 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom colouring-in to pointillism: revisiting semantic segmentation supervision
Oct 25, 2022The prevailing paradigm for producing semantic segmentation training data relies on densely labelling each pixel of each image in the training set, akin to colouring-in books. This approach becomes a bottleneck when scaling up in the number of images, classes, and annotators. Here we propose instead a pointillist approach for semantic segmentation annotation, where only point-wise yes/no questions are answered. We explore design alternatives for such an active learning approach, measure the speed and consistency of human annotators on this task, show that this strategy enables training good segmentation models, and that it is suitable for evaluating models at test time. As concrete proof of the scalability of our method, we collected and released 22.6M point labels over 4,171 classes on the Open Images dataset. Our results enable to rethink the semantic segmentation pipeline of annotation, training, and evaluation from a pointillism point of view.
Large-scale interactive object segmentation with human annotators
Apr 17, 2019



Manually annotating object segmentation masks is very time consuming. Interactive object segmentation methods offer a more efficient alternative where a human annotator and a machine segmentation model collaborate. In this paper we make several contributions to interactive segmentation: (1) we systematically explore in simulation the design space of deep interactive segmentation models and report new insights and caveats; (2) we execute a large-scale annotation campaign with real human annotators, producing masks for 2.5M instances on the OpenImages dataset. We plan to release this data publicly, forming the largest existing dataset for instance segmentation. Moreover, by re-annotating part of the COCO dataset, we show that we can produce instance masks 3 times faster than traditional polygon drawing tools while also providing better quality. (3) We present a technique for automatically estimating the quality of the produced masks which exploits indirect signals from the annotation process.
Person Recognition in Personal Photo Collections
Oct 20, 2018



People nowadays share large parts of their personal lives through social media. Being able to automatically recognise people in personal photos may greatly enhance user convenience by easing photo album organisation. For human identification task, however, traditional focus of computer vision has been face recognition and pedestrian re-identification. Person recognition in social media photos sets new challenges for computer vision, including non-cooperative subjects (e.g. backward viewpoints, unusual poses) and great changes in appearance. To tackle this problem, we build a simple person recognition framework that leverages convnet features from multiple image regions (head, body, etc.). We propose new recognition scenarios that focus on the time and appearance gap between training and testing samples. We present an in-depth analysis of the importance of different features according to time and viewpoint generalisability. In the process, we verify that our simple approach achieves the state of the art result on the PIPA benchmark, arguably the largest social media based benchmark for person recognition to date with diverse poses, viewpoints, social groups, and events. Compared the conference version of the paper, this paper additionally presents (1) analysis of a face recogniser (DeepID2+), (2) new method naeil2 that combines the conference version method naeil and DeepID2+ to achieve state of the art results even compared to post-conference works, (3) discussion of related work since the conference version, (4) additional analysis including the head viewpoint-wise breakdown of performance, and (5) results on the open-world setup.
Lucid Data Dreaming for Multiple Object Tracking
Dec 14, 2017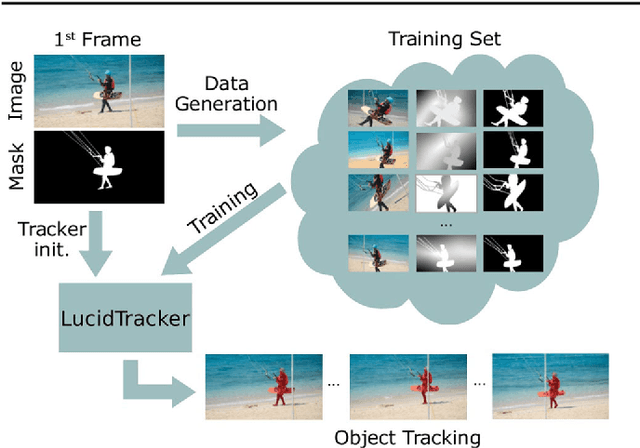



Convolutional networks reach top quality in pixel-level object tracking but require a large amount of training data (1k~10k) to deliver such results. We propose a new training strategy which achieves state-of-the-art results across three evaluation datasets while using 20x~100x less annotated data than competing methods. Our approach is suitable for both single and multiple object tracking. Instead of using large training sets hoping to generalize across domains, we generate in-domain training data using the provided annotation on the first frame of each video to synthesize ("lucid dream") plausible future video frames. In-domain per-video training data allows us to train high quality appearance- and motion-based models, as well as tune the post-processing stage. This approach allows to reach competitive results even when training from only a single annotated frame, without ImageNet pre-training. Our results indicate that using a larger training set is not automatically better, and that for the tracking task a smaller training set that is closer to the target domain is more effective. This changes the mindset regarding how many training samples and general "objectness" knowledge are required for the object tracking task.
Exploiting saliency for object segmentation from image level labels
Jul 14, 2017

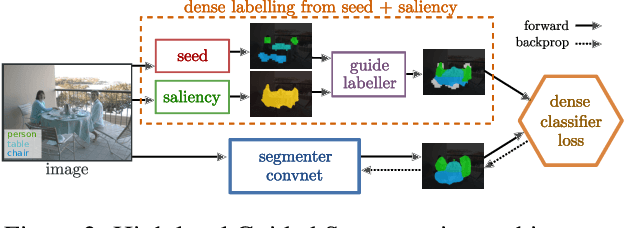

There have been remarkable improvements in the semantic labelling task in the recent years. However, the state of the art methods rely on large-scale pixel-level annotations. This paper studies the problem of training a pixel-wise semantic labeller network from image-level annotations of the present object classes. Recently, it has been shown that high quality seeds indicating discriminative object regions can be obtained from image-level labels. Without additional information, obtaining the full extent of the object is an inherently ill-posed problem due to co-occurrences. We propose using a saliency model as additional information and hereby exploit prior knowledge on the object extent and image statistics. We show how to combine both information sources in order to recover 80% of the fully supervised performance - which is the new state of the art in weakly supervised training for pixel-wise semantic labelling. The code is available at https://goo.gl/KygSeb.
Learning non-maximum suppression
May 09, 2017
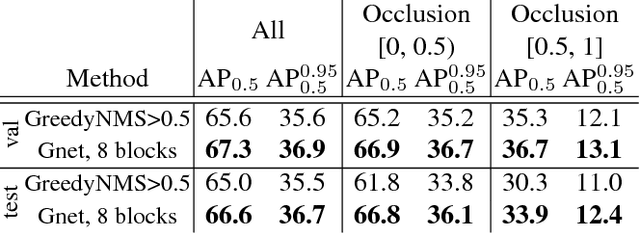
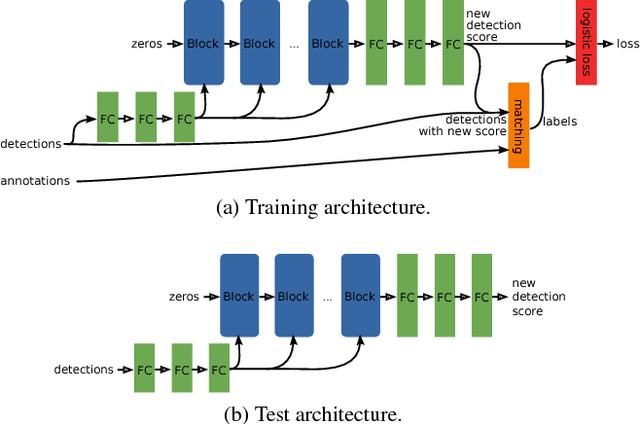
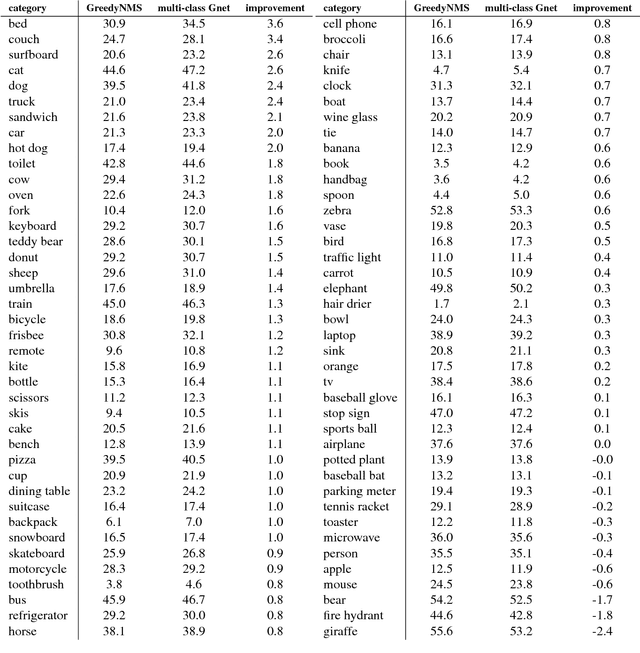
Object detectors have hugely profited from moving towards an end-to-end learning paradigm: proposals, features, and the classifier becoming one neural network improved results two-fold on general object detection. One indispensable component is non-maximum suppression (NMS), a post-processing algorithm responsible for merging all detections that belong to the same object. The de facto standard NMS algorithm is still fully hand-crafted, suspiciously simple, and -- being based on greedy clustering with a fixed distance threshold -- forces a trade-off between recall and precision. We propose a new network architecture designed to perform NMS, using only boxes and their score. We report experiments for person detection on PETS and for general object categories on the COCO dataset. Our approach shows promise providing improved localization and occlusion handling.
CityPersons: A Diverse Dataset for Pedestrian Detection
Feb 19, 2017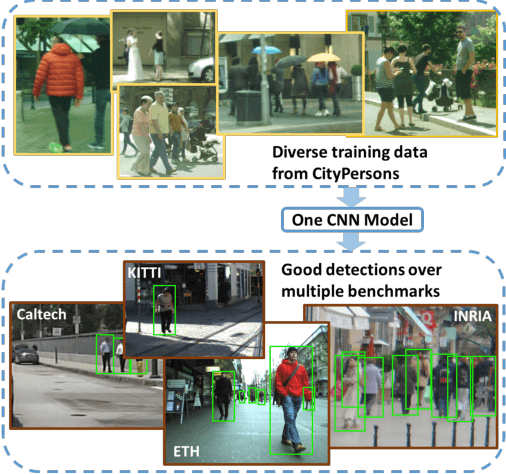


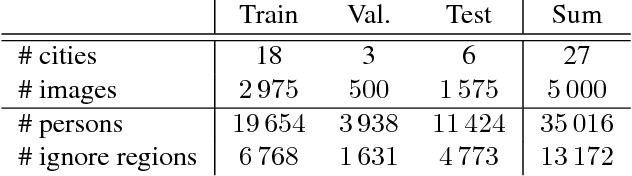
Convnets have enabled significant progress in pedestrian detection recently, but there are still open questions regarding suitable architectures and training data. We revisit CNN design and point out key adaptations, enabling plain FasterRCNN to obtain state-of-the-art results on the Caltech dataset. To achieve further improvement from more and better data, we introduce CityPersons, a new set of person annotations on top of the Cityscapes dataset. The diversity of CityPersons allows us for the first time to train one single CNN model that generalizes well over multiple benchmarks. Moreover, with additional training with CityPersons, we obtain top results using FasterRCNN on Caltech, improving especially for more difficult cases (heavy occlusion and small scale) and providing higher localization quality.
Learning Video Object Segmentation from Static Images
Dec 08, 2016
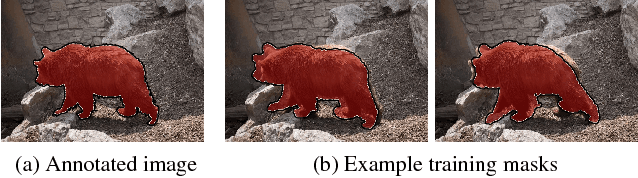
Inspired by recent advances of deep learning in instance segmentation and object tracking, we introduce video object segmentation problem as a concept of guided instance segmentation. Our model proceeds on a per-frame basis, guided by the output of the previous frame towards the object of interest in the next frame. We demonstrate that highly accurate object segmentation in videos can be enabled by using a convnet trained with static images only. The key ingredient of our approach is a combination of offline and online learning strategies, where the former serves to produce a refined mask from the previous frame estimate and the latter allows to capture the appearance of the specific object instance. Our method can handle different types of input annotations: bounding boxes and segments, as well as incorporate multiple annotated frames, making the system suitable for diverse applications. We obtain competitive results on three different datasets, independently from the type of input annotation.
Improved Image Boundaries for Better Video Segmentation
Nov 23, 2016
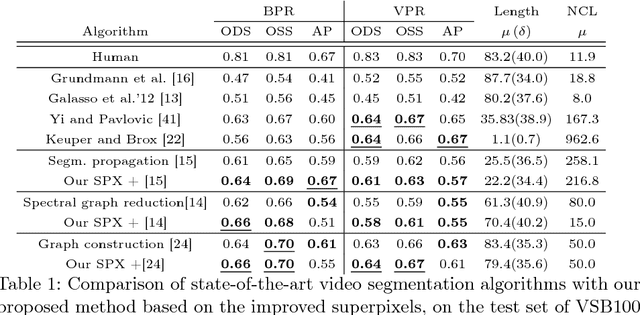
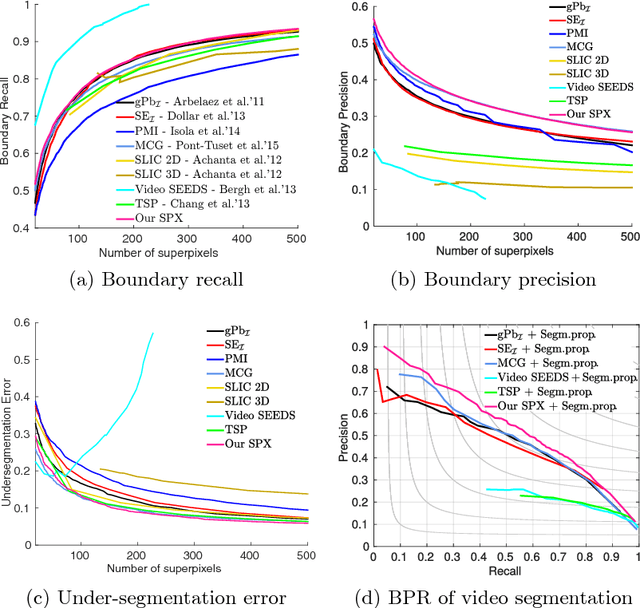
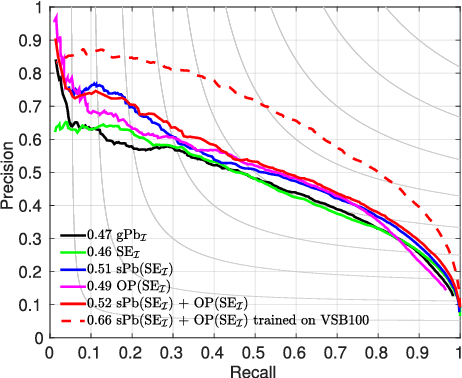
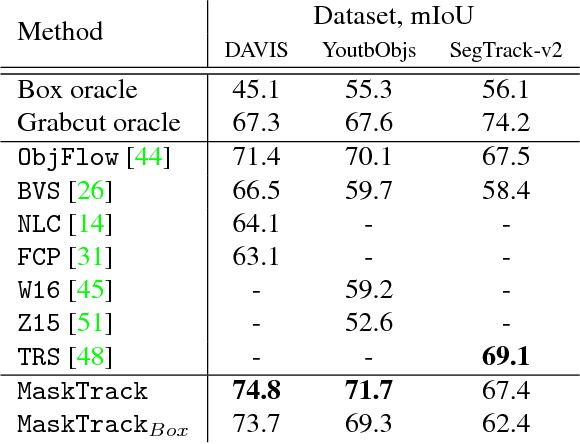
Graph-based video segmentation methods rely on superpixels as starting point. While most previous work has focused on the construction of the graph edges and weights as well as solving the graph partitioning problem, this paper focuses on better superpixels for video segmentation. We demonstrate by a comparative analysis that superpixels extracted from boundaries perform best, and show that boundary estimation can be significantly improved via image and time domain cues. With superpixels generated from our better boundaries we observe consistent improvement for two video segmentation methods in two different datasets.
Simple Does It: Weakly Supervised Instance and Semantic Segmentation
Nov 23, 2016
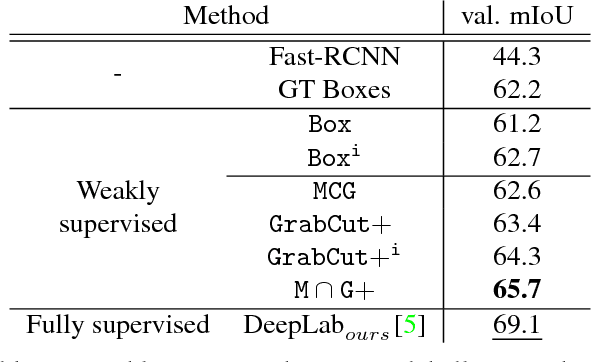
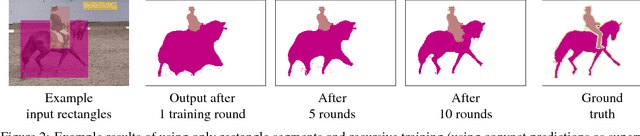
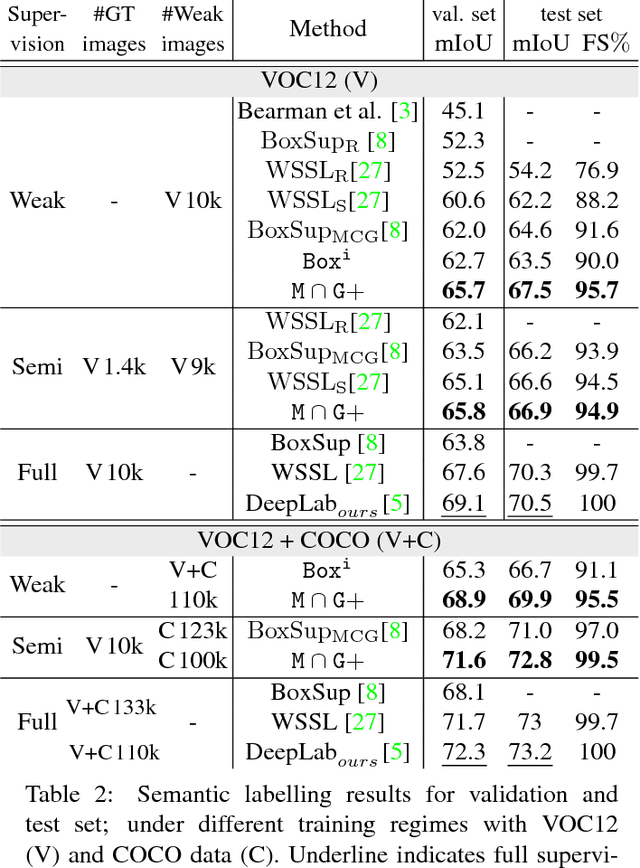
Semantic labelling and instance segmentation are two tasks that require particularly costly annotations. Starting from weak supervision in the form of bounding box detection annotations, we propose a new approach that does not require modification of the segmentation training procedure. We show that when carefully designing the input labels from given bounding boxes, even a single round of training is enough to improve over previously reported weakly supervised results. Overall, our weak supervision approach reaches ~95% of the quality of the fully supervised model, both for semantic labelling and instance segmentation.