 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-Guided Geometric Stylization of 3D Meshes
Apr 09, 2026Recent generative models can create visually plausible 3D representations of objects. However, the generation process often allows for implicit control signals, such as contextual descriptions, and rarely supports bold geometric distortions beyond existing data distributions. We propose a geometric stylization framework that deforms a 3D mesh, allowing it to express the style of an image. While style is inherently ambiguous, we utilize pre-trained diffusion models to extract an abstract representation of the provided image. Our coarse-to-fine stylization pipeline can drastically deform the input 3D model to express a diverse range of geometric variations while retaining the valid topology of the original mesh and part-level semantics. We also propose an approximate VAE encoder that provides efficient and reliable gradients from mesh renderings. Extensive experiments demonstrate that our method can create stylized 3D meshes that reflect unique geometric features of the pictured assets, such as expressive poses and silhouettes, thereby supporting the creation of distinctive artistic 3D creations. Project page: https://changwoonchoi.github.io/GeoStyle
Recovering Dynamic 3D Sketches from Videos
Mar 27, 2025



Understanding 3D motion from videos presents inherent challenges due to the diverse types of movement, ranging from rigid and deformable objects to articulated structures. To overcome this, we propose Liv3Stroke, a novel approach for abstracting objects in motion with deformable 3D strokes. The detailed movements of an object may be represented by unstructured motion vectors or a set of motion primitives using a pre-defined articulation from a template model. Just as a free-hand sketch can intuitively visualize scenes or intentions with a sparse set of lines, we utilize a set of parametric 3D curves to capture a set of spatially smooth motion elements for general objects with unknown structures. We first extract noisy, 3D point cloud motion guidance from video frames using semantic features, and our approach deforms a set of curves to abstract essential motion features as a set of explicit 3D representations. Such abstraction enables an understanding of prominent components of motions while maintaining robustness to environmental factors. Our approach allows direct analysis of 3D object movements from video, tackling the uncertainty that typically occurs when translating real-world motion into recorded footage. The project page is accessible via: https://jaeah.me/liv3stroke_web
Humans as a Calibration Pattern: Dynamic 3D Scene Reconstruction from Unsynchronized and Uncalibrated Videos
Dec 26, 2024



Recent works on dynamic neural field reconstruction assume input from synchronized multi-view videos with known poses. These input constraints are often unmet in real-world setups, making the approach impractical. We demonstrate that unsynchronized videos with unknown poses can generate dynamic neural fields if the videos capture human motion. Humans are one of the most common dynamic subjects whose poses can be estimated using state-of-the-art methods. While noisy, the estimated human shape and pose parameters provide a decent initialization for the highly non-convex and under-constrained problem of training a consistent dynamic neural representation. Given the sequences of pose and shape of humans, we estimate the time offsets between videos, followed by camera pose estimations by analyzing 3D joint locations. Then, we train dynamic NeRF employing multiresolution rids while simultaneously refining both time offsets and camera poses. The setup still involves optimizing many parameters, therefore, we introduce a robust progressive learning strategy to stabilize the process. Experiments show that our approach achieves accurate spatiotemporal calibration and high-quality scene reconstruction in challenging conditions.
Interactive Scene Authoring with Specialized Generative Primitives
Dec 20, 2024
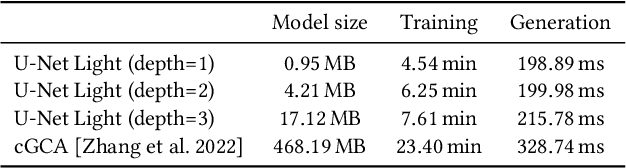
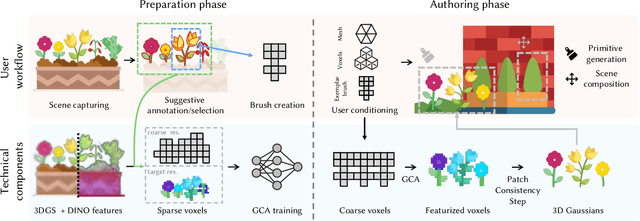
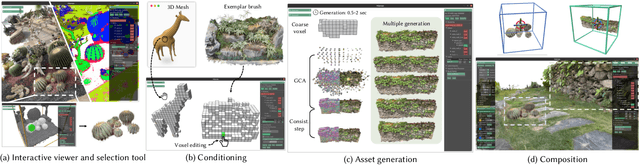
Generating high-quality 3D digital assets often requires expert knowledge of complex design tools. We introduce Specialized Generative Primitives, a generative framework that allows non-expert users to author high-quality 3D scenes in a seamless, lightweight, and controllable manner. Each primitive is an efficient generative model that captures the distribution of a single exemplar from the real world. With our framework, users capture a video of an environment, which we turn into a high-quality and explicit appearance model thanks to 3D Gaussian Splatting. Users then select regions of interest guided by semantically-aware features. To create a generative primitive, we adapt Generative Cellular Automata to single-exemplar training and controllable generation. We decouple the generative task from the appearance model by operating on sparse voxels and we recover a high-quality output with a subsequent sparse patch consistency step. Each primitive can be trained within 10 minutes and used to author new scenes interactively in a fully compositional manner. We showcase interactive sessions where various primitives are extracted from real-world scenes and controlled to create 3D assets and scenes in a few minutes. We also demonstrate additional capabilities of our primitives: handling various 3D representations to control generation, transferring appearances, and editing geometries.
I$^2$-SLAM: Inverting Imaging Process for Robust Photorealistic Dense SLAM
Jul 16, 2024



We present an inverse image-formation module that can enhance the robustness of existing visual SLAM pipelines for casually captured scenarios. Casual video captures often suffer from motion blur and varying appearances, which degrade the final quality of coherent 3D visual representation. We propose integrating the physical imaging into the SLAM system, which employs linear HDR radiance maps to collect measurements. Specifically, individual frames aggregate images of multiple poses along the camera trajectory to explain prevalent motion blur in hand-held videos. Additionally, we accommodate per-frame appearance variation by dedicating explicit variables for image formation steps, namely white balance, exposure time, and camera response function. Through joint optimization of additional variables, the SLAM pipeline produces high-quality images with more accurate trajectories. Extensive experiments demonstrate that our approach can be incorporated into recent visual SLAM pipelines using various scene representations, such as neural radiance fields or Gaussian splatting.
3Doodle: Compact Abstraction of Objects with 3D Strokes
Feb 06, 2024



While free-hand sketching has long served as an efficient representation to convey characteristics of an object, they are often subjective, deviating significantly from realistic representations. Moreover, sketches are not consistent for arbitrary viewpoints, making it hard to catch 3D shapes. We propose 3Dooole, generating descriptive and view-consistent sketch images given multi-view images of the target object. Our method is based on the idea that a set of 3D strokes can efficiently represent 3D structural information and render view-consistent 2D sketches. We express 2D sketches as a union of view-independent and view-dependent components. 3D cubic B ezier curves indicate view-independent 3D feature lines, while contours of superquadrics express a smooth outline of the volume of varying viewpoints. Our pipeline directly optimizes the parameters of 3D stroke primitives to minimize perceptual losses in a fully differentiable manner. The resulting sparse set of 3D strokes can be rendered as abstract sketches containing essential 3D characteristic shapes of various objects. We demonstrate that 3Doodle can faithfully express concepts of the original images compared with recent sketch generation approaches.
LDL: Line Distance Functions for Panoramic Localization
Aug 27, 2023



We introduce LDL, a fast and robust algorithm that localizes a panorama to a 3D map using line segments. LDL focuses on the sparse structural information of lines in the scene, which is robust to illumination changes and can potentially enable efficient computation. While previous line-based localization approaches tend to sacrifice accuracy or computation time, our method effectively observes the holistic distribution of lines within panoramic images and 3D maps. Specifically, LDL matches the distribution of lines with 2D and 3D line distance functions, which are further decomposed along principal directions of lines to increase the expressiveness. The distance functions provide coarse pose estimates by comparing the distributional information, where the poses are further optimized using conventional local feature matching. As our pipeline solely leverages line geometry and local features, it does not require costly additional training of line-specific features or correspondence matching. Nevertheless, our method demonstrates robust performance on challenging scenarios including object layout changes, illumination shifts, and large-scale scenes, while exhibiting fast pose search terminating within a matter of milliseconds. We thus expect our method to serve as a practical solution for line-based localization, and complement the well-established point-based paradigm. The code for LDL is available through the following link: https://github.com/82magnolia/panoramic-localization.
Balanced Spherical Grid for Egocentric View Synthesis
Mar 24, 2023



We present EgoNeRF, a practical solution to reconstruct large-scale real-world environments for VR assets. Given a few seconds of casually captured 360 video, EgoNeRF can efficiently build neural radiance fields which enable high-quality rendering from novel viewpoints. Motivated by the recent acceleration of NeRF using feature grids, we adopt spherical coordinate instead of conventional Cartesian coordinate. Cartesian feature grid is inefficient to represent large-scale unbounded scenes because it has a spatially uniform resolution, regardless of distance from viewers. The spherical parameterization better aligns with the rays of egocentric images, and yet enables factorization for performance enhancement. However, the na\"ive spherical grid suffers from irregularities at two poles, and also cannot represent unbounded scenes. To avoid singularities near poles, we combine two balanced grids, which results in a quasi-uniform angular grid. We also partition the radial grid exponentially and place an environment map at infinity to represent unbounded scenes. Furthermore, with our resampling technique for grid-based methods, we can increase the number of valid samples to train NeRF volume. We extensively evaluate our method in our newly introduced synthetic and real-world egocentric 360 video datasets, and it consistently achieves state-of-the-art performance.
IBL-NeRF: Image-Based Lighting Formulation of Neural Radiance Fields
Oct 15, 2022

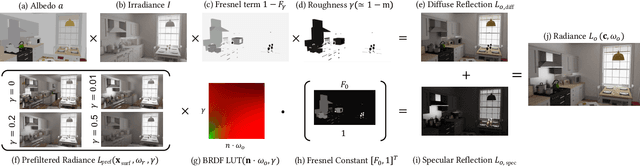
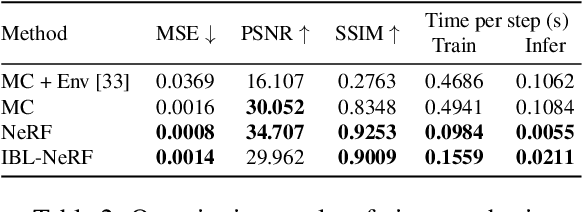
We propose IBL-NeRF, which decomposes the neural radiance fields (NeRF) of large-scale indoor scenes into intrinsic components. Previous approaches for the inverse rendering of NeRF transform the implicit volume to fit the rendering pipeline of explicit geometry, and approximate the views of segmented, isolated objects with environment lighting. In contrast, our inverse rendering extends the original NeRF formulation to capture the spatial variation of lighting within the scene volume, in addition to surface properties. Specifically, the scenes of diverse materials are decomposed into intrinsic components for image-based rendering, namely, albedo, roughness, surface normal, irradiance, and prefiltered radiance. All of the components are inferred as neural images from MLP, which can model large-scale general scenes. By adopting the image-based formulation of NeRF, our approach inherits superior visual quality and multi-view consistency for synthesized images. We demonstrate the performance on scenes with complex object layouts and light configurations, which could not be processed in any of the previous works.
CPO: Change Robust Panorama to Point Cloud Localization
Jul 12, 2022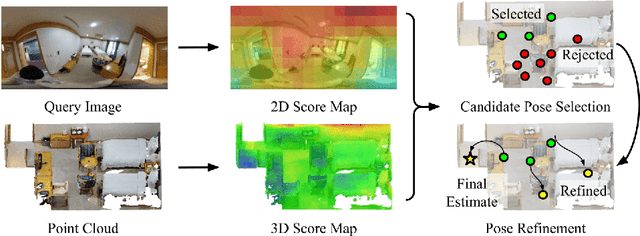
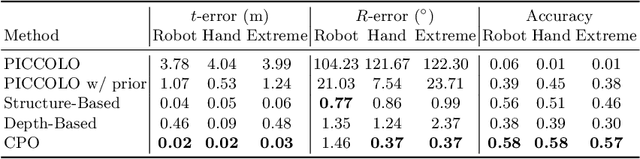

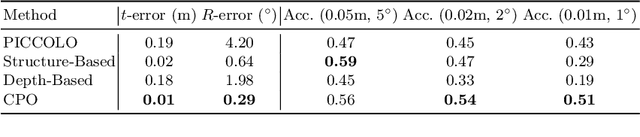
We present CPO, a fast and robust algorithm that localizes a 2D panorama with respect to a 3D point cloud of a scene possibly containing changes. To robustly handle scene changes, our approach deviates from conventional feature point matching, and focuses on the spatial context provided from panorama images. Specifically, we propose efficient color histogram generation and subsequent robust localization using score maps. By utilizing the unique equivariance of spherical projections, we propose very fast color histogram generation for a large number of camera poses without explicitly rendering images for all candidate poses. We accumulate the regional consistency of the panorama and point cloud as 2D/3D score maps, and use them to weigh the input color values to further increase robustness. The weighted color distribution quickly finds good initial poses and achieves stable convergence for gradient-based optimization. CPO is lightweight and achieves effective localization in all tested scenarios, showing stable performance despite scene changes, repetitive structures, or featureless regions, which are typical challenges for visual localization with perspective cameras.