 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic labelling of urban point clouds using data fusion
Paper and Code
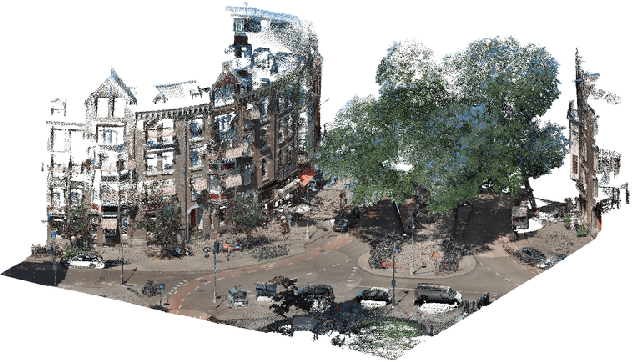

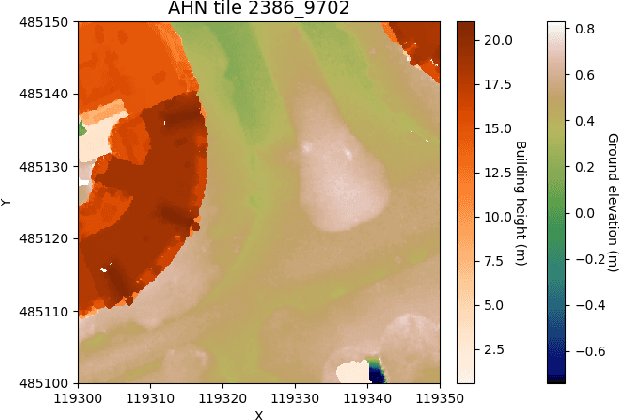
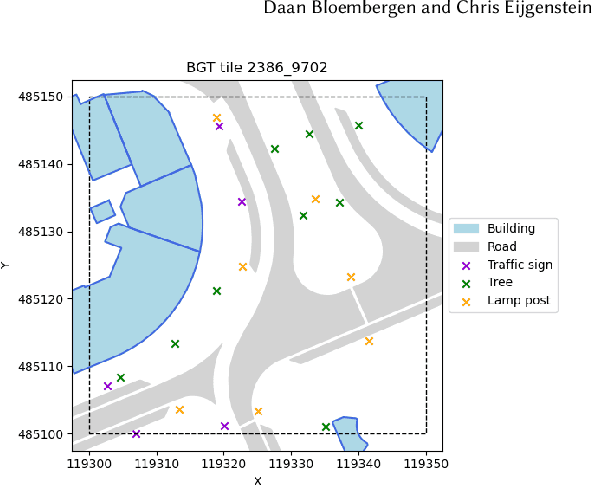
In this paper we describe an approach to semi-automatically create a labelled dataset for semantic segmentation of urban street-level point clouds. We use data fusion techniques using public data sources such as elevation data and large-scale topographical maps to automatically label parts of the point cloud, after which only limited human effort is needed to check the results and make amendments where needed. This drastically limits the time needed to create a labelled dataset that is extensive enough to train deep semantic segmentation models. We apply our method to point clouds of the Amsterdam region, and successfully train a RandLA-Net semantic segmentation model on the labelled dataset. These results demonstrate the potential of smart data fusion and semantic segmentation for the future of smart city planning and management.