 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulating, Fast and Slow: Learning Policies for Black-Box Optimization
Paper and Code
Jun 06, 2024
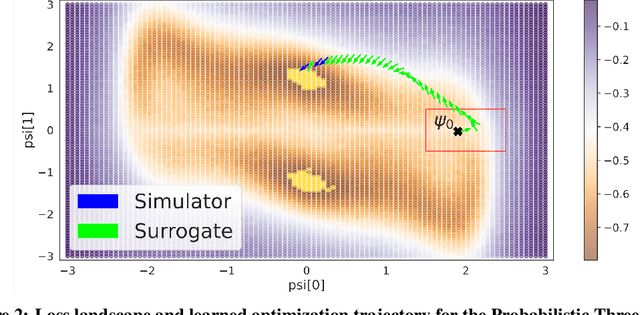
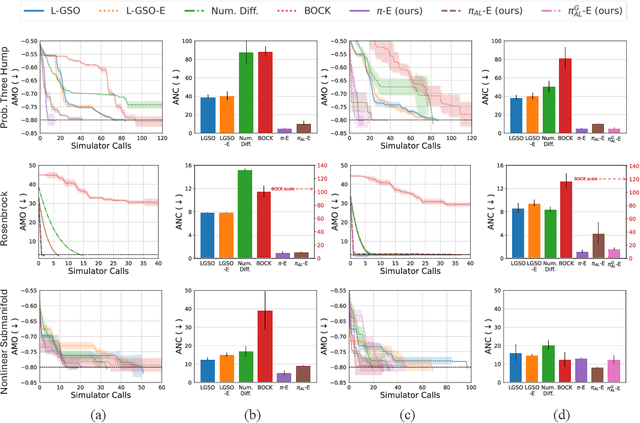
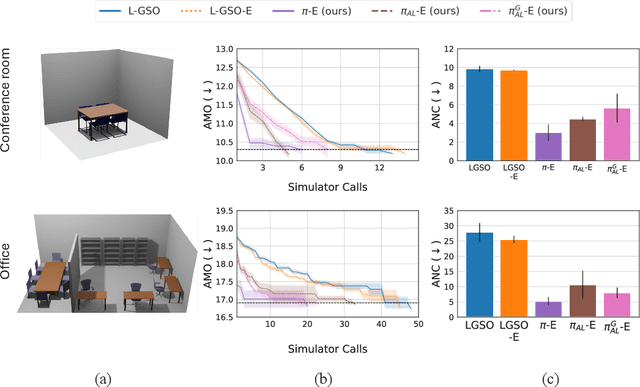
In recent years, solving optimization problems involving black-box simulators has become a point of focus for the machine learning community due to their ubiquity in science and engineering. The simulators describe a forward process $f_{\mathrm{sim}}: (\psi, x) \rightarrow y$ from simulation parameters $\psi$ and input data $x$ to observations $y$, and the goal of the optimization problem is to find parameters $\psi$ that minimize a desired loss function. Sophisticated optimization algorithms typically require gradient information regarding the forward process, $f_{\mathrm{sim}}$, with respect to the parameters $\psi$. However, obtaining gradients from black-box simulators can often be prohibitively expensive or, in some cases, impossible. Furthermore, in many applications, practitioners aim to solve a set of related problems. Thus, starting the optimization ``ab initio", i.e. from scratch, each time might be inefficient if the forward model is expensive to evaluate. To address those challenges, this paper introduces a novel method for solving classes of similar black-box optimization problems by learning an active learning policy that guides a differentiable surrogate's training and uses the surrogate's gradients to optimize the simulation parameters with gradient descent. After training the policy, downstream optimization of problems involving black-box simulators requires up to $\sim$90\% fewer expensive simulator calls compared to baselines such as local surrogate-based approaches, numerical optimization, and Bayesian methods.