 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction Poisoning: Utility-Constrained Defenses Against Model Stealing Attacks
Paper and Code
Jun 26, 2019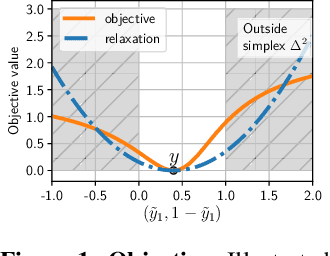
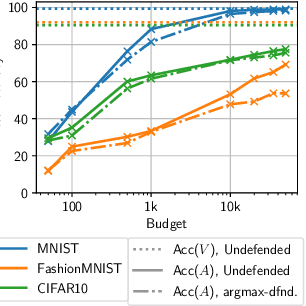
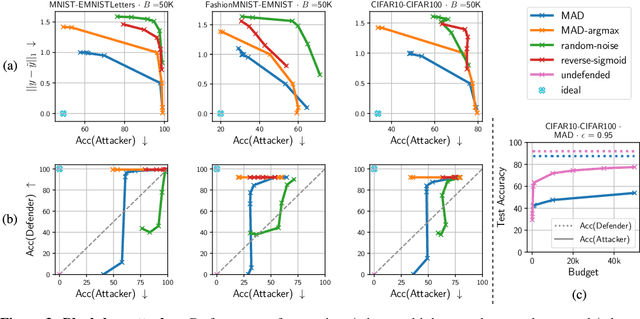
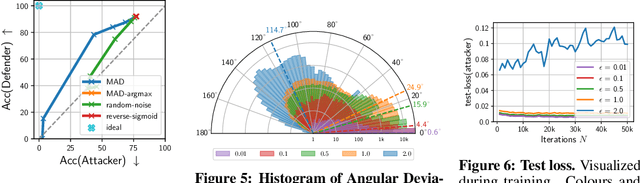
With the advances of ML models in recent years, we are seeing an increasing number of real-world commercial applications and services e.g., autonomous vehicles, medical equipment, web APIs emerge. Recent advances in model functionality stealing attacks via black-box access (i.e., inputs in, predictions out) threaten the business model of such ML applications, which require a lot of time, money, and effort to develop. In this paper, we address the issue by studying defenses for model stealing attacks, largely motivated by a lack of effective defenses in literature. We work towards the first defense which introduces targeted perturbations to the model predictions under a utility constraint. Our approach introduces the perturbations targeted towards manipulating the training procedure of the attacker. We evaluate our approach on multiple datasets and attack scenarios across a range of utility constrains. Our results show that it is indeed possible to trade-off utility (e.g., deviation from original prediction, test accuracy) to significantly reduce effectiveness of model stealing attacks.