 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reasoning on the Edge
Mar 17, 2026Large language models (LLMs) with chain-of-thought reasoning achieve state-of-the-art performance across complex problem-solving tasks, but their verbose reasoning traces and large context requirements make them impractical for edge deployment. These challenges include high token generation costs, large KV-cache footprints, and inefficiencies when distilling reasoning capabilities into smaller models for mobile devices. Existing approaches often rely on distilling reasoning traces from larger models into smaller models, which are verbose and stylistically redundant, undesirable for on-device inference. In this work, we propose a lightweight approach to enable reasoning in small LLMs using LoRA adapters combined with supervised fine-tuning. We further introduce budget forcing via reinforcement learning on these adapters, significantly reducing response length with minimal accuracy loss. To address memory-bound decoding, we exploit parallel test-time scaling, improving accuracy at minor latency increase. Finally, we present a dynamic adapter-switching mechanism that activates reasoning only when needed and a KV-cache sharing strategy during prompt encoding, reducing time-to-first-token for on-device inference. Experiments on Qwen2.5-7B demonstrate that our method achieves efficient, accurate reasoning under strict resource constraints, making LLM reasoning practical for mobile scenarios. Videos demonstrating our solution running on mobile devices are available on our project page.
Mixture of Cache-Conditional Experts for Efficient Mobile Device Inference
Nov 27, 2024



Mixture of Experts (MoE) LLMs have recently gained attention for their ability to enhance performance by selectively engaging specialized subnetworks or "experts" for each input. However, deploying MoEs on memory-constrained devices remains challenging, particularly when generating tokens sequentially with a batch size of one, as opposed to typical high-throughput settings involving long sequences or large batches. In this work, we optimize MoE on memory-constrained devices where only a subset of expert weights fit in DRAM. We introduce a novel cache-aware routing strategy that leverages expert reuse during token generation to improve cache locality. We evaluate our approach on language modeling, MMLU, and GSM8K benchmarks and present on-device results demonstrating 2$\times$ speedups on mobile devices, offering a flexible, training-free solution to extend MoE's applicability across real-world applications.
NeuroSteiner: A Graph Transformer for Wirelength Estimation
Jul 04, 2024



A core objective of physical design is to minimize wirelength (WL) when placing chip components on a canvas. Computing the minimal WL of a placement requires finding rectilinear Steiner minimum trees (RSMTs), an NP-hard problem. We propose NeuroSteiner, a neural model that distills GeoSteiner, an optimal RSMT solver, to navigate the cost--accuracy frontier of WL estimation. NeuroSteiner is trained on synthesized nets labeled by GeoSteiner, alleviating the need to train on real chip designs. Moreover, NeuroSteiner's differentiability allows to place by minimizing WL through gradient descent. On ISPD 2005 and 2019, NeuroSteiner can obtain 0.3% WL error while being 60% faster than GeoSteiner, or 0.2% and 30%.
Bayesian Optimization for Macro Placement
Jul 18, 2022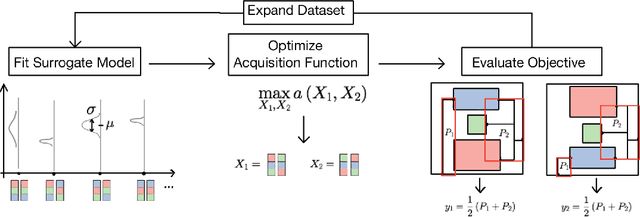
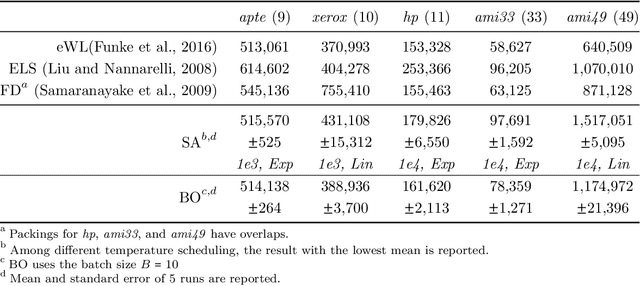
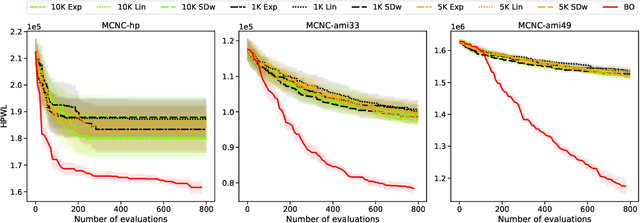

Macro placement is the problem of placing memory blocks on a chip canvas. It can be formulated as a combinatorial optimization problem over sequence pairs, a representation which describes the relative positions of macros. Solving this problem is particularly challenging since the objective function is expensive to evaluate. In this paper, we develop a novel approach to macro placement using Bayesian optimization (BO) over sequence pairs. BO is a machine learning technique that uses a probabilistic surrogate model and an acquisition function that balances exploration and exploitation to efficiently optimize a black-box objective function. BO is more sample-efficient than reinforcement learning and therefore can be used with more realistic objectives. Additionally, the ability to learn from data and adapt the algorithm to the objective function makes BO an appealing alternative to other black-box optimization methods such as simulated annealing, which relies on problem-dependent heuristics and parameter-tuning. We benchmark our algorithm on the fixed-outline macro placement problem with the half-perimeter wire length objective and demonstrate competitive performance.
Simulating Execution Time of Tensor Programs using Graph Neural Networks
Apr 26, 2019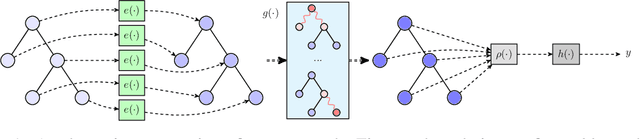
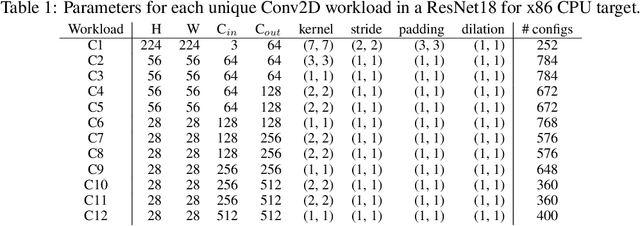
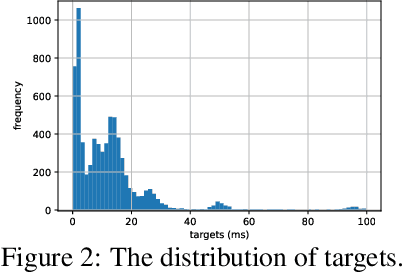

Optimizing the execution time of tensor program, e.g., a convolution, involves finding its optimal configuration. Searching the configuration space exhaustively is typically infeasible in practice. In line with recent research using TVM, we propose to learn a surrogate model to overcome this issue. The model is trained on an acyclic graph called an abstract syntax tree, and utilizes a graph convolutional network to exploit structure in the graph. We claim that a learnable graph-based data processing is a strong competitor to heuristic-based feature extraction. We present a new dataset of graphs corresponding to configurations and their execution time for various tensor programs. We provide baselines for a runtime prediction task.