 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-free Decoder Inversion in Latent Diffusion Models
Paper and Code
Sep 27, 2024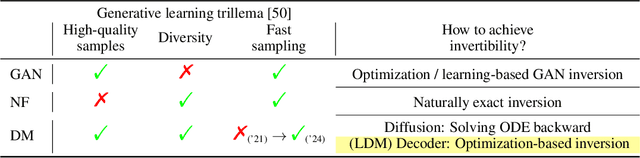
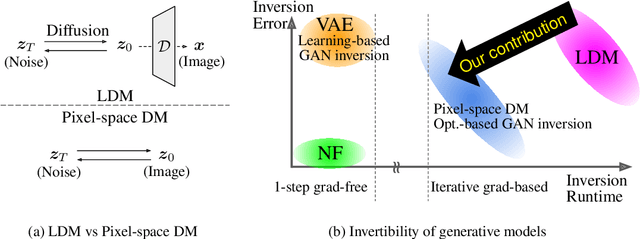
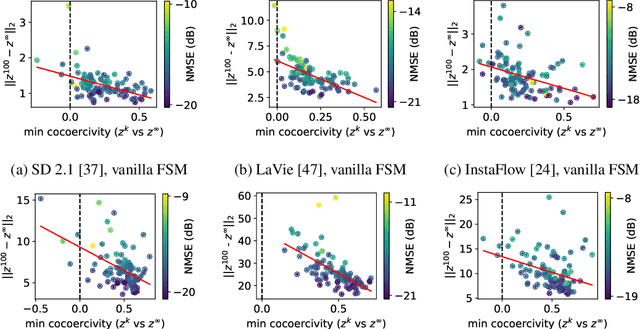
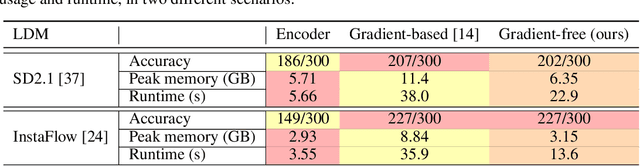
In latent diffusion models (LDMs), denoising diffusion process efficiently takes place on latent space whose dimension is lower than that of pixel space. Decoder is typically used to transform the representation in latent space to that in pixel space. While a decoder is assumed to have an encoder as an accurate inverse, exact encoder-decoder pair rarely exists in practice even though applications often require precise inversion of decoder. Prior works for decoder inversion in LDMs employed gradient descent inspired by inversions of generative adversarial networks. However, gradient-based methods require larger GPU memory and longer computation time for larger latent space. For example, recent video LDMs can generate more than 16 frames, but GPUs with 24 GB memory can only perform gradient-based decoder inversion for 4 frames. Here, we propose an efficient gradient-free decoder inversion for LDMs, which can be applied to diverse latent models. Theoretical convergence property of our proposed inversion has been investigated not only for the forward step method, but also for the inertial Krasnoselskii-Mann (KM) iterations under mild assumption on cocoercivity that is satisfied by recent LDMs. Our proposed gradient-free method with Adam optimizer and learning rate scheduling significantly reduced computation time and memory usage over prior gradient-based methods and enabled efficient computation in applications such as noise-space watermarking while achieving comparable error levels.