 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry Transfer for Stylizing Radiance Fields
Feb 02, 2024Shape and geometric patterns are essential in defining stylistic identity. However, current 3D style transfer methods predominantly focus on transferring colors and textures, often overlooking geometric aspects. In this paper, we introduce Geometry Transfer, a novel method that leverages geometric deformation for 3D style transfer. This technique employs depth maps to extract a style guide, subsequently applied to stylize the geometry of radiance fields. Moreover, we propose new techniques that utilize geometric cues from the 3D scene, thereby enhancing aesthetic expressiveness and more accurately reflecting intended styles. Our extensive experiments show that Geometry Transfer enables a broader and more expressive range of stylizations, thereby significantly expanding the scope of 3D style transfer.
Sampling Based Scene-Space Video Processing
Feb 05, 2021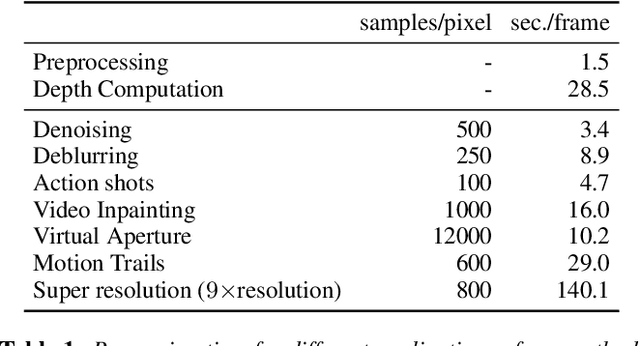
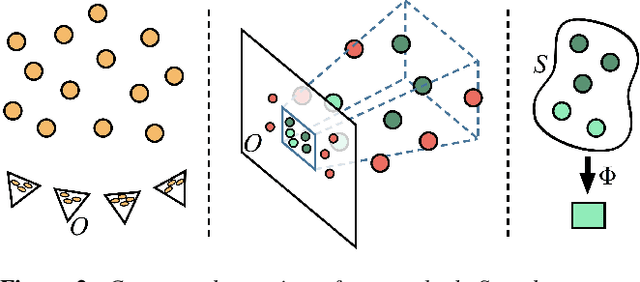

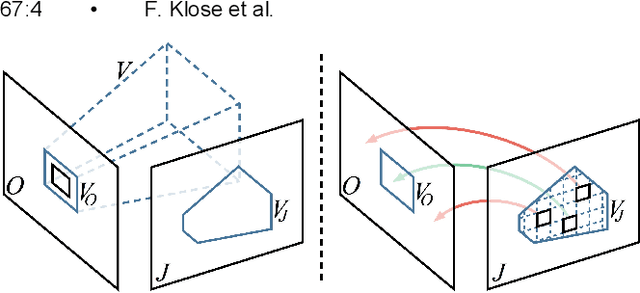
Many compelling video processing effects can be achieved if per-pixel depth information and 3D camera calibrations are known. However, the success of such methods is highly dependent on the accuracy of this "scene-space" information. We present a novel, sampling-based framework for processing video that enables high-quality scene-space video effects in the presence of inevitable errors in depth and camera pose estimation. Instead of trying to improve the explicit 3D scene representation, the key idea of our method is to exploit the high redundancy of approximate scene information that arises due to most scene points being visible multiple times across many frames of video. Based on this observation, we propose a novel pixel gathering and filtering approach. The gathering step is general and collects pixel samples in scene-space, while the filtering step is application-specific and computes a desired output video from the gathered sample sets. Our approach is easily parallelizable and has been implemented on GPU, allowing us to take full advantage of large volumes of video data and facilitating practical runtimes on HD video using a standard desktop computer. Our generic scene-space formulation is able to comprehensively describe a multitude of video processing applications such as denoising, deblurring, super resolution, object removal, computational shutter functions, and other scene-space camera effects. We present results for various casually captured, hand-held, moving, compressed, monocular videos depicting challenging scenes recorded in uncontrolled environments.
A Fully Progressive Approach to Single-Image Super-Resolution
Apr 10, 2018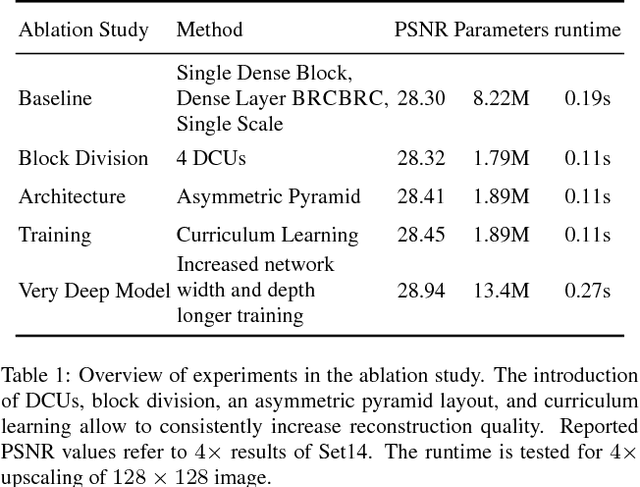
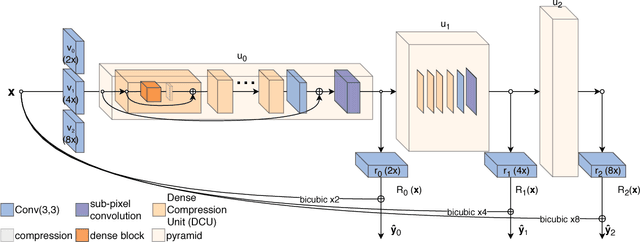

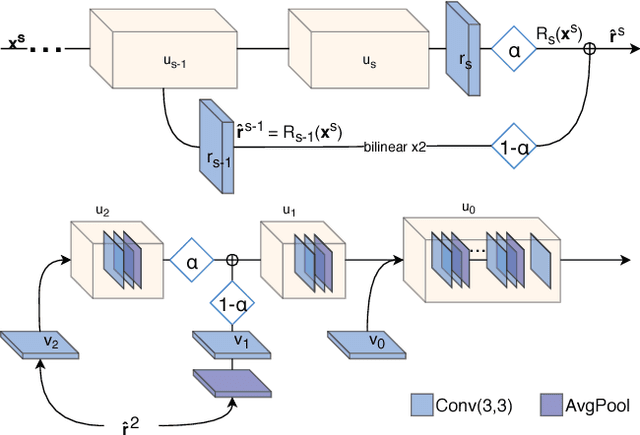
Recent deep learning approaches to single image super-resolution have achieved impressive results in terms of traditional error measures and perceptual quality. However, in each case it remains challenging to achieve high quality results for large upsampling factors. To this end, we propose a method (ProSR) that is progressive both in architecture and training: the network upsamples an image in intermediate steps, while the learning process is organized from easy to hard, as is done in curriculum learning. To obtain more photorealistic results, we design a generative adversarial network (GAN), named ProGanSR, that follows the same progressive multi-scale design principle. This not only allows to scale well to high upsampling factors (e.g., 8x) but constitutes a principled multi-scale approach that increases the reconstruction quality for all upsampling factors simultaneously. In particular ProSR ranks 2nd in terms of SSIM and 4th in terms of PSNR in the NTIRE2018 SISR challenge [34]. Compared to the top-ranking team, our model is marginally lower, but runs 5 times faster.
PhaseNet for Video Frame Interpolation
Apr 03, 2018
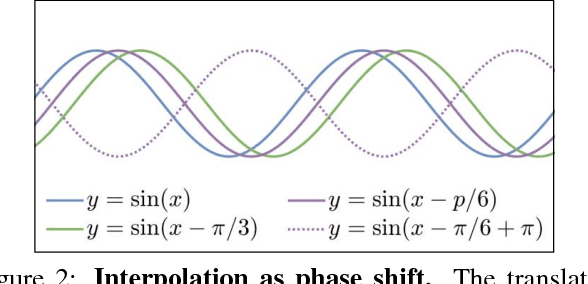
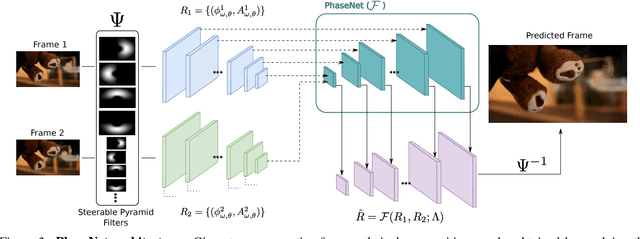
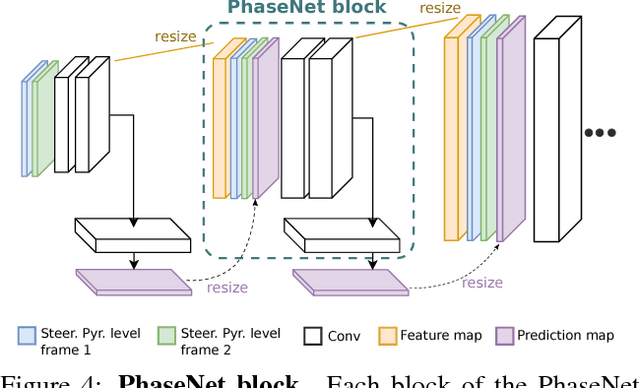
Most approaches for video frame interpolation require accurate dense correspondences to synthesize an in-between frame. Therefore, they do not perform well in challenging scenarios with e.g. lighting changes or motion blur. Recent deep learning approaches that rely on kernels to represent motion can only alleviate these problems to some extent. In those cases, methods that use a per-pixel phase-based motion representation have been shown to work well. However, they are only applicable for a limited amount of motion. We propose a new approach, PhaseNet, that is designed to robustly handle challenging scenarios while also coping with larger motion. Our approach consists of a neural network decoder that directly estimates the phase decomposition of the intermediate frame. We show that this is superior to the hand-crafted heuristics previously used in phase-based methods and also compares favorably to recent deep learning based approaches for video frame interpolation on challenging datasets.
Efficient Large-scale Approximate Nearest Neighbor Search on the GPU
Feb 20, 2017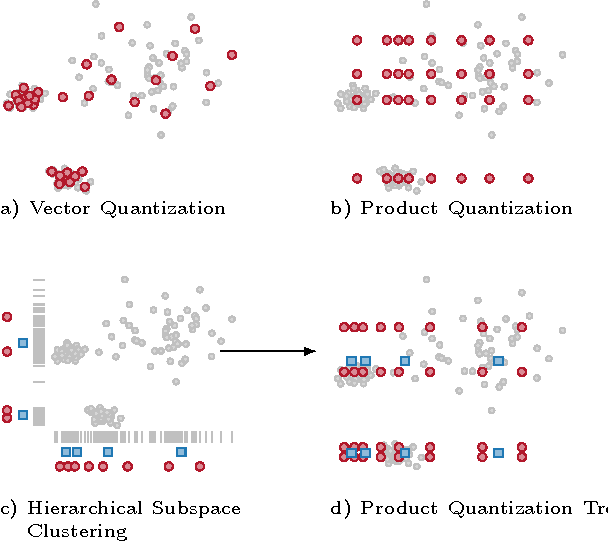
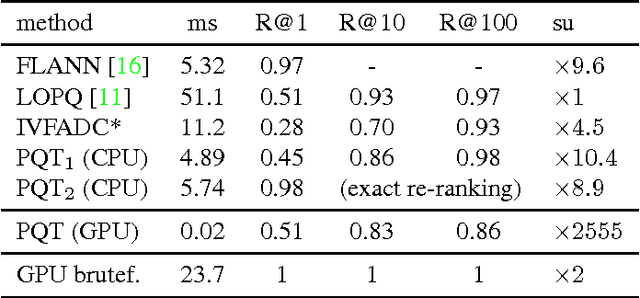


We present a new approach for efficient approximate nearest neighbor (ANN) search in high dimensional spaces, extending the idea of Product Quantization. We propose a two-level product and vector quantization tree that reduces the number of vector comparisons required during tree traversal. Our approach also includes a novel highly parallelizable re-ranking method for candidate vectors by efficiently reusing already computed intermediate values. Due to its small memory footprint during traversal, the method lends itself to an efficient, parallel GPU implementation. This Product Quantization Tree (PQT) approach significantly outperforms recent state of the art methods for high dimensional nearest neighbor queries on standard reference datasets. Ours is the first work that demonstrates GPU performance superior to CPU performance on high dimensional, large scale ANN problems in time-critical real-world applications, like loop-closing in videos.
Learning Video Object Segmentation from Static Images
Dec 08, 2016
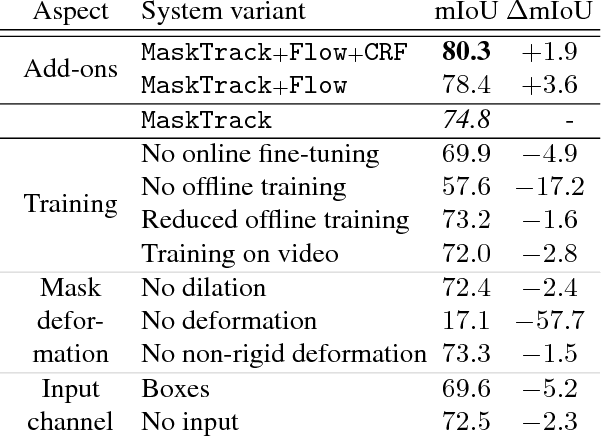
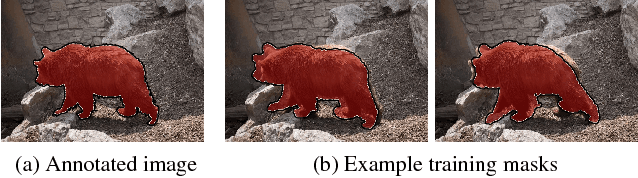
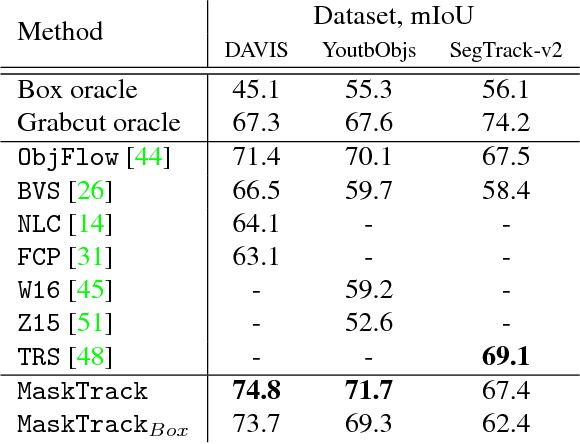
Inspired by recent advances of deep learning in instance segmentation and object tracking, we introduce video object segmentation problem as a concept of guided instance segmentation. Our model proceeds on a per-frame basis, guided by the output of the previous frame towards the object of interest in the next frame. We demonstrate that highly accurate object segmentation in videos can be enabled by using a convnet trained with static images only. The key ingredient of our approach is a combination of offline and online learning strategies, where the former serves to produce a refined mask from the previous frame estimate and the latter allows to capture the appearance of the specific object instance. Our method can handle different types of input annotations: bounding boxes and segments, as well as incorporate multiple annotated frames, making the system suitable for diverse applications. We obtain competitive results on three different datasets, independently from the type of input annotation.