 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Geometrical Properties of Text Token Embeddings for Strong Semantic Binding in Text-to-Image Generation
Mar 29, 2025Text-to-Image (T2I) models often suffer from text-image misalignment in complex scenes involving multiple objects and attributes. Semantic binding aims to mitigate this issue by accurately associating the generated attributes and objects with their corresponding noun phrases (NPs). Existing methods rely on text or latent optimizations, yet the factors influencing semantic binding remain underexplored. Here we investigate the geometrical properties of text token embeddings and their cross-attention (CA) maps. We empirically and theoretically analyze that the geometrical properties of token embeddings, specifically both angular distances and norms, play a crucial role in CA map differentiation. Then, we propose \textbf{TeeMo}, a training-free text embedding-aware T2I framework with strong semantic binding. TeeMo consists of Causality-Aware Projection-Out (CAPO) for distinct inter-NP CA maps and Adaptive Token Mixing (ATM) with our loss to enhance inter-NP separation while maintaining intra-NP cohesion in CA maps. Extensive experiments confirm TeeMo consistently outperforms prior arts across diverse baselines and datasets.
Efficient Personalization of Quantized Diffusion Model without Backpropagation
Mar 19, 2025Diffusion models have shown remarkable performance in image synthesis, but they demand extensive computational and memory resources for training, fine-tuning and inference. Although advanced quantization techniques have successfully minimized memory usage for inference, training and fine-tuning these quantized models still require large memory possibly due to dequantization for accurate computation of gradients and/or backpropagation for gradient-based algorithms. However, memory-efficient fine-tuning is particularly desirable for applications such as personalization that often must be run on edge devices like mobile phones with private data. In this work, we address this challenge by quantizing a diffusion model with personalization via Textual Inversion and by leveraging a zeroth-order optimization on personalization tokens without dequantization so that it does not require gradient and activation storage for backpropagation that consumes considerable memory. Since a gradient estimation using zeroth-order optimization is quite noisy for a single or a few images in personalization, we propose to denoise the estimated gradient by projecting it onto a subspace that is constructed with the past history of the tokens, dubbed Subspace Gradient. In addition, we investigated the influence of text embedding in image generation, leading to our proposed time steps sampling, dubbed Partial Uniform Timestep Sampling for sampling with effective diffusion timesteps. Our method achieves comparable performance to prior methods in image and text alignment scores for personalizing Stable Diffusion with only forward passes while reducing training memory demand up to $8.2\times$.
Skrr: Skip and Re-use Text Encoder Layers for Memory Efficient Text-to-Image Generation
Feb 12, 2025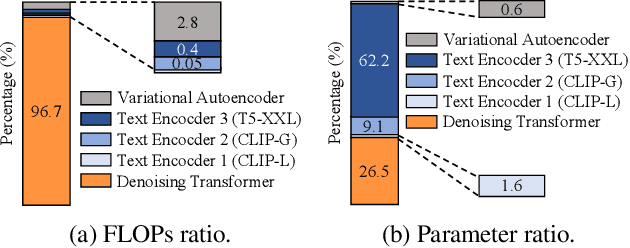
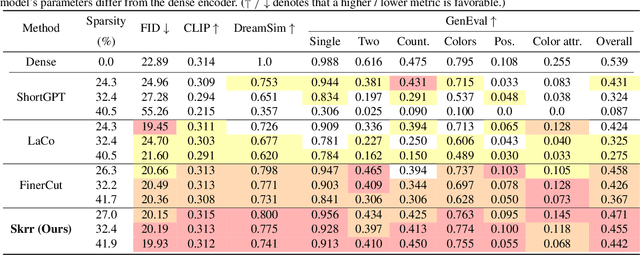
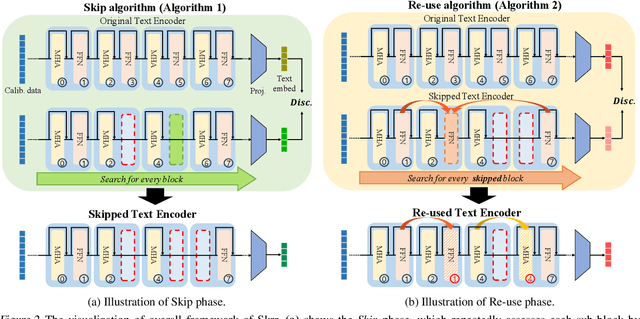
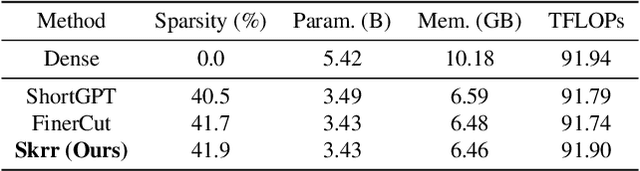
Large-scale text encoders in text-to-image (T2I) diffusion models have demonstrated exceptional performance in generating high-quality images from textual prompts. Unlike denoising modules that rely on multiple iterative steps, text encoders require only a single forward pass to produce text embeddings. However, despite their minimal contribution to total inference time and floating-point operations (FLOPs), text encoders demand significantly higher memory usage, up to eight times more than denoising modules. To address this inefficiency, we propose Skip and Re-use layers (Skrr), a simple yet effective pruning strategy specifically designed for text encoders in T2I diffusion models. Skrr exploits the inherent redundancy in transformer blocks by selectively skipping or reusing certain layers in a manner tailored for T2I tasks, thereby reducing memory consumption without compromising performance. Extensive experiments demonstrate that Skrr maintains image quality comparable to the original model even under high sparsity levels, outperforming existing blockwise pruning methods. Furthermore, Skrr achieves state-of-the-art memory efficiency while preserving performance across multiple evaluation metrics, including the FID, CLIP, DreamSim, and GenEval scores.
INTRA: Interaction Relationship-aware Weakly Supervised Affordance Grounding
Sep 10, 2024



Affordance denotes the potential interactions inherent in objects. The perception of affordance can enable intelligent agents to navigate and interact with new environments efficiently. Weakly supervised affordance grounding teaches agents the concept of affordance without costly pixel-level annotations, but with exocentric images. Although recent advances in weakly supervised affordance grounding yielded promising results, there remain challenges including the requirement for paired exocentric and egocentric image dataset, and the complexity in grounding diverse affordances for a single object. To address them, we propose INTeraction Relationship-aware weakly supervised Affordance grounding (INTRA). Unlike prior arts, INTRA recasts this problem as representation learning to identify unique features of interactions through contrastive learning with exocentric images only, eliminating the need for paired datasets. Moreover, we leverage vision-language model embeddings for performing affordance grounding flexibly with any text, designing text-conditioned affordance map generation to reflect interaction relationship for contrastive learning and enhancing robustness with our text synonym augmentation. Our method outperformed prior arts on diverse datasets such as AGD20K, IIT-AFF, CAD and UMD. Additionally, experimental results demonstrate that our method has remarkable domain scalability for synthesized images / illustrations and is capable of performing affordance grounding for novel interactions and objects.
BeyondScene: Higher-Resolution Human-Centric Scene Generation With Pretrained Diffusion
Apr 06, 2024
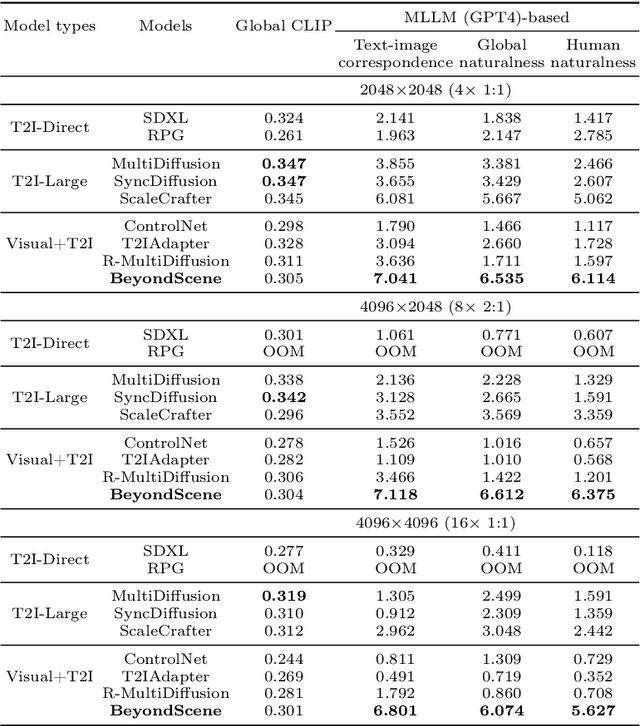

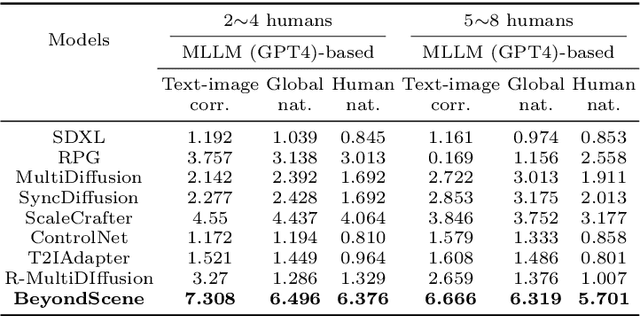
Generating higher-resolution human-centric scenes with details and controls remains a challenge for existing text-to-image diffusion models. This challenge stems from limited training image size, text encoder capacity (limited tokens), and the inherent difficulty of generating complex scenes involving multiple humans. While current methods attempted to address training size limit only, they often yielded human-centric scenes with severe artifacts. We propose BeyondScene, a novel framework that overcomes prior limitations, generating exquisite higher-resolution (over 8K) human-centric scenes with exceptional text-image correspondence and naturalness using existing pretrained diffusion models. BeyondScene employs a staged and hierarchical approach to initially generate a detailed base image focusing on crucial elements in instance creation for multiple humans and detailed descriptions beyond token limit of diffusion model, and then to seamlessly convert the base image to a higher-resolution output, exceeding training image size and incorporating details aware of text and instances via our novel instance-aware hierarchical enlargement process that consists of our proposed high-frequency injected forward diffusion and adaptive joint diffusion. BeyondScene surpasses existing methods in terms of correspondence with detailed text descriptions and naturalness, paving the way for advanced applications in higher-resolution human-centric scene creation beyond the capacity of pretrained diffusion models without costly retraining. Project page: https://janeyeon.github.io/beyond-scene.
Detailed Human-Centric Text Description-Driven Large Scene Synthesis
Nov 30, 2023
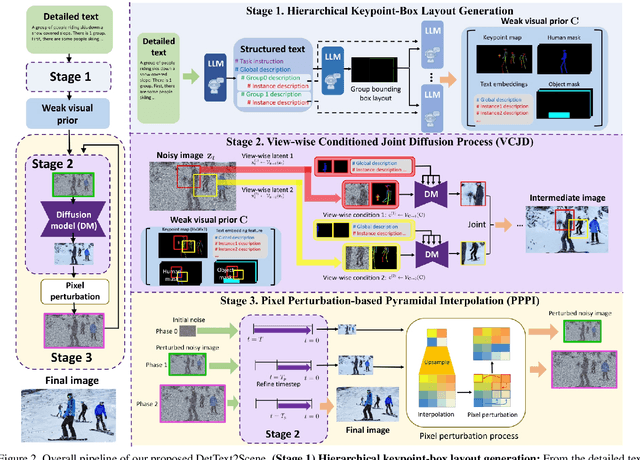


Text-driven large scene image synthesis has made significant progress with diffusion models, but controlling it is challenging. While using additional spatial controls with corresponding texts has improved the controllability of large scene synthesis, it is still challenging to faithfully reflect detailed text descriptions without user-provided controls. Here, we propose DetText2Scene, a novel text-driven large-scale image synthesis with high faithfulness, controllability, and naturalness in a global context for the detailed human-centric text description. Our DetText2Scene consists of 1) hierarchical keypoint-box layout generation from the detailed description by leveraging large language model (LLM), 2) view-wise conditioned joint diffusion process to synthesize a large scene from the given detailed text with LLM-generated grounded keypoint-box layout and 3) pixel perturbation-based pyramidal interpolation to progressively refine the large scene for global coherence. Our DetText2Scene significantly outperforms prior arts in text-to-large scene synthesis qualitatively and quantitatively, demonstrating strong faithfulness with detailed descriptions, superior controllability, and excellent naturalness in a global context.
DITTO-NeRF: Diffusion-based Iterative Text To Omni-directional 3D Model
Apr 06, 2023The increasing demand for high-quality 3D content creation has motivated the development of automated methods for creating 3D object models from a single image and/or from a text prompt. However, the reconstructed 3D objects using state-of-the-art image-to-3D methods still exhibit low correspondence to the given image and low multi-view consistency. Recent state-of-the-art text-to-3D methods are also limited, yielding 3D samples with low diversity per prompt with long synthesis time. To address these challenges, we propose DITTO-NeRF, a novel pipeline to generate a high-quality 3D NeRF model from a text prompt or a single image. Our DITTO-NeRF consists of constructing high-quality partial 3D object for limited in-boundary (IB) angles using the given or text-generated 2D image from the frontal view and then iteratively reconstructing the remaining 3D NeRF using inpainting latent diffusion model. We propose progressive 3D object reconstruction schemes in terms of scales (low to high resolution), angles (IB angles initially to outer-boundary (OB) later), and masks (object to background boundary) in our DITTO-NeRF so that high-quality information on IB can be propagated into OB. Our DITTO-NeRF outperforms state-of-the-art methods in terms of fidelity and diversity qualitatively and quantitatively with much faster training times than prior arts on image/text-to-3D such as DreamFusion, and NeuralLift-360.