 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorized Diffusion: Perceptual Illusions by Noise Decomposition
Apr 17, 2024Given a factorization of an image into a sum of linear components, we present a zero-shot method to control each individual component through diffusion model sampling. For example, we can decompose an image into low and high spatial frequencies and condition these components on different text prompts. This produces hybrid images, which change appearance depending on viewing distance. By decomposing an image into three frequency subbands, we can generate hybrid images with three prompts. We also use a decomposition into grayscale and color components to produce images whose appearance changes when they are viewed in grayscale, a phenomena that naturally occurs under dim lighting. And we explore a decomposition by a motion blur kernel, which produces images that change appearance under motion blurring. Our method works by denoising with a composite noise estimate, built from the components of noise estimates conditioned on different prompts. We also show that for certain decompositions, our method recovers prior approaches to compositional generation and spatial control. Finally, we show that we can extend our approach to generate hybrid images from real images. We do this by holding one component fixed and generating the remaining components, effectively solving an inverse problem.
Visual Anagrams: Generating Multi-View Optical Illusions with Diffusion Models
Nov 29, 2023We address the problem of synthesizing multi-view optical illusions: images that change appearance upon a transformation, such as a flip or rotation. We propose a simple, zero-shot method for obtaining these illusions from off-the-shelf text-to-image diffusion models. During the reverse diffusion process, we estimate the noise from different views of a noisy image. We then combine these noise estimates together and denoise the image. A theoretical analysis suggests that this method works precisely for views that can be written as orthogonal transformations, of which permutations are a subset. This leads to the idea of a visual anagram--an image that changes appearance under some rearrangement of pixels. This includes rotations and flips, but also more exotic pixel permutations such as a jigsaw rearrangement. Our approach also naturally extends to illusions with more than two views. We provide both qualitative and quantitative results demonstrating the effectiveness and flexibility of our method. Please see our project webpage for additional visualizations and results: https://dangeng.github.io/visual_anagrams/
On the Robustness of Normalizing Flows for Inverse Problems in Imaging
Dec 08, 2022



Conditional normalizing flows can generate diverse image samples for solving inverse problems. Most normalizing flows for inverse problems in imaging employ the conditional affine coupling layer that can generate diverse images quickly. However, unintended severe artifacts are occasionally observed in the output of them. In this work, we address this critical issue by investigating the origins of these artifacts and proposing the conditions to avoid them. First of all, we empirically and theoretically reveal that these problems are caused by ``exploding variance'' in the conditional affine coupling layer for certain out-of-distribution (OOD) conditional inputs. Then, we further validated that the probability of causing erroneous artifacts in pixels is highly correlated with a Mahalanobis distance-based OOD score for inverse problems in imaging. Lastly, based on our investigations, we propose a remark to avoid exploding variance and then based on it, we suggest a simple remedy that substitutes the affine coupling layers with the modified rational quadratic spline coupling layers in normalizing flows, to encourage the robustness of generated image samples. Our experimental results demonstrated that our suggested methods effectively suppressed critical artifacts occurring in normalizing flows for super-resolution space generation and low-light image enhancement without compromising performance.
Probabilistic Implicit Scene Completion
Apr 04, 2022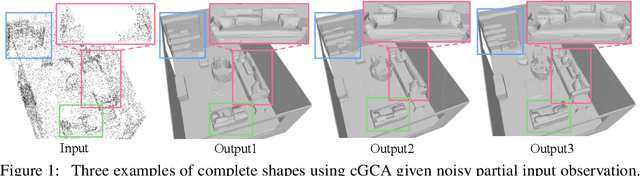
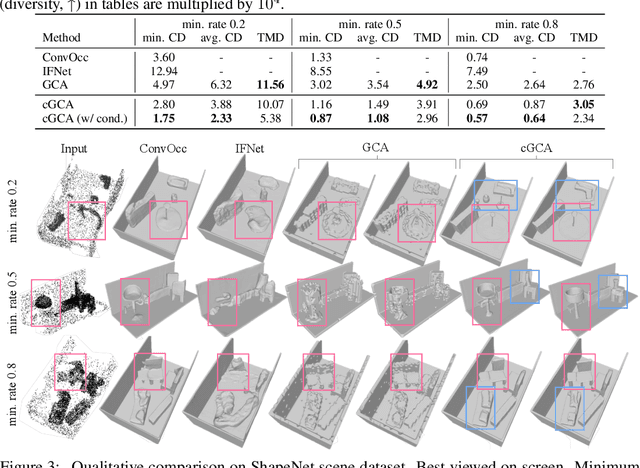
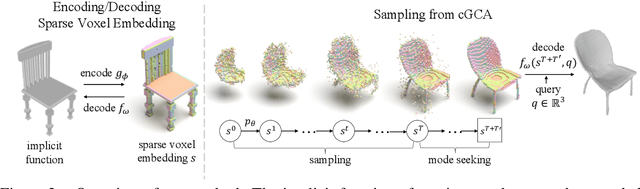

We propose a probabilistic shape completion method extended to the continuous geometry of large-scale 3D scenes. Real-world scans of 3D scenes suffer from a considerable amount of missing data cluttered with unsegmented objects. The problem of shape completion is inherently ill-posed, and high-quality result requires scalable solutions that consider multiple possible outcomes. We employ the Generative Cellular Automata that learns the multi-modal distribution and transform the formulation to process large-scale continuous geometry. The local continuous shape is incrementally generated as a sparse voxel embedding, which contains the latent code for each occupied cell. We formally derive that our training objective for the sparse voxel embedding maximizes the variational lower bound of the complete shape distribution and therefore our progressive generation constitutes a valid generative model. Experiments show that our model successfully generates diverse plausible scenes faithful to the input, especially when the input suffers from a significant amount of missing data. We also demonstrate that our approach outperforms deterministic models even in less ambiguous cases with a small amount of missing data, which infers that probabilistic formulation is crucial for high-quality geometry completion on input scans exhibiting any levels of completeness.