 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Training for Vision-Language-Action Models
Oct 01, 2025Using Large Language Models to produce intermediate thoughts, a.k.a. Chain-of-thought (CoT), before providing an answer has been a successful recipe for solving complex language tasks. In robotics, similar embodied CoT strategies, generating thoughts before actions, have also been shown to lead to improved performance when using Vision-Language-Action models (VLAs). As these techniques increase the length of the model's generated outputs to include the thoughts, the inference time is negatively affected. Delaying an agent's actions in real-world executions, as in robotic manipulation settings, strongly affects the usability of a method, as tasks require long sequences of actions. However, is the generation of long chains-of-thought a strong prerequisite for achieving performance improvements? In this work, we explore the idea of Hybrid Training (HyT), a framework that enables VLAs to learn from thoughts and benefit from the associated performance gains, while enabling the possibility to leave out CoT generation during inference. Furthermore, by learning to conditionally predict a diverse set of outputs, HyT supports flexibility at inference time, enabling the model to either predict actions directly, generate thoughts or follow instructions. We evaluate the proposed method in a series of simulated benchmarks and real-world experiments.
NeuroSteiner: A Graph Transformer for Wirelength Estimation
Jul 04, 2024



A core objective of physical design is to minimize wirelength (WL) when placing chip components on a canvas. Computing the minimal WL of a placement requires finding rectilinear Steiner minimum trees (RSMTs), an NP-hard problem. We propose NeuroSteiner, a neural model that distills GeoSteiner, an optimal RSMT solver, to navigate the cost--accuracy frontier of WL estimation. NeuroSteiner is trained on synthesized nets labeled by GeoSteiner, alleviating the need to train on real chip designs. Moreover, NeuroSteiner's differentiability allows to place by minimizing WL through gradient descent. On ISPD 2005 and 2019, NeuroSteiner can obtain 0.3% WL error while being 60% faster than GeoSteiner, or 0.2% and 30%.
Probabilistic and Differentiable Wireless Simulation with Geometric Transformers
Jun 21, 2024



Modelling the propagation of electromagnetic signals is critical for designing modern communication systems. While there are precise simulators based on ray tracing, they do not lend themselves to solving inverse problems or the integration in an automated design loop. We propose to address these challenges through differentiable neural surrogates that exploit the geometric aspects of the problem. We first introduce the Wireless Geometric Algebra Transformer (Wi-GATr), a generic backbone architecture for simulating wireless propagation in a 3D environment. It uses versatile representations based on geometric algebra and is equivariant with respect to E(3), the symmetry group of the underlying physics. Second, we study two algorithmic approaches to signal prediction and inverse problems based on differentiable predictive modelling and diffusion models. We show how these let us predict received power, localize receivers, and reconstruct the 3D environment from the received signal. Finally, we introduce two large, geometry-focused datasets of wireless signal propagation in indoor scenes. In experiments, we show that our geometry-forward approach achieves higher-fidelity predictions with less data than various baselines.
MORAL: Aligning AI with Human Norms through Multi-Objective Reinforced Active Learning
Dec 30, 2021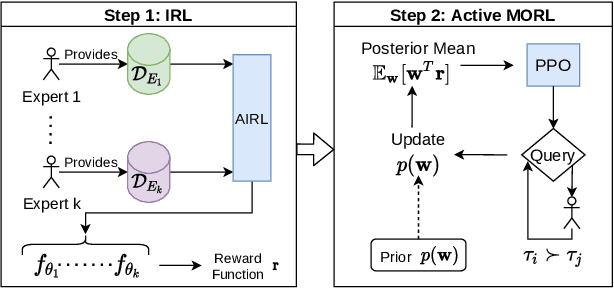


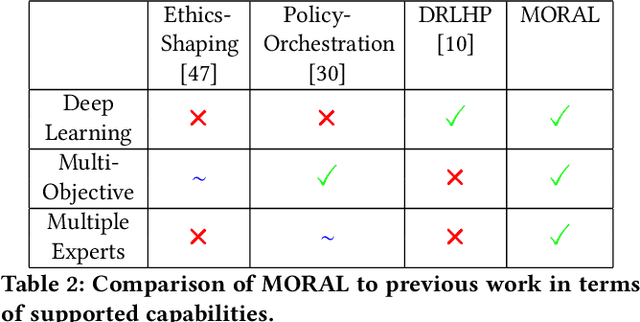
Inferring reward functions from demonstrations and pairwise preferences are auspicious approaches for aligning Reinforcement Learning (RL) agents with human intentions. However, state-of-the art methods typically focus on learning a single reward model, thus rendering it difficult to trade off different reward functions from multiple experts. We propose Multi-Objective Reinforced Active Learning (MORAL), a novel method for combining diverse demonstrations of social norms into a Pareto-optimal policy. Through maintaining a distribution over scalarization weights, our approach is able to interactively tune a deep RL agent towards a variety of preferences, while eliminating the need for computing multiple policies. We empirically demonstrate the effectiveness of MORAL in two scenarios, which model a delivery and an emergency task that require an agent to act in the presence of normative conflicts. Overall, we consider our research a step towards multi-objective RL with learned rewards, bridging the gap between current reward learning and machine ethics literature.