 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable 3D Placement of Objects with Scene-Aware Diffusion Models
Jun 26, 2025Image editing approaches have become more powerful and flexible with the advent of powerful text-conditioned generative models. However, placing objects in an environment with a precise location and orientation still remains a challenge, as this typically requires carefully crafted inpainting masks or prompts. In this work, we show that a carefully designed visual map, combined with coarse object masks, is sufficient for high quality object placement. We design a conditioning signal that resolves ambiguities, while being flexible enough to allow for changing of shapes or object orientations. By building on an inpainting model, we leave the background intact by design, in contrast to methods that model objects and background jointly. We demonstrate the effectiveness of our method in the automotive setting, where we compare different conditioning signals in novel object placement tasks. These tasks are designed to measure edit quality not only in terms of appearance, but also in terms of pose and location accuracy, including cases that require non-trivial shape changes. Lastly, we show that fine location control can be combined with appearance control to place existing objects in precise locations in a scene.
Generative Location Modeling for Spatially Aware Object Insertion
Oct 17, 2024



Generative models have become a powerful tool for image editing tasks, including object insertion. However, these methods often lack spatial awareness, generating objects with unrealistic locations and scales, or unintentionally altering the scene background. A key challenge lies in maintaining visual coherence, which requires both a geometrically suitable object location and a high-quality image edit. In this paper, we focus on the former, creating a location model dedicated to identifying realistic object locations. Specifically, we train an autoregressive model that generates bounding box coordinates, conditioned on the background image and the desired object class. This formulation allows to effectively handle sparse placement annotations and to incorporate implausible locations into a preference dataset by performing direct preference optimization. Our extensive experiments demonstrate that our generative location model, when paired with an inpainting method, substantially outperforms state-of-the-art instruction-tuned models and location modeling baselines in object insertion tasks, delivering accurate and visually coherent results.
Neural Body Fitting: Unifying Deep Learning and Model-Based Human Pose and Shape Estimation
Aug 17, 2018



Direct prediction of 3D body pose and shape remains a challenge even for highly parameterized deep learning models. Mapping from the 2D image space to the prediction space is difficult: perspective ambiguities make the loss function noisy and training data is scarce. In this paper, we propose a novel approach (Neural Body Fitting (NBF)). It integrates a statistical body model within a CNN, leveraging reliable bottom-up semantic body part segmentation and robust top-down body model constraints. NBF is fully differentiable and can be trained using 2D and 3D annotations. In detailed experiments, we analyze how the components of our model affect performance, especially the use of part segmentations as an explicit intermediate representation, and present a robust, efficiently trainable framework for 3D human pose estimation from 2D images with competitive results on standard benchmarks. Code will be made available at http://github.com/mohomran/neural_body_fitting
Joint Graph Decomposition and Node Labeling: Problem, Algorithms, Applications
Feb 21, 2017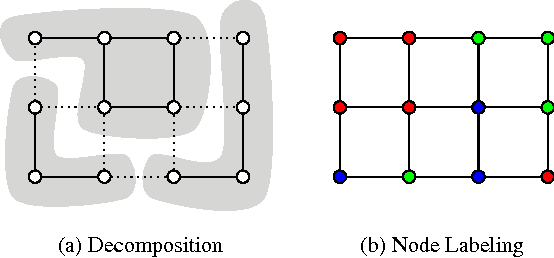
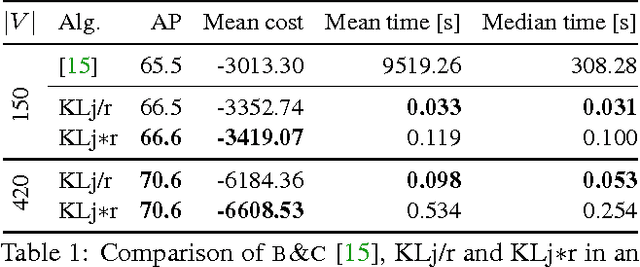
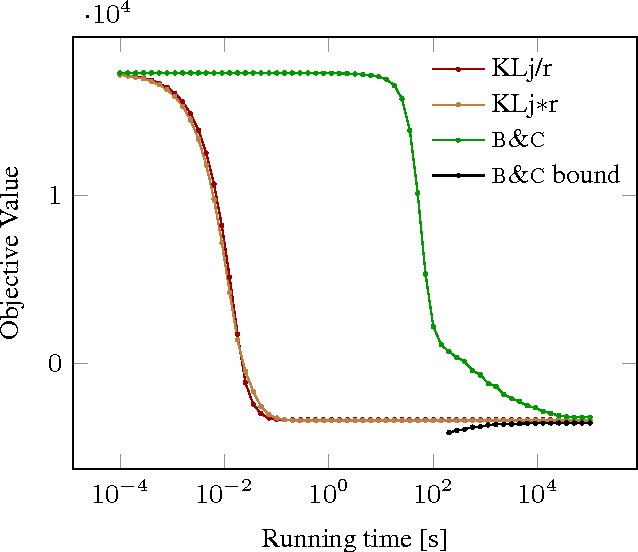
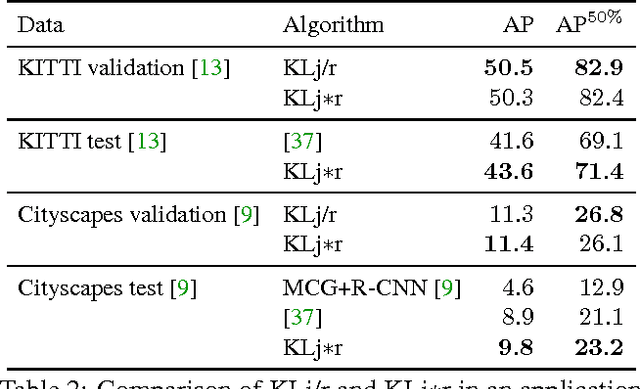
We state a combinatorial optimization problem whose feasible solutions define both a decomposition and a node labeling of a given graph. This problem offers a common mathematical abstraction of seemingly unrelated computer vision tasks, including instance-separating semantic segmentation, articulated human body pose estimation and multiple object tracking. Conceptually, the problem we state generalizes the unconstrained integer quadratic program and the minimum cost lifted multicut problem, both of which are NP-hard. In order to find feasible solutions efficiently, we define two local search algorithms that converge monotonously to a local optimum, offering a feasible solution at any time. To demonstrate their effectiveness in tackling computer vision tasks, we apply these algorithms to instances of the problem that we construct from published data, using published algorithms. We report state-of-the-art application-specific accuracy for the three above-mentioned applications.
How Far are We from Solving Pedestrian Detection?
Jun 21, 2016



Encouraged by the recent progress in pedestrian detection, we investigate the gap between current state-of-the-art methods and the "perfect single frame detector". We enable our analysis by creating a human baseline for pedestrian detection (over the Caltech dataset), and by manually clustering the recurrent errors of a top detector. Our results characterize both localization and background-versus-foreground errors. To address localization errors we study the impact of training annotation noise on the detector performance, and show that we can improve even with a small portion of sanitized training data. To address background/foreground discrimination, we study convnets for pedestrian detection, and discuss which factors affect their performance. Other than our in-depth analysis, we report top performance on the Caltech dataset, and provide a new sanitized set of training and test annotations.
The Cityscapes Dataset for Semantic Urban Scene Understanding
Apr 07, 2016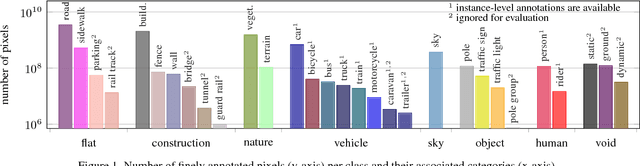

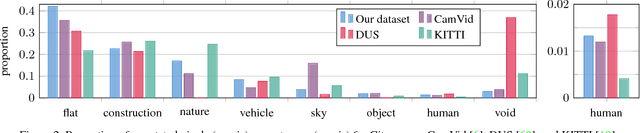
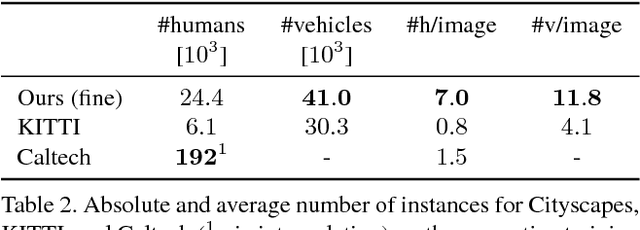
Visual understanding of complex urban street scenes is an enabling factor for a wide range of applications. Object detection has benefited enormously from large-scale datasets, especially in the context of deep learning. For semantic urban scene understanding, however, no current dataset adequately captures the complexity of real-world urban scenes. To address this, we introduce Cityscapes, a benchmark suite and large-scale dataset to train and test approaches for pixel-level and instance-level semantic labeling. Cityscapes is comprised of a large, diverse set of stereo video sequences recorded in streets from 50 different cities. 5000 of these images have high quality pixel-level annotations; 20000 additional images have coarse annotations to enable methods that leverage large volumes of weakly-labeled data. Crucially, our effort exceeds previous attempts in terms of dataset size, annotation richness, scene variability, and complexity. Our accompanying empirical study provides an in-depth analysis of the dataset characteristics, as well as a performance evaluation of several state-of-the-art approaches based on our benchmark.
Weakly Supervised Object Boundaries
Nov 24, 2015



State-of-the-art learning based boundary detection methods require extensive training data. Since labelling object boundaries is one of the most expensive types of annotations, there is a need to relax the requirement to carefully annotate images to make both the training more affordable and to extend the amount of training data. In this paper we propose a technique to generate weakly supervised annotations and show that bounding box annotations alone suffice to reach high-quality object boundaries without using any object-specific boundary annotations. With the proposed weak supervision techniques we achieve the top performance on the object boundary detection task, outperforming by a large margin the current fully supervised state-of-the-art methods.
Taking a Deeper Look at Pedestrians
Jan 23, 2015



In this paper we study the use of convolutional neural networks (convnets) for the task of pedestrian detection. Despite their recent diverse successes, convnets historically underperform compared to other pedestrian detectors. We deliberately omit explicitly modelling the problem into the network (e.g. parts or occlusion modelling) and show that we can reach competitive performance without bells and whistles. In a wide range of experiments we analyse small and big convnets, their architectural choices, parameters, and the influence of different training data, including pre-training on surrogate tasks. We present the best convnet detectors on the Caltech and KITTI dataset. On Caltech our convnets reach top performance both for the Caltech1x and Caltech10x training setup. Using additional data at training time our strongest convnet model is competitive even to detectors that use additional data (optical flow) at test time.
Ten Years of Pedestrian Detection, What Have We Learned?
Nov 16, 2014

Paper-by-paper results make it easy to miss the forest for the trees.We analyse the remarkable progress of the last decade by discussing the main ideas explored in the 40+ detectors currently present in the Caltech pedestrian detection benchmark. We observe that there exist three families of approaches, all currently reaching similar detection quality. Based on our analysis, we study the complementarity of the most promising ideas by combining multiple published strategies. This new decision forest detector achieves the current best known performance on the challenging Caltech-USA dataset.