 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDancing Points: Synthesizing Ballroom Dancing with Three-Point Inputs
Jan 05, 2026Ballroom dancing is a structured yet expressive motion category. Its highly diverse movement and complex interactions between leader and follower dancers make the understanding and synthesis challenging. We demonstrate that the three-point trajectory available from a virtual reality (VR) device can effectively serve as a dancer's motion descriptor, simplifying the modeling and synthesis of interplay between dancers' full-body motions down to sparse trajectories. Thanks to the low dimensionality, we can employ an efficient MLP network to predict the follower's three-point trajectory directly from the leader's three-point input for certain types of ballroom dancing, addressing the challenge of modeling high-dimensional full-body interaction. It also prevents our method from overfitting thanks to its compact yet explicit representation. By leveraging the inherent structure of the movements and carefully planning the autoregressive procedure, we show a deterministic neural network is able to translate three-point trajectories into a virtual embodied avatar, which is typically considered under-constrained and requires generative models for common motions. In addition, we demonstrate this deterministic approach generalizes beyond small, structured datasets like ballroom dancing, and performs robustly on larger, more diverse datasets such as LaFAN. Our method provides a computationally- and data-efficient solution, opening new possibilities for immersive paired dancing applications. Code and pre-trained models for this paper are available at https://peizhuoli.github.io/dancing-points.
TetWeave: Isosurface Extraction using On-The-Fly Delaunay Tetrahedral Grids for Gradient-Based Mesh Optimization
May 08, 2025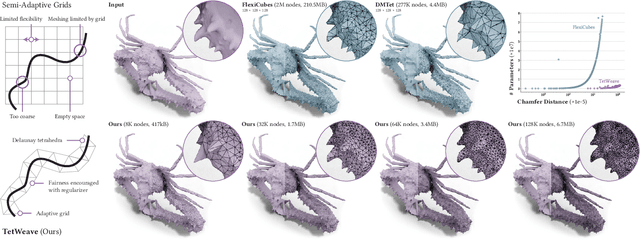
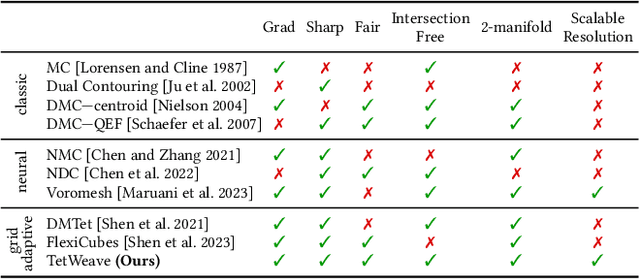


We introduce TetWeave, a novel isosurface representation for gradient-based mesh optimization that jointly optimizes the placement of a tetrahedral grid used for Marching Tetrahedra and a novel directional signed distance at each point. TetWeave constructs tetrahedral grids on-the-fly via Delaunay triangulation, enabling increased flexibility compared to predefined grids. The extracted meshes are guaranteed to be watertight, two-manifold and intersection-free. The flexibility of TetWeave enables a resampling strategy that places new points where reconstruction error is high and allows to encourage mesh fairness without compromising on reconstruction error. This leads to high-quality, adaptive meshes that require minimal memory usage and few parameters to optimize. Consequently, TetWeave exhibits near-linear memory scaling relative to the vertex count of the output mesh - a substantial improvement over predefined grids. We demonstrate the applicability of TetWeave to a broad range of challenging tasks in computer graphics and vision, such as multi-view 3D reconstruction, mesh compression and geometric texture generation.
Interactive Scene Authoring with Specialized Generative Primitives
Dec 20, 2024
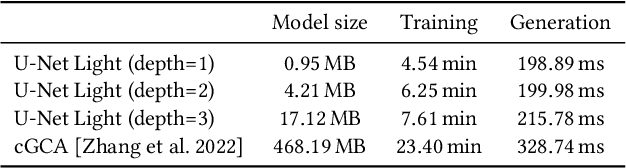
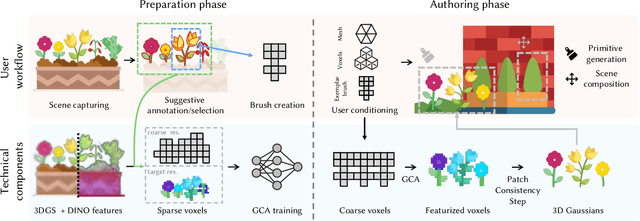
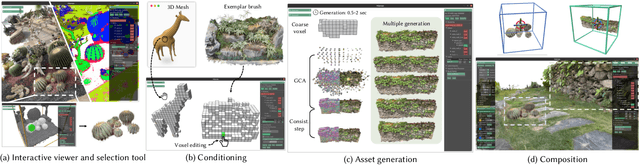
Generating high-quality 3D digital assets often requires expert knowledge of complex design tools. We introduce Specialized Generative Primitives, a generative framework that allows non-expert users to author high-quality 3D scenes in a seamless, lightweight, and controllable manner. Each primitive is an efficient generative model that captures the distribution of a single exemplar from the real world. With our framework, users capture a video of an environment, which we turn into a high-quality and explicit appearance model thanks to 3D Gaussian Splatting. Users then select regions of interest guided by semantically-aware features. To create a generative primitive, we adapt Generative Cellular Automata to single-exemplar training and controllable generation. We decouple the generative task from the appearance model by operating on sparse voxels and we recover a high-quality output with a subsequent sparse patch consistency step. Each primitive can be trained within 10 minutes and used to author new scenes interactively in a fully compositional manner. We showcase interactive sessions where various primitives are extracted from real-world scenes and controlled to create 3D assets and scenes in a few minutes. We also demonstrate additional capabilities of our primitives: handling various 3D representations to control generation, transferring appearances, and editing geometries.
AIpparel: A Large Multimodal Generative Model for Digital Garments
Dec 05, 2024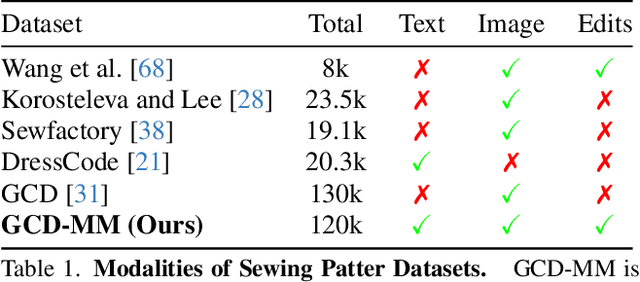
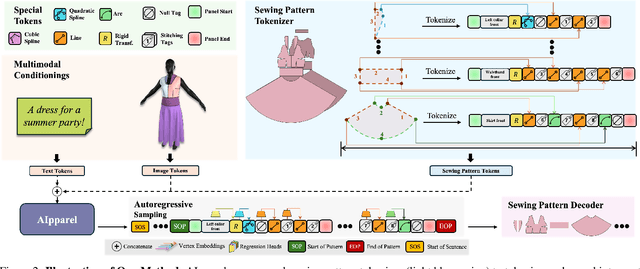

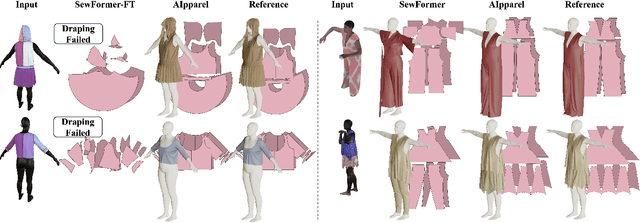
Apparel is essential to human life, offering protection, mirroring cultural identities, and showcasing personal style. Yet, the creation of garments remains a time-consuming process, largely due to the manual work involved in designing them. To simplify this process, we introduce AIpparel, a large multimodal model for generating and editing sewing patterns. Our model fine-tunes state-of-the-art large multimodal models (LMMs) on a custom-curated large-scale dataset of over 120,000 unique garments, each with multimodal annotations including text, images, and sewing patterns. Additionally, we propose a novel tokenization scheme that concisely encodes these complex sewing patterns so that LLMs can learn to predict them efficiently. \methodname achieves state-of-the-art performance in single-modal tasks, including text-to-garment and image-to-garment prediction, and enables novel multimodal garment generation applications such as interactive garment editing. The project website is at georgenakayama.github.io/AIpparel/.
SD-$π$XL: Generating Low-Resolution Quantized Imagery via Score Distillation
Oct 08, 2024Low-resolution quantized imagery, such as pixel art, is seeing a revival in modern applications ranging from video game graphics to digital design and fabrication, where creativity is often bound by a limited palette of elemental units. Despite their growing popularity, the automated generation of quantized images from raw inputs remains a significant challenge, often necessitating intensive manual input. We introduce SD-$\pi$XL, an approach for producing quantized images that employs score distillation sampling in conjunction with a differentiable image generator. Our method enables users to input a prompt and optionally an image for spatial conditioning, set any desired output size $H \times W$, and choose a palette of $n$ colors or elements. Each color corresponds to a distinct class for our generator, which operates on an $H \times W \times n$ tensor. We adopt a softmax approach, computing a convex sum of elements, thus rendering the process differentiable and amenable to backpropagation. We show that employing Gumbel-softmax reparameterization allows for crisp pixel art effects. Unique to our method is the ability to transform input images into low-resolution, quantized versions while retaining their key semantic features. Our experiments validate SD-$\pi$XL's performance in creating visually pleasing and faithful representations, consistently outperforming the current state-of-the-art. Furthermore, we showcase SD-$\pi$XL's practical utility in fabrication through its applications in interlocking brick mosaic, beading and embroidery design.
GarmentCodeData: A Dataset of 3D Made-to-Measure Garments With Sewing Patterns
May 27, 2024
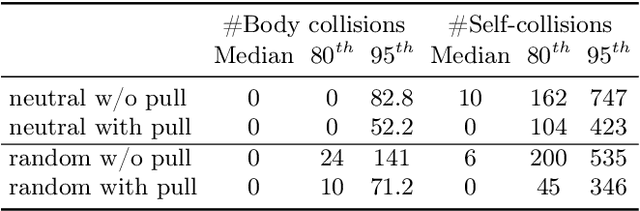

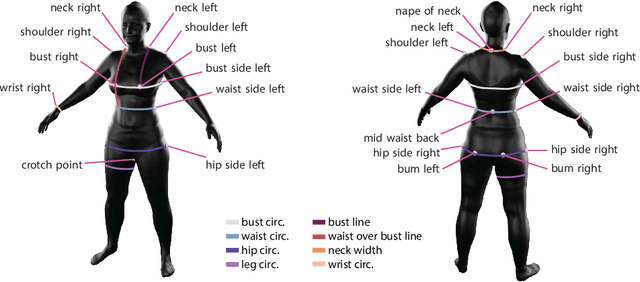
Recent research interest in the learning-based processing of garments, from virtual fitting to generation and reconstruction, stumbles on a scarcity of high-quality public data in the domain. We contribute to resolving this need by presenting the first large-scale synthetic dataset of 3D made-to-measure garments with sewing patterns, as well as its generation pipeline. GarmentCodeData contains 115,000 data points that cover a variety of designs in many common garment categories: tops, shirts, dresses, jumpsuits, skirts, pants, etc., fitted to a variety of body shapes sampled from a custom statistical body model based on CAESAR, as well as a standard reference body shape, applying three different textile materials. To enable the creation of datasets of such complexity, we introduce a set of algorithms for automatically taking tailor's measures on sampled body shapes, sampling strategies for sewing pattern design, and propose an automatic, open-source 3D garment draping pipeline based on a fast XPBD simulator, while contributing several solutions for collision resolution and drape correctness to enable scalability. Dataset: http://hdl.handle.net/20.500.11850/673889
Pose-to-Motion: Cross-Domain Motion Retargeting with Pose Prior
Oct 31, 2023



Creating believable motions for various characters has long been a goal in computer graphics. Current learning-based motion synthesis methods depend on extensive motion datasets, which are often challenging, if not impossible, to obtain. On the other hand, pose data is more accessible, since static posed characters are easier to create and can even be extracted from images using recent advancements in computer vision. In this paper, we utilize this alternative data source and introduce a neural motion synthesis approach through retargeting. Our method generates plausible motions for characters that have only pose data by transferring motion from an existing motion capture dataset of another character, which can have drastically different skeletons. Our experiments show that our method effectively combines the motion features of the source character with the pose features of the target character, and performs robustly with small or noisy pose data sets, ranging from a few artist-created poses to noisy poses estimated directly from images. Additionally, a conducted user study indicated that a majority of participants found our retargeted motion to be more enjoyable to watch, more lifelike in appearance, and exhibiting fewer artifacts. Project page: https://cyanzhao42.github.io/pose2motion
SENS: Sketch-based Implicit Neural Shape Modeling
Jun 09, 2023We present SENS, a novel method for generating and editing 3D models from hand-drawn sketches, including those of an abstract nature. Our method allows users to quickly and easily sketch a shape, and then maps the sketch into the latent space of a part-aware neural implicit shape architecture. SENS analyzes the sketch and encodes its parts into ViT patch encoding, then feeds them into a transformer decoder that converts them to shape embeddings, suitable for editing 3D neural implicit shapes. SENS not only provides intuitive sketch-based generation and editing, but also excels in capturing the intent of the user's sketch to generate a variety of novel and expressive 3D shapes, even from abstract sketches. We demonstrate the effectiveness of our model compared to the state-of-the-art using objective metric evaluation criteria and a decisive user study, both indicating strong performance on sketches with a medium level of abstraction. Furthermore, we showcase its intuitive sketch-based shape editing capabilities.
Example-based Motion Synthesis via Generative Motion Matching
Jun 01, 2023
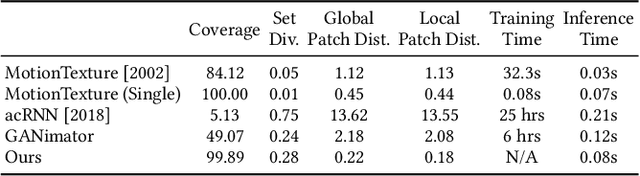

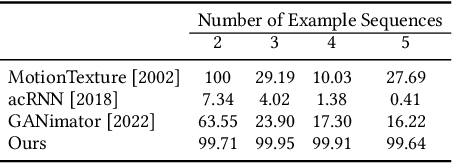
We present GenMM, a generative model that "mines" as many diverse motions as possible from a single or few example sequences. In stark contrast to existing data-driven methods, which typically require long offline training time, are prone to visual artifacts, and tend to fail on large and complex skeletons, GenMM inherits the training-free nature and the superior quality of the well-known Motion Matching method. GenMM can synthesize a high-quality motion within a fraction of a second, even with highly complex and large skeletal structures. At the heart of our generative framework lies the generative motion matching module, which utilizes the bidirectional visual similarity as a generative cost function to motion matching, and operates in a multi-stage framework to progressively refine a random guess using exemplar motion matches. In addition to diverse motion generation, we show the versatility of our generative framework by extending it to a number of scenarios that are not possible with motion matching alone, including motion completion, key frame-guided generation, infinite looping, and motion reassembly. Code and data for this paper are at https://wyysf-98.github.io/GenMM/
Neural Document Unwarping using Coupled Grids
Feb 06, 2023Restoring the original, flat appearance of a printed document from casual photographs of bent and wrinkled pages is a common everyday problem. In this paper we propose a novel method for grid-based single-image document unwarping. Our method performs geometric distortion correction via a deep fully convolutional neural network that learns to predict the 3D grid mesh of the document and the corresponding 2D unwarping grid in a multi-task fashion, implicitly encoding the coupling between the shape of a 3D object and its 2D image. We additionally create and publish our own dataset, called UVDoc, which combines pseudo-photorealistic document images with ground truth grid-based physical 3D and unwarping information, allowing unwarping models to train on data that is more realistic in appearance than the commonly used synthetic Doc3D dataset, whilst also being more physically accurate. Our dataset is labeled with all the information necessary to train our unwarping network, without having to engineer separate loss functions that can deal with the lack of ground-truth typically found in document in the wild datasets. We include a thorough evaluation that demonstrates that our dual-task unwarping network trained on a mix of synthetic and pseudo-photorealistic images achieves state-of-the-art performance on the DocUNet benchmark dataset. Our code, results and UVDoc dataset will be made publicly available upon publication.