 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaneRoPE: Positional Encoding for Collaborative Parallel Reasoning and Generation
May 26, 2026Parallel LLM test-time scaling techniques (e.g., best-of-$N$) require drawing $N>1$ sequences conditioned on the same input prompt. These methods boost accuracy while exploiting the computational efficiency of batching $N$ generations. However, each sequence in the batch is traditionally generated independently and hence does not reuse intermediate generations, computations, or observations from other sequences. In this paper, we propose LaneRoPE to enable coordination and collaboration among $N>1$ sequences at generation time. LaneRoPE involves two key ideas: (a) an inter-sequence attention mask to make sampling of sequences dependent on one another; and (b) a RoPE extension that injects positional information that captures relative positions between tokens, both within and outside a particular sequence. We evaluate our approach on mathematical reasoning tasks and find promising results: LaneRoPE enables collaboration among sequences, yielding additional accuracy gains under limited generated sequence length. Importantly, since LaneRoPE enables coordination with minimal changes to the underlying LLM architecture and introduces a negligible overhead at inference time, it is appealing to rapidly incorporate parallel reasoning into existing LLM inference pipelines.
Efficient Reasoning on the Edge
Mar 17, 2026Large language models (LLMs) with chain-of-thought reasoning achieve state-of-the-art performance across complex problem-solving tasks, but their verbose reasoning traces and large context requirements make them impractical for edge deployment. These challenges include high token generation costs, large KV-cache footprints, and inefficiencies when distilling reasoning capabilities into smaller models for mobile devices. Existing approaches often rely on distilling reasoning traces from larger models into smaller models, which are verbose and stylistically redundant, undesirable for on-device inference. In this work, we propose a lightweight approach to enable reasoning in small LLMs using LoRA adapters combined with supervised fine-tuning. We further introduce budget forcing via reinforcement learning on these adapters, significantly reducing response length with minimal accuracy loss. To address memory-bound decoding, we exploit parallel test-time scaling, improving accuracy at minor latency increase. Finally, we present a dynamic adapter-switching mechanism that activates reasoning only when needed and a KV-cache sharing strategy during prompt encoding, reducing time-to-first-token for on-device inference. Experiments on Qwen2.5-7B demonstrate that our method achieves efficient, accurate reasoning under strict resource constraints, making LLM reasoning practical for mobile scenarios. Videos demonstrating our solution running on mobile devices are available on our project page.
LUMINA: Long-horizon Understanding for Multi-turn Interactive Agents
Jan 23, 2026Large language models can perform well on many isolated tasks, yet they continue to struggle on multi-turn, long-horizon agentic problems that require skills such as planning, state tracking, and long context processing. In this work, we aim to better understand the relative importance of advancing these underlying capabilities for success on such tasks. We develop an oracle counterfactual framework for multi-turn problems that asks: how would an agent perform if it could leverage an oracle to perfectly perform a specific task? The change in the agent's performance due to this oracle assistance allows us to measure the criticality of such oracle skill in the future advancement of AI agents. We introduce a suite of procedurally generated, game-like tasks with tunable complexity. These controlled environments allow us to provide precise oracle interventions, such as perfect planning or flawless state tracking, and make it possible to isolate the contribution of each oracle without confounding effects present in real-world benchmarks. Our results show that while some interventions (e.g., planning) consistently improve performance across settings, the usefulness of other skills is dependent on the properties of the environment and language model. Our work sheds light on the challenges of multi-turn agentic environments to guide the future efforts in the development of AI agents and language models.
Reinforcement Learning of Adaptive Acquisition Policies for Inverse Problems
Jul 10, 2024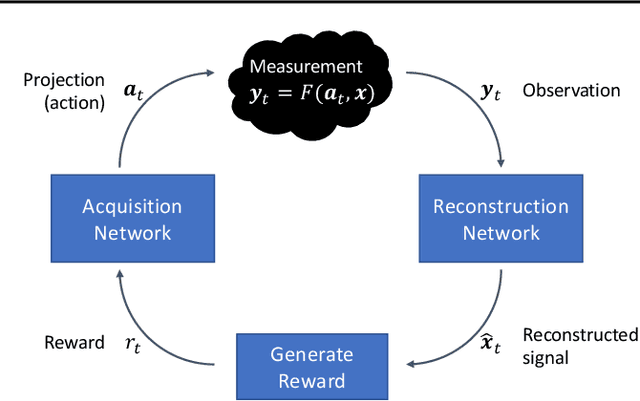

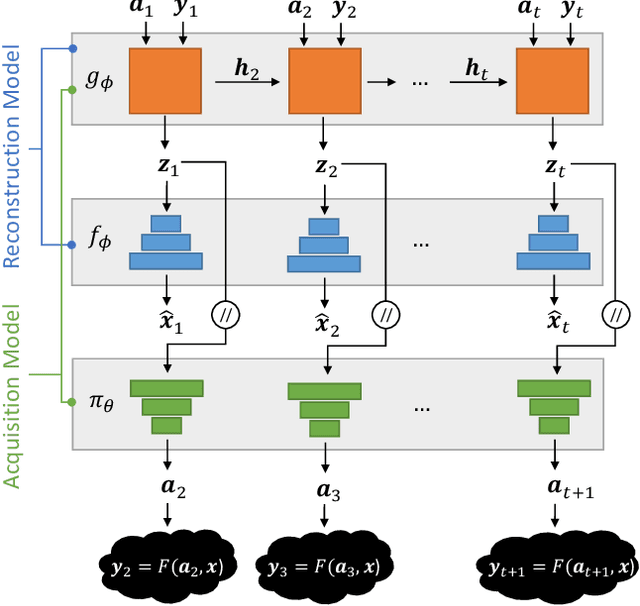

A promising way to mitigate the expensive process of obtaining a high-dimensional signal is to acquire a limited number of low-dimensional measurements and solve an under-determined inverse problem by utilizing the structural prior about the signal. In this paper, we focus on adaptive acquisition schemes to save further the number of measurements. To this end, we propose a reinforcement learning-based approach that sequentially collects measurements to better recover the underlying signal by acquiring fewer measurements. Our approach applies to general inverse problems with continuous action spaces and jointly learns the recovery algorithm. Using insights obtained from theoretical analysis, we also provide a probabilistic design for our methods using variational formulation. We evaluate our approach on multiple datasets and with two measurement spaces (Gaussian, Radon). Our results confirm the benefits of adaptive strategies in low-acquisition horizon settings.
Probabilistic and Differentiable Wireless Simulation with Geometric Transformers
Jun 21, 2024



Modelling the propagation of electromagnetic signals is critical for designing modern communication systems. While there are precise simulators based on ray tracing, they do not lend themselves to solving inverse problems or the integration in an automated design loop. We propose to address these challenges through differentiable neural surrogates that exploit the geometric aspects of the problem. We first introduce the Wireless Geometric Algebra Transformer (Wi-GATr), a generic backbone architecture for simulating wireless propagation in a 3D environment. It uses versatile representations based on geometric algebra and is equivariant with respect to E(3), the symmetry group of the underlying physics. Second, we study two algorithmic approaches to signal prediction and inverse problems based on differentiable predictive modelling and diffusion models. We show how these let us predict received power, localize receivers, and reconstruct the 3D environment from the received signal. Finally, we introduce two large, geometry-focused datasets of wireless signal propagation in indoor scenes. In experiments, we show that our geometry-forward approach achieves higher-fidelity predictions with less data than various baselines.
Simulating, Fast and Slow: Learning Policies for Black-Box Optimization
Jun 06, 2024
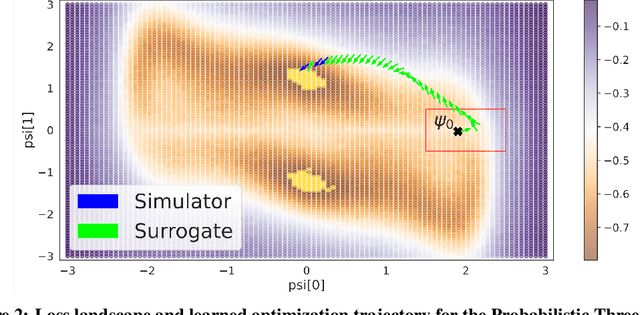
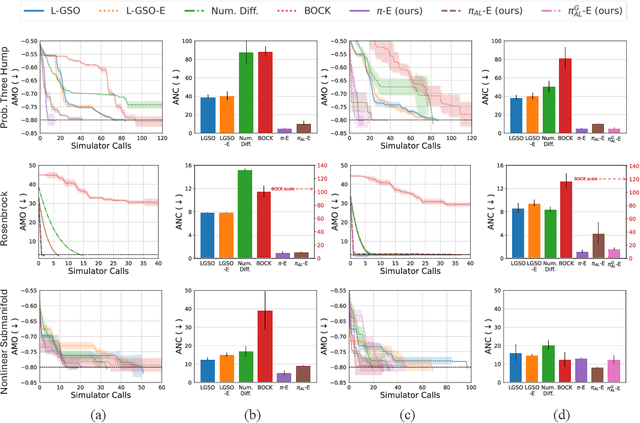
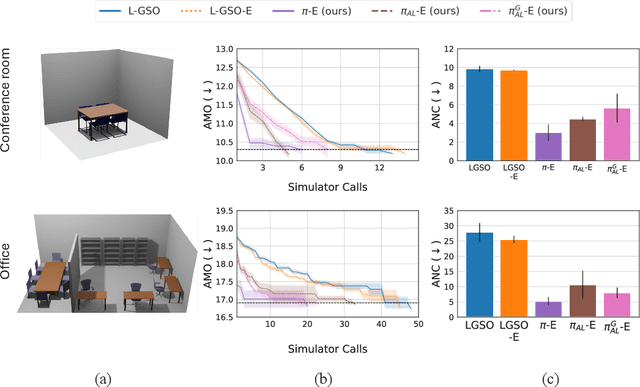
In recent years, solving optimization problems involving black-box simulators has become a point of focus for the machine learning community due to their ubiquity in science and engineering. The simulators describe a forward process $f_{\mathrm{sim}}: (\psi, x) \rightarrow y$ from simulation parameters $\psi$ and input data $x$ to observations $y$, and the goal of the optimization problem is to find parameters $\psi$ that minimize a desired loss function. Sophisticated optimization algorithms typically require gradient information regarding the forward process, $f_{\mathrm{sim}}$, with respect to the parameters $\psi$. However, obtaining gradients from black-box simulators can often be prohibitively expensive or, in some cases, impossible. Furthermore, in many applications, practitioners aim to solve a set of related problems. Thus, starting the optimization ``ab initio", i.e. from scratch, each time might be inefficient if the forward model is expensive to evaluate. To address those challenges, this paper introduces a novel method for solving classes of similar black-box optimization problems by learning an active learning policy that guides a differentiable surrogate's training and uses the surrogate's gradients to optimize the simulation parameters with gradient descent. After training the policy, downstream optimization of problems involving black-box simulators requires up to $\sim$90\% fewer expensive simulator calls compared to baselines such as local surrogate-based approaches, numerical optimization, and Bayesian methods.
Transformer-Based Neural Surrogate for Link-Level Path Loss Prediction from Variable-Sized Maps
Oct 10, 2023Estimating path loss for a transmitter-receiver location is key to many use-cases including network planning and handover. Machine learning has become a popular tool to predict wireless channel properties based on map data. In this work, we present a transformer-based neural network architecture that enables predicting link-level properties from maps of various dimensions and from sparse measurements. The map contains information about buildings and foliage. The transformer model attends to the regions that are relevant for path loss prediction and, therefore, scales efficiently to maps of different size. Further, our approach works with continuous transmitter and receiver coordinates without relying on discretization. In experiments, we show that the proposed model is able to efficiently learn dominant path losses from sparse training data and generalizes well when tested on novel maps.
MIMO-GAN: Generative MIMO Channel Modeling
Mar 16, 2022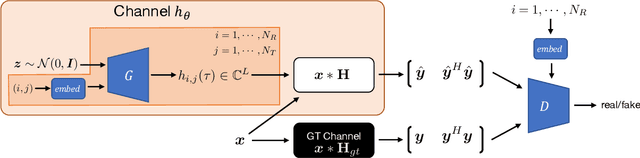
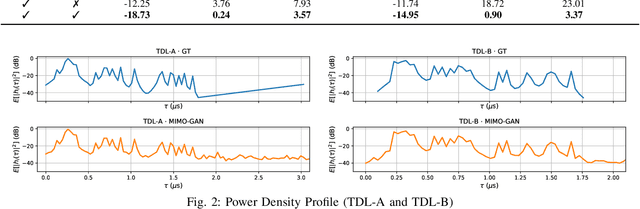
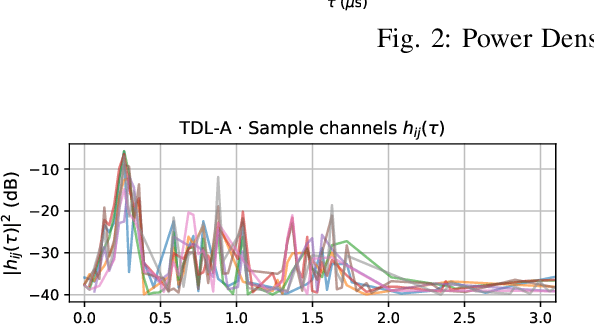
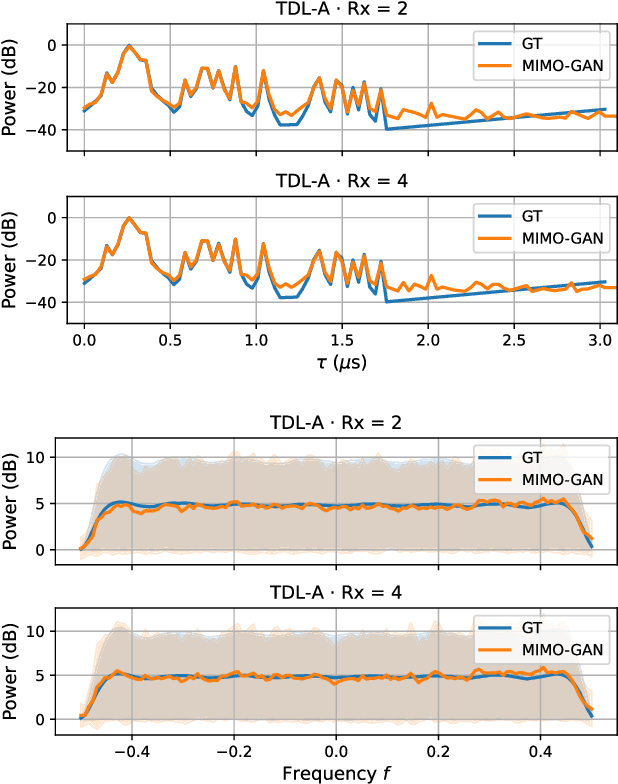
We propose generative channel modeling to learn statistical channel models from channel input-output measurements. Generative channel models can learn more complicated distributions and represent the field data more faithfully. They are tractable and easy to sample from, which can potentially speed up the simulation rounds. To achieve this, we leverage advances in GAN, which helps us learn an implicit distribution over stochastic MIMO channels from observed measurements. In particular, our approach MIMO-GAN implicitly models the wireless channel as a distribution of time-domain band-limited impulse responses. We evaluate MIMO-GAN on 3GPP TDL MIMO channels and observe high-consistency in capturing power, delay and spatial correlation statistics of the underlying channel. In particular, we observe MIMO-GAN achieve errors of under 3.57 ns average delay and -18.7 dB power.
Sampling Attacks: Amplification of Membership Inference Attacks by Repeated Queries
Sep 01, 2020
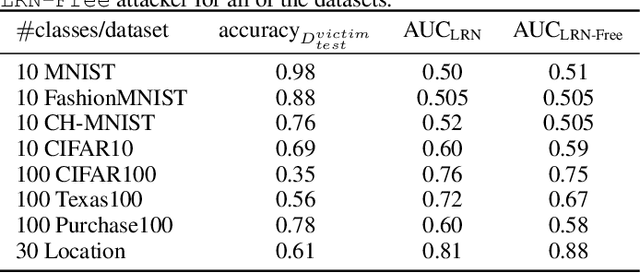
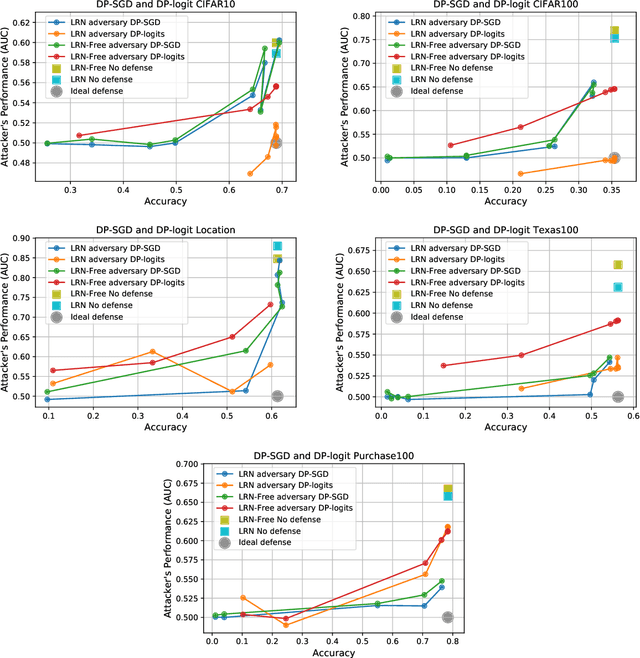
Machine learning models have been shown to leak information violating the privacy of their training set. We focus on membership inference attacks on machine learning models which aim to determine whether a data point was used to train the victim model. Our work consists of two sides: We introduce sampling attack, a novel membership inference technique that unlike other standard membership adversaries is able to work under severe restriction of no access to scores of the victim model. We show that a victim model that only publishes the labels is still susceptible to sampling attacks and the adversary can recover up to 100% of its performance compared to when posterior vectors are provided. The other sides of our work includes experimental results on two recent membership inference attack models and the defenses against them. For defense, we choose differential privacy in the form of gradient perturbation during the training of the victim model as well as output perturbation at prediction time. We carry out our experiments on a wide range of datasets which allows us to better analyze the interaction between adversaries, defense mechanism and datasets. We find out that our proposed fast and easy-to-implement output perturbation technique offers good privacy protection for membership inference attacks at little impact on utility.
GS-WGAN: A Gradient-Sanitized Approach for Learning Differentially Private Generators
Jun 15, 2020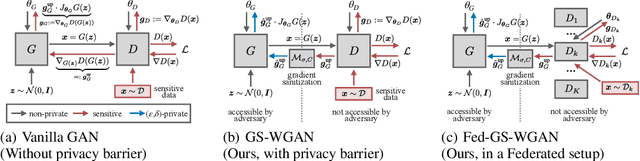
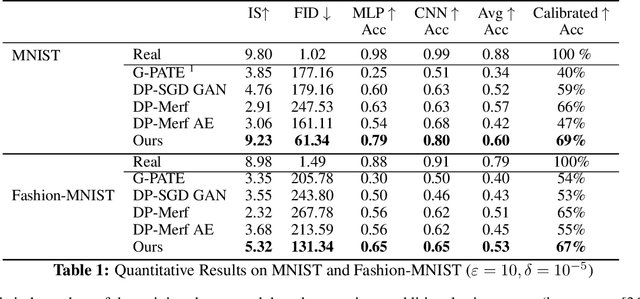

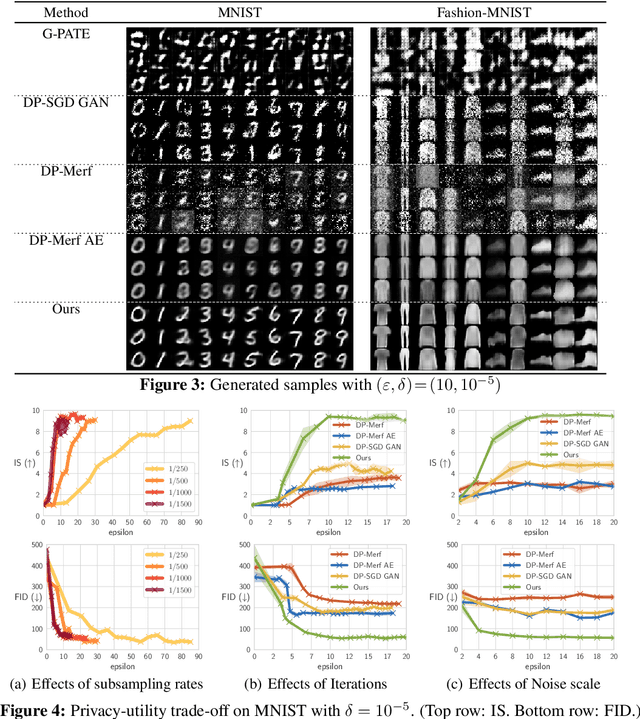
The wide-spread availability of rich data has fueled the growth of machine learning applications in numerous domains. However, growth in domains with highly-sensitive data (e.g., medical) is largely hindered as the private nature of data prohibits it from being shared. To this end, we propose Gradient-sanitized Wasserstein Generative Adversarial Networks (GS-WGAN), which allows releasing a sanitized form of the sensitive data with rigorous privacy guarantees. In contrast to prior work, our approach is able to distort gradient information more precisely, and thereby enabling training deeper models which generate more informative samples. Moreover, our formulation naturally allows for training GANs in both centralized and federated (i.e., decentralized) data scenarios. Through extensive experiments, we find our approach consistently outperforms state-of-the-art approaches across multiple metrics (e.g., sample quality) and datasets.