 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust temporal difference learning for critical domains
Paper and Code
Jan 23, 2019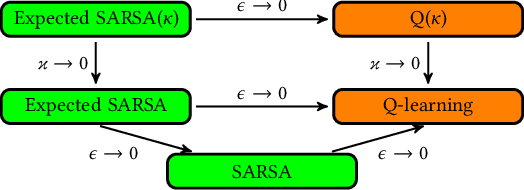

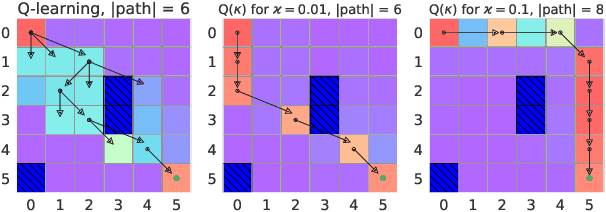
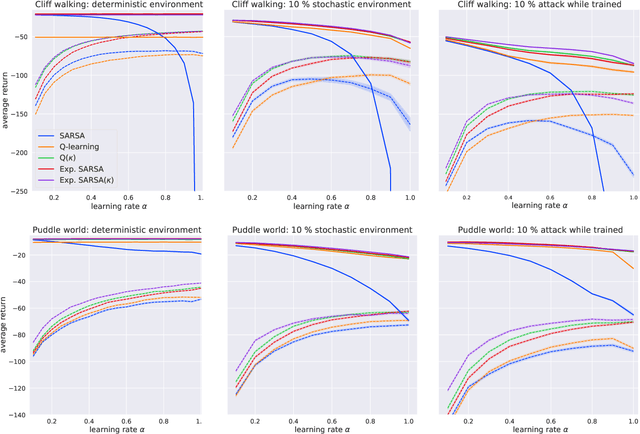
We present a new Q-function operator for temporal difference (TD) learning methods that explicitly encodes robustness against significant rare events (SRE) in critical domains. The operator, which we call the $\kappa$-operator, allows to learn a safe policy in a model-based fashion without actually observing the SRE. We introduce single- and multi-agent robust TD methods using the operator $\kappa$. We prove convergence of the operator to the optimal safe Q-function with respect to the model using the theory of Generalized Markov Decision Processes. In addition we prove convergence to the optimal Q-function of the original MDP given that the probability of SREs vanishes. Empirical evaluations demonstrate the superior performance of $\kappa$-based TD methods both in the early learning phase as well as in the final converged stage. In addition we show robustness of the proposed method to small model errors, as well as its applicability in a multi-agent context.