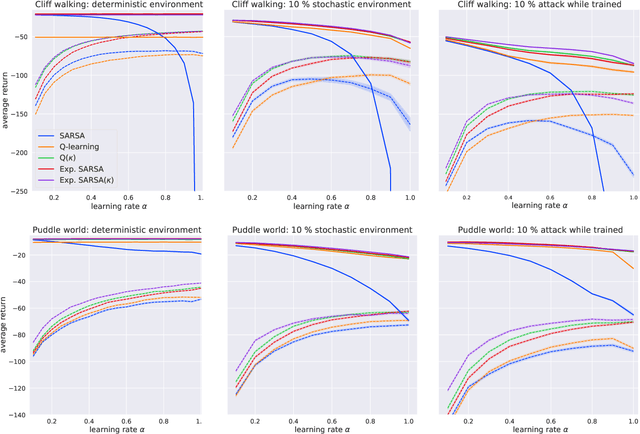
We present a new Q-function operator for temporal difference (TD) learning methods that explicitly encodes robustness against significant rare events (SRE) in critical domains. The operator, which we call the $\kappa$-operator, allows to learn a safe policy in a model-based fashion without actually observing the SRE. We introduce single- and multi-agent robust TD methods using the operator $\kappa$. We prove convergence of the operator to the optimal safe Q-function with respect to the model using the theory of Generalized Markov Decision Processes. In addition we prove convergence to the optimal Q-function of the original MDP given that the probability of SREs vanishes. Empirical evaluations demonstrate the superior performance of $\kappa$-based TD methods both in the early learning phase as well as in the final converged stage. In addition we show robustness of the proposed method to small model errors, as well as its applicability in a multi-agent context.
Lenient Multi-Agent Deep Reinforcement Learning
Feb 27, 2018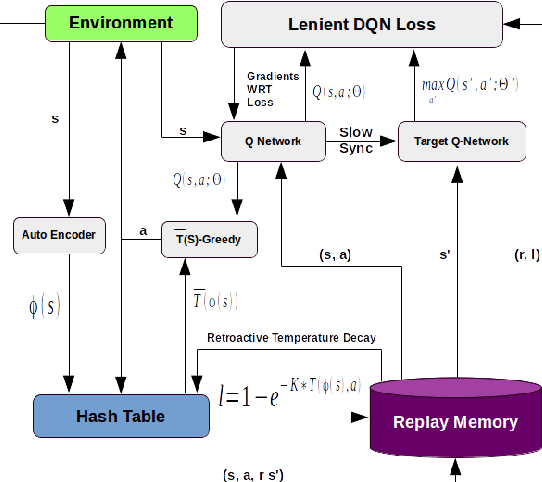
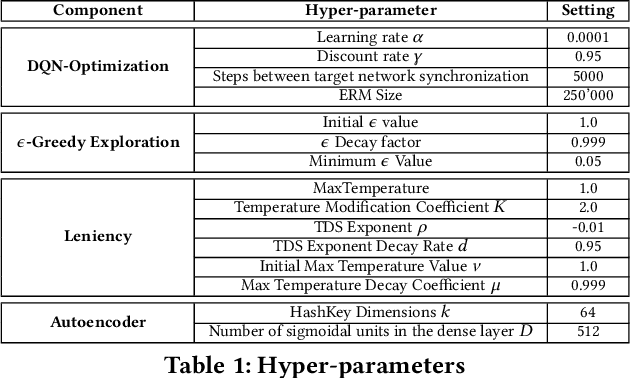


Much of the success of single agent deep reinforcement learning (DRL) in recent years can be attributed to the use of experience replay memories (ERM), which allow Deep Q-Networks (DQNs) to be trained efficiently through sampling stored state transitions. However, care is required when using ERMs for multi-agent deep reinforcement learning (MA-DRL), as stored transitions can become outdated because agents update their policies in parallel [11]. In this work we apply leniency [23] to MA-DRL. Lenient agents map state-action pairs to decaying temperature values that control the amount of leniency applied towards negative policy updates that are sampled from the ERM. This introduces optimism in the value-function update, and has been shown to facilitate cooperation in tabular fully-cooperative multi-agent reinforcement learning problems. We evaluate our Lenient-DQN (LDQN) empirically against the related Hysteretic-DQN (HDQN) algorithm [22] as well as a modified version we call scheduled-HDQN, that uses average reward learning near terminal states. Evaluations take place in extended variations of the Coordinated Multi-Agent Object Transportation Problem (CMOTP) [8] which include fully-cooperative sub-tasks and stochastic rewards. We find that LDQN agents are more likely to converge to the optimal policy in a stochastic reward CMOTP compared to standard and scheduled-HDQN agents.