 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriadic Dynamics Aware Diffusion Posterior Sampling for Inverse Problems: Optimizing Guidance and Stochasticity Schedules
May 26, 2026Generative posterior sampling using diffusion models has emerged as a dominant paradigm for solving inverse problems in imaging, which usually consists of three main components: data consistency (DC) guidance, classifier-free guidance (CFG) and stochasticity. While prior arts have focused on how to develop each or all components, less attention has given to how to schedule them, leading to heuristically fixed or partially adjusted suboptimal schedules. In this work, we argue that the interactions among all three components in terms of scheduling are crucial for significantly improved performance in solving inverse problems in imaging. Our analysis shows that aggressive CFG early in sampling conflict with DC guidance, while stochasticity brings the trajectory back to higher-probability regions. Based on these findings, we propose Triadic Dynamics Aware Posterior Sampling (TriPS), which reformulates posterior sampling as a time-varying control problem and optimizes schedules following a triadic trend of decreasing DC and stochasticity scales alongside increasing CFG scale. TriPS achieves this through two strategies: template-based search over functional priors for reliable baseline schedules, and Group Relative Policy Optimization (GRPO)-based reinforcement learning for more flexible temporal curves. Experiments demonstrate TriPS outperforms state-of-the-art baselines in data fidelity and perceptual realism.
Unlearning the Unpromptable: Prompt-free Instance Unlearning in Diffusion Models
Mar 12, 2026Machine unlearning aims to remove specific outputs from trained models, often at the concept level, such as forgetting all occurrences of a particular celebrity or filtering content via text prompts. However, many undesired outputs, such as an individual's face or generations culturally or factually misinterpreted, cannot often be specified by text prompts. We address this underexplored setting of instance unlearning for outputs that are undesired but unpromptable, where the goal is to forget target outputs selectively while preserving the rest. To this end, we introduce an effective surrogate-based unlearning method that leverages image editing, timestep-aware weighting, and gradient surgery to guide trained diffusion models toward forgetting specific outputs. Experiments on conditional (Stable Diffusion 3) and unconditional (DDPM-CelebA) diffusion models demonstrate that our prompt-free method uniquely unlearns unpromptable outputs, such as faces and culturally inaccurate depictions, with preserved integrity, unlike prompt-based and prompt-free baselines. Our proposed method would serve as a practical hotfix for diffusion model providers to ensure privacy protection and ethical compliance.
DiffBMP: Differentiable Rendering with Bitmap Primitives
Feb 26, 2026We introduce DiffBMP, a scalable and efficient differentiable rendering engine for a collection of bitmap images. Our work addresses a limitation that traditional differentiable renderers are constrained to vector graphics, given that most images in the world are bitmaps. Our core contribution is a highly parallelized rendering pipeline, featuring a custom CUDA implementation for calculating gradients. This system can, for example, optimize the position, rotation, scale, color, and opacity of thousands of bitmap primitives all in under 1 min using a consumer GPU. We employ and validate several techniques to facilitate the optimization: soft rasterization via Gaussian blur, structure-aware initialization, noisy canvas, and specialized losses/heuristics for videos or spatially constrained images. We demonstrate DiffBMP is not just an isolated tool, but a practical one designed to integrate into creative workflows. It supports exporting compositions to a native, layered file format, and the entire framework is publicly accessible via an easy-to-hack Python package.
Oaken: Fast and Efficient LLM Serving with Online-Offline Hybrid KV Cache Quantization
Mar 24, 2025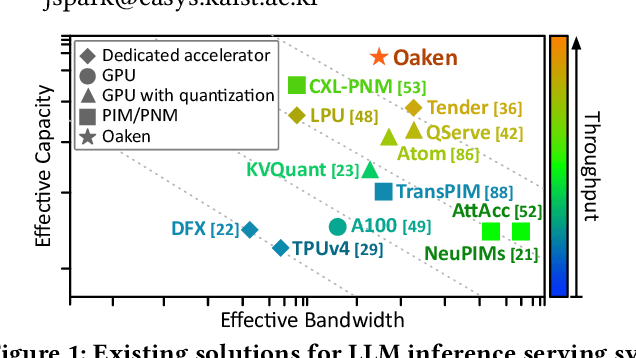

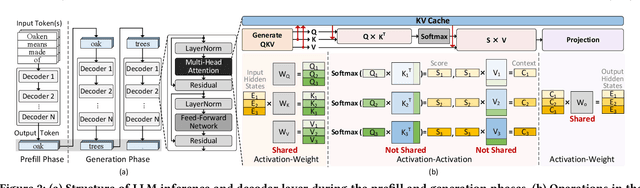
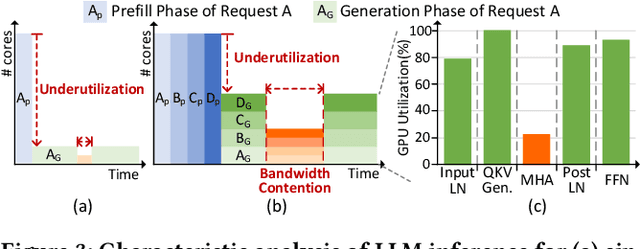
Modern Large Language Model serving system batches multiple requests to achieve high throughput, while batching attention operations is challenging, rendering memory bandwidth a critical bottleneck. The community relies on high-end GPUs with multiple high-bandwidth memory channels. Unfortunately, HBM's high bandwidth often comes at the expense of limited memory capacity, which reduces core utilization and increases costs. Recent advancements enabling longer contexts for LLMs have substantially increased the key-value cache size, further intensifying the pressures on memory capacity. The literature has explored KV cache quantization techniques, which commonly use low bitwidth for most values, selectively using higher bitwidth for outlier values. While this approach helps achieve high accuracy and low bitwidth simultaneously, it comes with the limitation that cost for online outlier detection is excessively high, negating the advantages. We propose Oaken, an acceleration solution that achieves high accuracy and high performance simultaneously through co-designing algorithm and hardware. To effectively find a sweet spot in the accuracy-performance trade-off space of KV cache quantization, Oaken employs an online-offline hybrid approach, setting outlier thresholds offline, which are then used to determine the quantization scale online. To translate the proposed algorithmic technique into tangible performance gains, Oaken also comes with custom quantization engines and memory management units that can be integrated with any LLM accelerators. We built an Oaken accelerator on top of an LLM accelerator, LPU, and conducted a comprehensive evaluation. Our experiments show that for a batch size of 256, Oaken achieves up to 1.58x throughput improvement over NVIDIA A100 GPU, incurring a minimal accuracy loss of only 0.54\% on average, compared to state-of-the-art KV cache quantization techniques.
Gradient-free Decoder Inversion in Latent Diffusion Models
Sep 27, 2024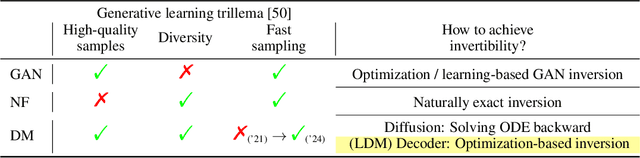
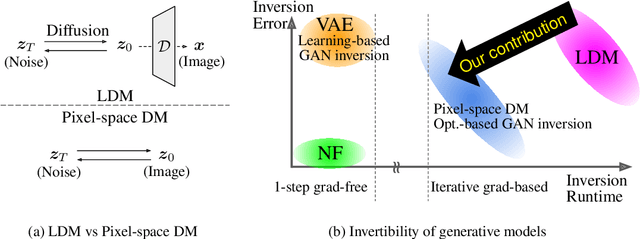
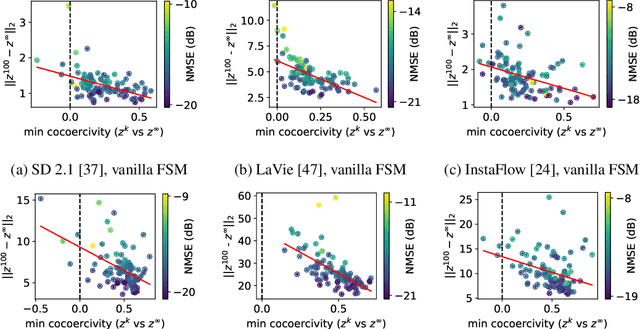
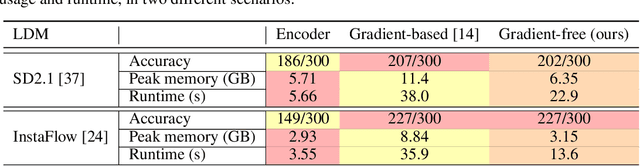
In latent diffusion models (LDMs), denoising diffusion process efficiently takes place on latent space whose dimension is lower than that of pixel space. Decoder is typically used to transform the representation in latent space to that in pixel space. While a decoder is assumed to have an encoder as an accurate inverse, exact encoder-decoder pair rarely exists in practice even though applications often require precise inversion of decoder. Prior works for decoder inversion in LDMs employed gradient descent inspired by inversions of generative adversarial networks. However, gradient-based methods require larger GPU memory and longer computation time for larger latent space. For example, recent video LDMs can generate more than 16 frames, but GPUs with 24 GB memory can only perform gradient-based decoder inversion for 4 frames. Here, we propose an efficient gradient-free decoder inversion for LDMs, which can be applied to diverse latent models. Theoretical convergence property of our proposed inversion has been investigated not only for the forward step method, but also for the inertial Krasnoselskii-Mann (KM) iterations under mild assumption on cocoercivity that is satisfied by recent LDMs. Our proposed gradient-free method with Adam optimizer and learning rate scheduling significantly reduced computation time and memory usage over prior gradient-based methods and enabled efficient computation in applications such as noise-space watermarking while achieving comparable error levels.
Adaptive Selection of Sampling-Reconstruction in Fourier Compressed Sensing
Sep 19, 2024Compressed sensing (CS) has emerged to overcome the inefficiency of Nyquist sampling. However, traditional optimization-based reconstruction is slow and can not yield an exact image in practice. Deep learning-based reconstruction has been a promising alternative to optimization-based reconstruction, outperforming it in accuracy and computation speed. Finding an efficient sampling method with deep learning-based reconstruction, especially for Fourier CS remains a challenge. Existing joint optimization of sampling-reconstruction works ($\mathcal{H}_1$) optimize the sampling mask but have low potential as it is not adaptive to each data point. Adaptive sampling ($\mathcal{H}_2$) has also disadvantages of difficult optimization and Pareto sub-optimality. Here, we propose a novel adaptive selection of sampling-reconstruction ($\mathcal{H}_{1.5}$) framework that selects the best sampling mask and reconstruction network for each input data. We provide theorems that our method has a higher potential than $\mathcal{H}_1$ and effectively solves the Pareto sub-optimality problem in sampling-reconstruction by using separate reconstruction networks for different sampling masks. To select the best sampling mask, we propose to quantify the high-frequency Bayesian uncertainty of the input, using a super-resolution space generation model. Our method outperforms joint optimization of sampling-reconstruction ($\mathcal{H}_1$) and adaptive sampling ($\mathcal{H}_2$) by achieving significant improvements on several Fourier CS problems.
On Exact Inversion of DPM-Solvers
Nov 30, 2023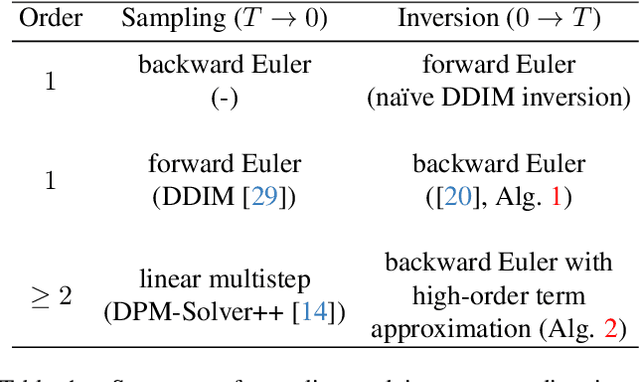
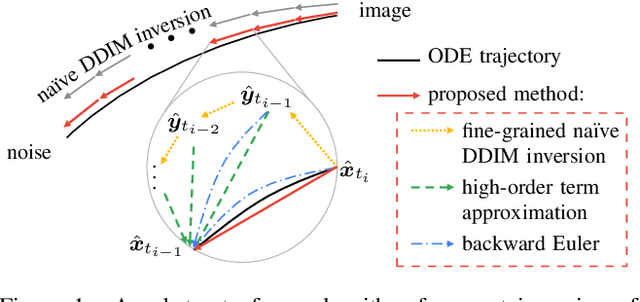
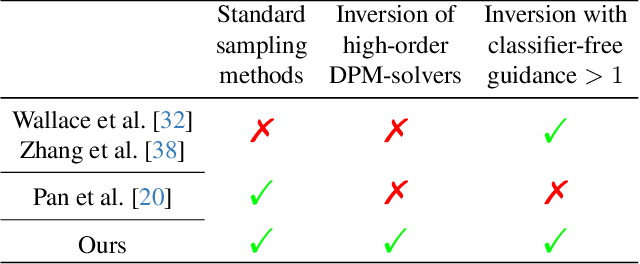
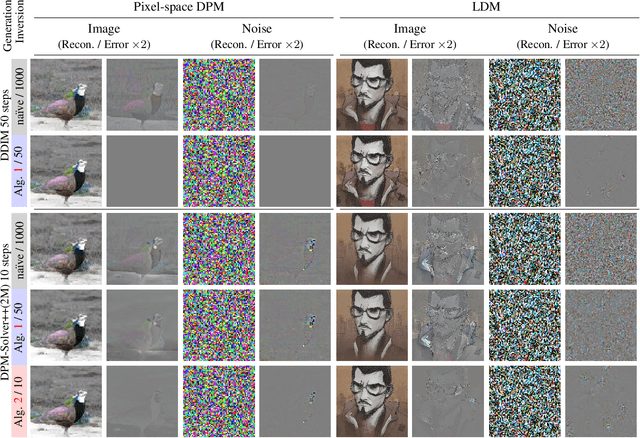
Diffusion probabilistic models (DPMs) are a key component in modern generative models. DPM-solvers have achieved reduced latency and enhanced quality significantly, but have posed challenges to find the exact inverse (i.e., finding the initial noise from the given image). Here we investigate the exact inversions for DPM-solvers and propose algorithms to perform them when samples are generated by the first-order as well as higher-order DPM-solvers. For each explicit denoising step in DPM-solvers, we formulated the inversions using implicit methods such as gradient descent or forward step method to ensure the robustness to large classifier-free guidance unlike the prior approach using fixed-point iteration. Experimental results demonstrated that our proposed exact inversion methods significantly reduced the error of both image and noise reconstructions, greatly enhanced the ability to distinguish invisible watermarks and well prevented unintended background changes consistently during image editing. Project page: \url{https://smhongok.github.io/inv-dpm.html}.
Neural Diffeomorphic Non-uniform B-spline Flows
Apr 11, 2023Normalizing flows have been successfully modeling a complex probability distribution as an invertible transformation of a simple base distribution. However, there are often applications that require more than invertibility. For instance, the computation of energies and forces in physics requires the second derivatives of the transformation to be well-defined and continuous. Smooth normalizing flows employ infinitely differentiable transformation, but with the price of slow non-analytic inverse transforms. In this work, we propose diffeomorphic non-uniform B-spline flows that are at least twice continuously differentiable while bi-Lipschitz continuous, enabling efficient parametrization while retaining analytic inverse transforms based on a sufficient condition for diffeomorphism. Firstly, we investigate the sufficient condition for Ck-2-diffeomorphic non-uniform kth-order B-spline transformations. Then, we derive an analytic inverse transformation of the non-uniform cubic B-spline transformation for neural diffeomorphic non-uniform B-spline flows. Lastly, we performed experiments on solving the force matching problem in Boltzmann generators, demonstrating that our C2-diffeomorphic non-uniform B-spline flows yielded solutions better than previous spline flows and faster than smooth normalizing flows. Our source code is publicly available at https://github.com/smhongok/Non-uniform-B-spline-Flow.
On the Robustness of Normalizing Flows for Inverse Problems in Imaging
Dec 08, 2022



Conditional normalizing flows can generate diverse image samples for solving inverse problems. Most normalizing flows for inverse problems in imaging employ the conditional affine coupling layer that can generate diverse images quickly. However, unintended severe artifacts are occasionally observed in the output of them. In this work, we address this critical issue by investigating the origins of these artifacts and proposing the conditions to avoid them. First of all, we empirically and theoretically reveal that these problems are caused by ``exploding variance'' in the conditional affine coupling layer for certain out-of-distribution (OOD) conditional inputs. Then, we further validated that the probability of causing erroneous artifacts in pixels is highly correlated with a Mahalanobis distance-based OOD score for inverse problems in imaging. Lastly, based on our investigations, we propose a remark to avoid exploding variance and then based on it, we suggest a simple remedy that substitutes the affine coupling layers with the modified rational quadratic spline coupling layers in normalizing flows, to encourage the robustness of generated image samples. Our experimental results demonstrated that our suggested methods effectively suppressed critical artifacts occurring in normalizing flows for super-resolution space generation and low-light image enhancement without compromising performance.
Efficient Single-Image Depth Estimation on Mobile Devices, Mobile AI & AIM 2022 Challenge: Report
Nov 07, 2022

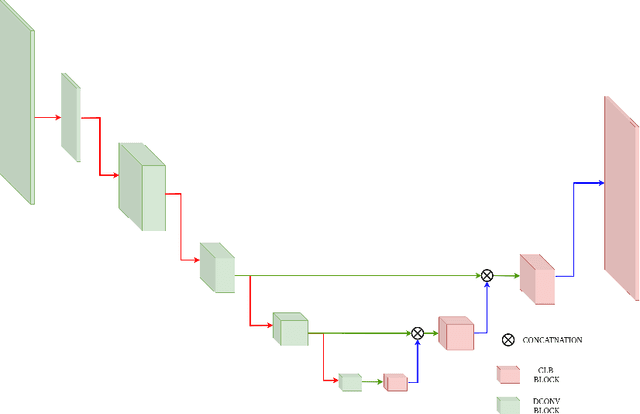
Various depth estimation models are now widely used on many mobile and IoT devices for image segmentation, bokeh effect rendering, object tracking and many other mobile tasks. Thus, it is very crucial to have efficient and accurate depth estimation models that can run fast on low-power mobile chipsets. In this Mobile AI challenge, the target was to develop deep learning-based single image depth estimation solutions that can show a real-time performance on IoT platforms and smartphones. For this, the participants used a large-scale RGB-to-depth dataset that was collected with the ZED stereo camera capable to generated depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the Raspberry Pi 4 platform, where the developed solutions were able to generate VGA resolution depth maps at up to 27 FPS while achieving high fidelity results. All models developed in the challenge are also compatible with any Android or Linux-based mobile devices, their detailed description is provided in this paper.