 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriadic Dynamics Aware Diffusion Posterior Sampling for Inverse Problems: Optimizing Guidance and Stochasticity Schedules
May 26, 2026Generative posterior sampling using diffusion models has emerged as a dominant paradigm for solving inverse problems in imaging, which usually consists of three main components: data consistency (DC) guidance, classifier-free guidance (CFG) and stochasticity. While prior arts have focused on how to develop each or all components, less attention has given to how to schedule them, leading to heuristically fixed or partially adjusted suboptimal schedules. In this work, we argue that the interactions among all three components in terms of scheduling are crucial for significantly improved performance in solving inverse problems in imaging. Our analysis shows that aggressive CFG early in sampling conflict with DC guidance, while stochasticity brings the trajectory back to higher-probability regions. Based on these findings, we propose Triadic Dynamics Aware Posterior Sampling (TriPS), which reformulates posterior sampling as a time-varying control problem and optimizes schedules following a triadic trend of decreasing DC and stochasticity scales alongside increasing CFG scale. TriPS achieves this through two strategies: template-based search over functional priors for reliable baseline schedules, and Group Relative Policy Optimization (GRPO)-based reinforcement learning for more flexible temporal curves. Experiments demonstrate TriPS outperforms state-of-the-art baselines in data fidelity and perceptual realism.
Training-free, Perceptually Consistent Low-Resolution Previews with High-Resolution Image for Efficient Workflows of Diffusion Models
Apr 10, 2026Image generative models have become indispensable tools to yield exquisite high-resolution (HR) images for everyone, ranging from general users to professional designers. However, a desired outcome often requires generating a large number of HR images with different prompts and seeds, resulting in high computational cost for both users and service providers. Generating low-resolution (LR) images first could alleviate computational burden, but it is not straightforward how to generate LR images that are perceptually consistent with their HR counterparts. Here, we consider the task of generating high-fidelity LR images, called Previews, that preserve perceptual similarity of their HR counterparts for an efficient workflow, allowing users to identify promising candidates before generating the final HR image. We propose the commutator-zero condition to ensure the LR-HR perceptual consistency for flow matching models, leading to the proposed training-free solution with downsampling matrix selection and commutator-zero guidance. Extensive experiments show that our method can generate LR images with up to 33\% computation reduction while maintaining HR perceptual consistency. When combined with existing acceleration techniques, our method achieves up to 3$\times$ speedup. Moreover, our formulation can be extended to image manipulations, such as warping and translation, demonstrating its generalizability.
Human Interaction-Aware 3D Reconstruction from a Single Image
Apr 07, 2026Reconstructing textured 3D human models from a single image is fundamental for AR/VR and digital human applications. However, existing methods mostly focus on single individuals and thus fail in multi-human scenes, where naive composition of individual reconstructions often leads to artifacts such as unrealistic overlaps, missing geometry in occluded regions, and distorted interactions. These limitations highlight the need for approaches that incorporate group-level context and interaction priors. We introduce a holistic method that explicitly models both group- and instance-level information. To mitigate perspective-induced geometric distortions, we first transform the input into a canonical orthographic space. Our primary component, Human Group-Instance Multi-View Diffusion (HUG-MVD), then generates complete multi-view normals and images by jointly modeling individuals and group context to resolve occlusions and proximity. Subsequently, the Human Group-Instance Geometric Reconstruction (HUG-GR) module optimizes the geometry by leveraging explicit, physics-based interaction priors to enforce physical plausibility and accurately model inter-human contact. Finally, the multi-view images are fused into a high-fidelity texture. Together, these components form our complete framework, HUG3D. Extensive experiments show that HUG3D significantly outperforms both single-human and existing multi-human methods, producing physically plausible, high-fidelity 3D reconstructions of interacting people from a single image. Project page: https://jongheean11.github.io/HUG3D_project
Uncertainty-guided Compositional Alignment with Part-to-Whole Semantic Representativeness in Hyperbolic Vision-Language Models
Mar 23, 2026While Vision-Language Models (VLMs) have achieved remarkable performance, their Euclidean embeddings remain limited in capturing hierarchical relationships such as part-to-whole or parent-child structures, and often face challenges in multi-object compositional scenarios. Hyperbolic VLMs mitigate this issue by better preserving hierarchical structures and modeling part-whole relations (i.e., whole scene and its part images) through entailment. However, existing approaches do not model that each part has a different level of semantic representativeness to the whole. We propose UNcertainty-guided Compositional Hyperbolic Alignment (UNCHA) for enhancing hyperbolic VLMs. UNCHA models part-to-whole semantic representativeness with hyperbolic uncertainty, by assigning lower uncertainty to more representative parts and higher uncertainty to less representative ones for the whole scene. This representativeness is then incorporated into the contrastive objective with uncertainty-guided weights. Finally, the uncertainty is further calibrated with an entailment loss regularized by entropy-based term. With the proposed losses, UNCHA learns hyperbolic embeddings with more accurate part-whole ordering, capturing the underlying compositional structure in an image and improving its understanding of complex multi-object scenes. UNCHA achieves state-of-the-art performance on zero-shot classification, retrieval, and multi-label classification benchmarks. Our code and models are available at: https://github.com/jeeit17/UNCHA.git.
AdaRadar: Rate Adaptive Spectral Compression for Radar-based Perception
Mar 18, 2026Radar is a critical perception modality in autonomous driving systems due to its all-weather characteristics and ability to measure range and Doppler velocity. However, the sheer volume of high-dimensional raw radar data saturates the communication link to the computing engine (e.g., an NPU), which is often a low-bandwidth interface with data rate provisioned only for a few low-resolution range-Doppler frames. A generalized codec for utilizing high-dimensional radar data is notably absent, while existing image-domain approaches are unsuitable, as they typically operate at fixed compression ratios and fail to adapt to varying or adversarial conditions. In light of this, we propose radar data compression with adaptive feedback. It dynamically adjusts the compression ratio by performing gradient descent from the proxy gradient of detection confidence with respect to the compression rate. We employ a zeroth-order gradient approximation as it enables gradient computation even with non-differentiable core operations--pruning and quantization. This also avoids transmitting the gradient tensors over the band-limited link, which, if estimated, would be as large as the original radar data. In addition, we have found that radar feature maps are heavily concentrated on a few frequency components. Thus, we apply the discrete cosine transform to the radar data cubes and selectively prune out the coefficients effectively. We preserve the dynamic range of each radar patch through scaled quantization. Combining those techniques, our proposed online adaptive compression scheme achieves over 100x feature size reduction at minimal performance drop (~1%p). We validate our results on the RADIal, CARRADA, and Radatron datasets.
Unlearning the Unpromptable: Prompt-free Instance Unlearning in Diffusion Models
Mar 12, 2026Machine unlearning aims to remove specific outputs from trained models, often at the concept level, such as forgetting all occurrences of a particular celebrity or filtering content via text prompts. However, many undesired outputs, such as an individual's face or generations culturally or factually misinterpreted, cannot often be specified by text prompts. We address this underexplored setting of instance unlearning for outputs that are undesired but unpromptable, where the goal is to forget target outputs selectively while preserving the rest. To this end, we introduce an effective surrogate-based unlearning method that leverages image editing, timestep-aware weighting, and gradient surgery to guide trained diffusion models toward forgetting specific outputs. Experiments on conditional (Stable Diffusion 3) and unconditional (DDPM-CelebA) diffusion models demonstrate that our prompt-free method uniquely unlearns unpromptable outputs, such as faces and culturally inaccurate depictions, with preserved integrity, unlike prompt-based and prompt-free baselines. Our proposed method would serve as a practical hotfix for diffusion model providers to ensure privacy protection and ethical compliance.
DiffBMP: Differentiable Rendering with Bitmap Primitives
Feb 26, 2026We introduce DiffBMP, a scalable and efficient differentiable rendering engine for a collection of bitmap images. Our work addresses a limitation that traditional differentiable renderers are constrained to vector graphics, given that most images in the world are bitmaps. Our core contribution is a highly parallelized rendering pipeline, featuring a custom CUDA implementation for calculating gradients. This system can, for example, optimize the position, rotation, scale, color, and opacity of thousands of bitmap primitives all in under 1 min using a consumer GPU. We employ and validate several techniques to facilitate the optimization: soft rasterization via Gaussian blur, structure-aware initialization, noisy canvas, and specialized losses/heuristics for videos or spatially constrained images. We demonstrate DiffBMP is not just an isolated tool, but a practical one designed to integrate into creative workflows. It supports exporting compositions to a native, layered file format, and the entire framework is publicly accessible via an easy-to-hack Python package.
Continual Multiple Instance Learning with Enhanced Localization for Histopathological Whole Slide Image Analysis
Jul 03, 2025
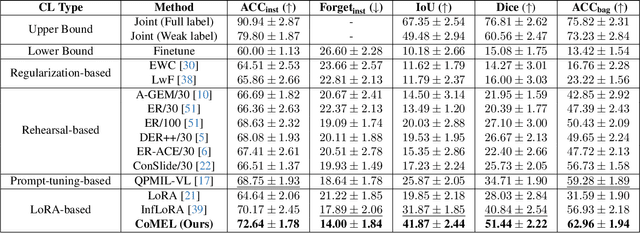
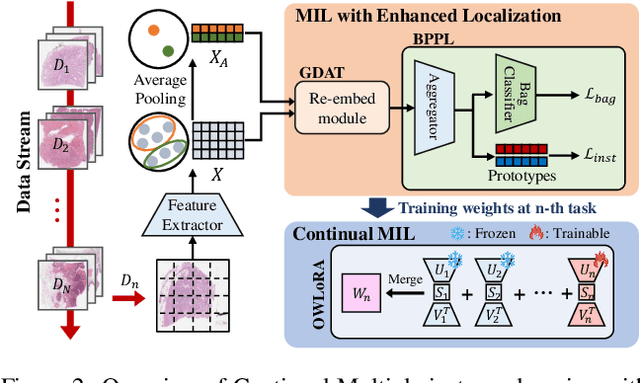
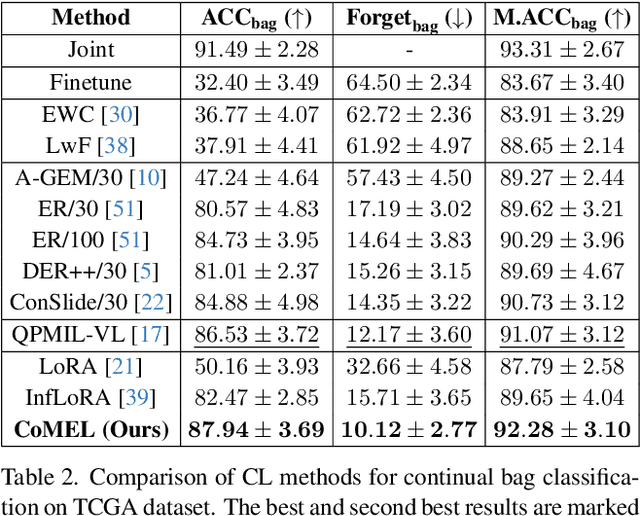
Multiple instance learning (MIL) significantly reduced annotation costs via bag-level weak labels for large-scale images, such as histopathological whole slide images (WSIs). However, its adaptability to continual tasks with minimal forgetting has been rarely explored, especially on instance classification for localization. Weakly incremental learning for semantic segmentation has been studied for continual localization, but it focused on natural images, leveraging global relationships among hundreds of small patches (e.g., $16 \times 16$) using pre-trained models. This approach seems infeasible for MIL localization due to enormous amounts ($\sim 10^5$) of large patches (e.g., $256 \times 256$) and no available global relationships such as cancer cells. To address these challenges, we propose Continual Multiple Instance Learning with Enhanced Localization (CoMEL), an MIL framework for both localization and adaptability with minimal forgetting. CoMEL consists of (1) Grouped Double Attention Transformer (GDAT) for efficient instance encoding, (2) Bag Prototypes-based Pseudo-Labeling (BPPL) for reliable instance pseudo-labeling, and (3) Orthogonal Weighted Low-Rank Adaptation (OWLoRA) to mitigate forgetting in both bag and instance classification. Extensive experiments on three public WSI datasets demonstrate superior performance of CoMEL, outperforming the prior arts by up to $11.00\%$ in bag-level accuracy and up to $23.4\%$ in localization accuracy under the continual MIL setup.
Self-Cascaded Diffusion Models for Arbitrary-Scale Image Super-Resolution
Jun 09, 2025Arbitrary-scale image super-resolution aims to upsample images to any desired resolution, offering greater flexibility than traditional fixed-scale super-resolution. Recent approaches in this domain utilize regression-based or generative models, but many of them are a single-stage upsampling process, which may be challenging to learn across a wide, continuous distribution of scaling factors. Progressive upsampling strategies have shown promise in mitigating this issue, yet their integration with diffusion models for flexible upscaling remains underexplored. Here, we present CasArbi, a novel self-cascaded diffusion framework for arbitrary-scale image super-resolution. CasArbi meets the varying scaling demands by breaking them down into smaller sequential factors and progressively enhancing the image resolution at each step with seamless transitions for arbitrary scales. Our novel coordinate-guided residual diffusion model allows for the learning of continuous image representations while enabling efficient diffusion sampling. Extensive experiments demonstrate that our CasArbi outperforms prior arts in both perceptual and distortion performance metrics across diverse arbitrary-scale super-resolution benchmarks.
GeoMan: Temporally Consistent Human Geometry Estimation using Image-to-Video Diffusion
May 29, 2025Estimating accurate and temporally consistent 3D human geometry from videos is a challenging problem in computer vision. Existing methods, primarily optimized for single images, often suffer from temporal inconsistencies and fail to capture fine-grained dynamic details. To address these limitations, we present GeoMan, a novel architecture designed to produce accurate and temporally consistent depth and normal estimations from monocular human videos. GeoMan addresses two key challenges: the scarcity of high-quality 4D training data and the need for metric depth estimation to accurately model human size. To overcome the first challenge, GeoMan employs an image-based model to estimate depth and normals for the first frame of a video, which then conditions a video diffusion model, reframing video geometry estimation task as an image-to-video generation problem. This design offloads the heavy lifting of geometric estimation to the image model and simplifies the video model's role to focus on intricate details while using priors learned from large-scale video datasets. Consequently, GeoMan improves temporal consistency and generalizability while requiring minimal 4D training data. To address the challenge of accurate human size estimation, we introduce a root-relative depth representation that retains critical human-scale details and is easier to be estimated from monocular inputs, overcoming the limitations of traditional affine-invariant and metric depth representations. GeoMan achieves state-of-the-art performance in both qualitative and quantitative evaluations, demonstrating its effectiveness in overcoming longstanding challenges in 3D human geometry estimation from videos.