 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable 3D Placement of Objects with Scene-Aware Diffusion Models
Jun 26, 2025Image editing approaches have become more powerful and flexible with the advent of powerful text-conditioned generative models. However, placing objects in an environment with a precise location and orientation still remains a challenge, as this typically requires carefully crafted inpainting masks or prompts. In this work, we show that a carefully designed visual map, combined with coarse object masks, is sufficient for high quality object placement. We design a conditioning signal that resolves ambiguities, while being flexible enough to allow for changing of shapes or object orientations. By building on an inpainting model, we leave the background intact by design, in contrast to methods that model objects and background jointly. We demonstrate the effectiveness of our method in the automotive setting, where we compare different conditioning signals in novel object placement tasks. These tasks are designed to measure edit quality not only in terms of appearance, but also in terms of pose and location accuracy, including cases that require non-trivial shape changes. Lastly, we show that fine location control can be combined with appearance control to place existing objects in precise locations in a scene.
Gaussian Splatting is an Effective Data Generator for 3D Object Detection
Apr 23, 2025



We investigate data augmentation for 3D object detection in autonomous driving. We utilize recent advancements in 3D reconstruction based on Gaussian Splatting for 3D object placement in driving scenes. Unlike existing diffusion-based methods that synthesize images conditioned on BEV layouts, our approach places 3D objects directly in the reconstructed 3D space with explicitly imposed geometric transformations. This ensures both the physical plausibility of object placement and highly accurate 3D pose and position annotations. Our experiments demonstrate that even by integrating a limited number of external 3D objects into real scenes, the augmented data significantly enhances 3D object detection performance and outperforms existing diffusion-based 3D augmentation for object detection. Extensive testing on the nuScenes dataset reveals that imposing high geometric diversity in object placement has a greater impact compared to the appearance diversity of objects. Additionally, we show that generating hard examples, either by maximizing detection loss or imposing high visual occlusion in camera images, does not lead to more efficient 3D data augmentation for camera-based 3D object detection in autonomous driving.
Scene-Aware Location Modeling for Data Augmentation in Automotive Object Detection
Apr 23, 2025



Generative image models are increasingly being used for training data augmentation in vision tasks. In the context of automotive object detection, methods usually focus on producing augmented frames that look as realistic as possible, for example by replacing real objects with generated ones. Others try to maximize the diversity of augmented frames, for example by pasting lots of generated objects onto existing backgrounds. Both perspectives pay little attention to the locations of objects in the scene. Frame layouts are either reused with little or no modification, or they are random and disregard realism entirely. In this work, we argue that optimal data augmentation should also include realistic augmentation of layouts. We introduce a scene-aware probabilistic location model that predicts where new objects can realistically be placed in an existing scene. By then inpainting objects in these locations with a generative model, we obtain much stronger augmentation performance than existing approaches. We set a new state of the art for generative data augmentation on two automotive object detection tasks, achieving up to $2.8\times$ higher gains than the best competing approach ($+1.4$ vs. $+0.5$ mAP boost). We also demonstrate significant improvements for instance segmentation.
Generative Location Modeling for Spatially Aware Object Insertion
Oct 17, 2024



Generative models have become a powerful tool for image editing tasks, including object insertion. However, these methods often lack spatial awareness, generating objects with unrealistic locations and scales, or unintentionally altering the scene background. A key challenge lies in maintaining visual coherence, which requires both a geometrically suitable object location and a high-quality image edit. In this paper, we focus on the former, creating a location model dedicated to identifying realistic object locations. Specifically, we train an autoregressive model that generates bounding box coordinates, conditioned on the background image and the desired object class. This formulation allows to effectively handle sparse placement annotations and to incorporate implausible locations into a preference dataset by performing direct preference optimization. Our extensive experiments demonstrate that our generative location model, when paired with an inpainting method, substantially outperforms state-of-the-art instruction-tuned models and location modeling baselines in object insertion tasks, delivering accurate and visually coherent results.
CodeIt: Self-Improving Language Models with Prioritized Hindsight Replay
Feb 07, 2024



Large language models are increasingly solving tasks that are commonly believed to require human-level reasoning ability. However, these models still perform very poorly on benchmarks of general intelligence such as the Abstraction and Reasoning Corpus (ARC). In this paper, we approach ARC as a programming-by-examples problem, and introduce a novel and scalable method for language model self-improvement called Code Iteration (CodeIt). Our method iterates between 1) program sampling and hindsight relabeling, and 2) learning from prioritized experience replay. By relabeling the goal of an episode (i.e., the target program output given input) to the realized output produced by the sampled program, our method effectively deals with the extreme sparsity of rewards in program synthesis. Applying CodeIt to the ARC dataset, we demonstrate that prioritized hindsight replay, along with pre-training and data-augmentation, leads to successful inter-task generalization. CodeIt is the first neuro-symbolic approach that scales to the full ARC evaluation dataset. Our method solves 15% of ARC evaluation tasks, achieving state-of-the-art performance and outperforming existing neural and symbolic baselines.
MobileNVC: Real-time 1080p Neural Video Compression on a Mobile Device
Oct 02, 2023



Neural video codecs have recently become competitive with standard codecs such as HEVC in the low-delay setting. However, most neural codecs are large floating-point networks that use pixel-dense warping operations for temporal modeling, making them too computationally expensive for deployment on mobile devices. Recent work has demonstrated that running a neural decoder in real time on mobile is feasible, but shows this only for 720p RGB video, while the YUV420 format is more commonly used in production. This work presents the first neural video codec that decodes 1080p YUV420 video in real time on a mobile device. Our codec relies on two major contributions. First, we design an efficient codec that uses a block-based motion compensation algorithm available on the warping core of the mobile accelerator, and we show how to quantize this model to integer precision. Second, we implement a fast decoder pipeline that concurrently runs neural network components on the neural signal processor, parallel entropy coding on the mobile GPU, and warping on the warping core. Our codec outperforms the previous on-device codec by a large margin with up to 48 % BD-rate savings, while reducing the MAC count on the receiver side by 10x. We perform a careful ablation to demonstrate the effect of the introduced motion compensation scheme, and ablate the effect of model quantization.
Neural Image Compression with a Diffusion-Based Decoder
Jan 23, 2023



Diffusion probabilistic models have recently achieved remarkable success in generating high quality image and video data. In this work, we build on this class of generative models and introduce a method for lossy compression of high resolution images. The resulting codec, which we call DIffuson-based Residual Augmentation Codec (DIRAC),is the first neural codec to allow smooth traversal of the rate-distortion-perception tradeoff at test time, while obtaining competitive performance with GAN-based methods in perceptual quality. Furthermore, while sampling from diffusion probabilistic models is notoriously expensive, we show that in the compression setting the number of steps can be drastically reduced.
Boosting neural video codecs by exploiting hierarchical redundancy
Aug 08, 2022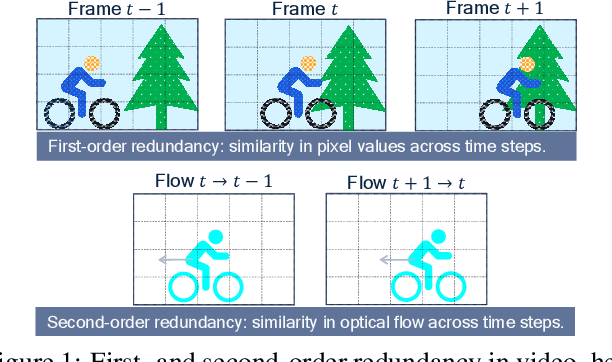
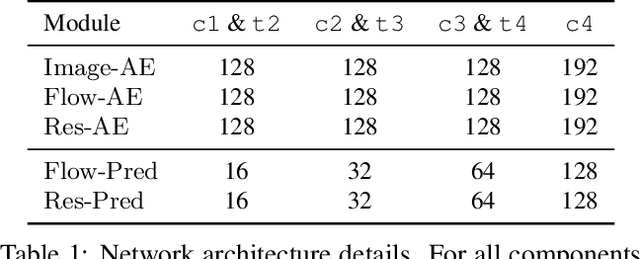
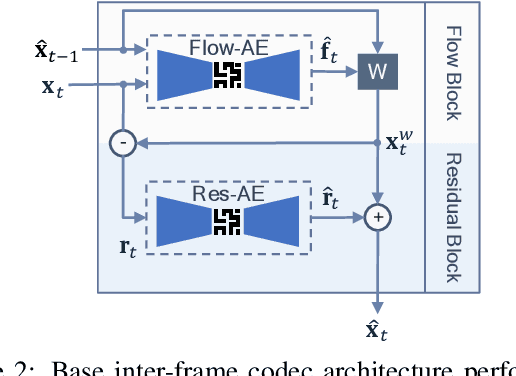
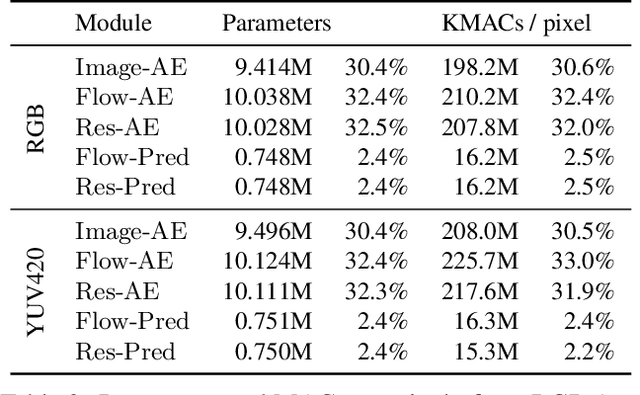
In video compression, coding efficiency is improved by reusing pixels from previously decoded frames via motion and residual compensation. We define two levels of hierarchical redundancy in video frames: 1) first-order: redundancy in pixel space, i.e., similarities in pixel values across neighboring frames, which is effectively captured using motion and residual compensation, 2) second-order: redundancy in motion and residual maps due to smooth motion in natural videos. While most of the existing neural video coding literature addresses first-order redundancy, we tackle the problem of capturing second-order redundancy in neural video codecs via predictors. We introduce generic motion and residual predictors that learn to extrapolate from previously decoded data. These predictors are lightweight, and can be employed with most neural video codecs in order to improve their rate-distortion performance. Moreover, while RGB is the dominant colorspace in neural video coding literature, we introduce general modifications for neural video codecs to embrace the YUV420 colorspace and report YUV420 results. Our experiments show that using our predictors with a well-known neural video codec leads to 38% and 34% bitrate savings in RGB and YUV420 colorspaces measured on the UVG dataset.
MobileCodec: Neural Inter-frame Video Compression on Mobile Devices
Jul 18, 2022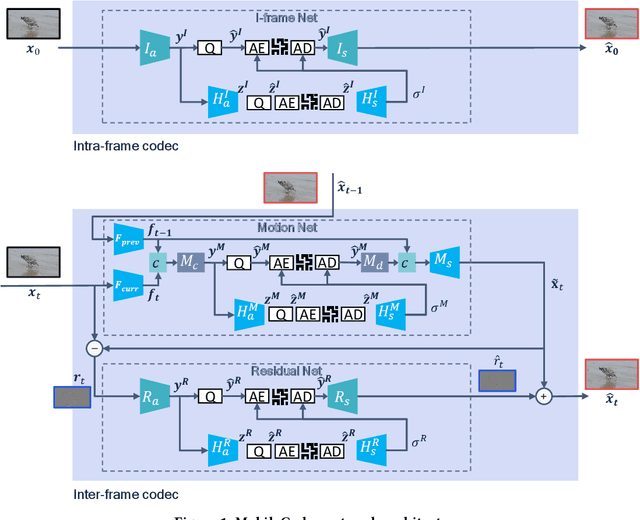
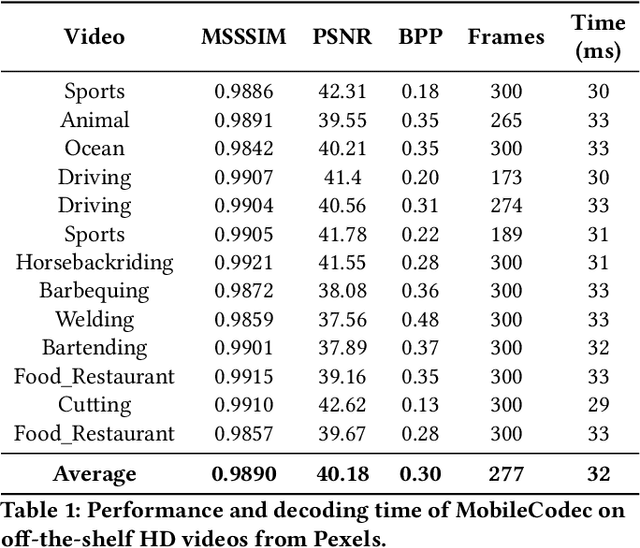
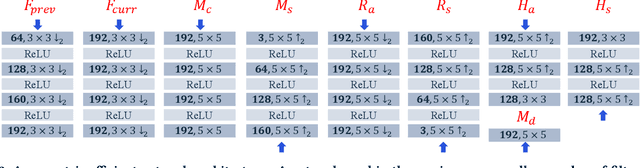
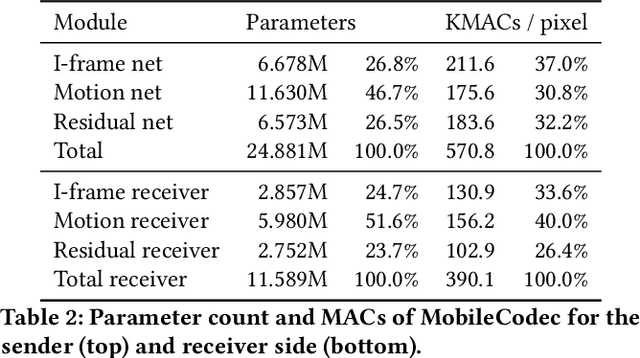
Realizing the potential of neural video codecs on mobile devices is a big technological challenge due to the computational complexity of deep networks and the power-constrained mobile hardware. We demonstrate practical feasibility by leveraging Qualcomm's technology and innovation, bridging the gap from neural network-based codec simulations running on wall-powered workstations, to real-time operation on a mobile device powered by Snapdragon technology. We show the first-ever inter-frame neural video decoder running on a commercial mobile phone, decoding high-definition videos in real-time while maintaining a low bitrate and high visual quality.
Parallelized Rate-Distortion Optimized Quantization Using Deep Learning
Dec 11, 2020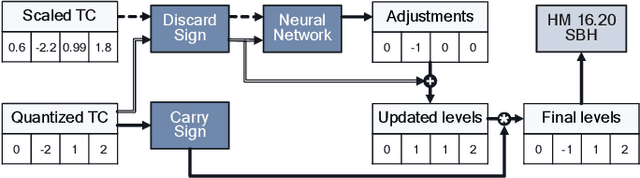
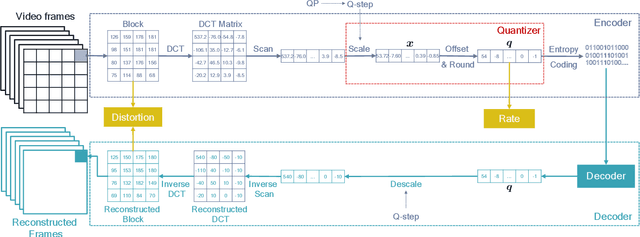
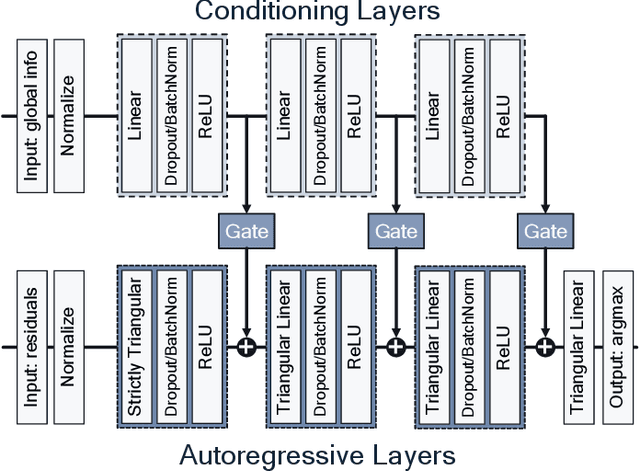
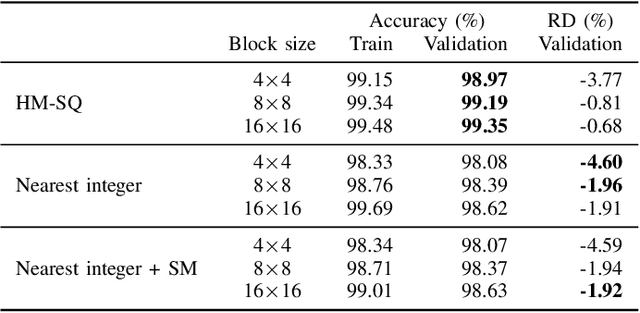
Rate-Distortion Optimized Quantization (RDOQ) has played an important role in the coding performance of recent video compression standards such as H.264/AVC, H.265/HEVC, VP9 and AV1. This scheme yields significant reductions in bit-rate at the expense of relatively small increases in distortion. Typically, RDOQ algorithms are prohibitively expensive to implement on real-time hardware encoders due to their sequential nature and their need to frequently obtain entropy coding costs. This work addresses this limitation using a neural network-based approach, which learns to trade-off rate and distortion during offline supervised training. As these networks are based solely on standard arithmetic operations that can be executed on existing neural network hardware, no additional area-on-chip needs to be reserved for dedicated RDOQ circuitry. We train two classes of neural networks, a fully-convolutional network and an auto-regressive network, and evaluate each as a post-quantization step designed to refine cheap quantization schemes such as scalar quantization (SQ). Both network architectures are designed to have a low computational overhead. After training they are integrated into the HM 16.20 implementation of HEVC, and their video coding performance is evaluated on a subset of the H.266/VVC SDR common test sequences. Comparisons are made to RDOQ and SQ implementations in HM 16.20. Our method achieves 1.64% BD-rate savings on luminosity compared to the HM SQ anchor, and on average reaches 45% of the performance of the iterative HM RDOQ algorithm.