 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-guided Compositional Alignment with Part-to-Whole Semantic Representativeness in Hyperbolic Vision-Language Models
Mar 23, 2026While Vision-Language Models (VLMs) have achieved remarkable performance, their Euclidean embeddings remain limited in capturing hierarchical relationships such as part-to-whole or parent-child structures, and often face challenges in multi-object compositional scenarios. Hyperbolic VLMs mitigate this issue by better preserving hierarchical structures and modeling part-whole relations (i.e., whole scene and its part images) through entailment. However, existing approaches do not model that each part has a different level of semantic representativeness to the whole. We propose UNcertainty-guided Compositional Hyperbolic Alignment (UNCHA) for enhancing hyperbolic VLMs. UNCHA models part-to-whole semantic representativeness with hyperbolic uncertainty, by assigning lower uncertainty to more representative parts and higher uncertainty to less representative ones for the whole scene. This representativeness is then incorporated into the contrastive objective with uncertainty-guided weights. Finally, the uncertainty is further calibrated with an entailment loss regularized by entropy-based term. With the proposed losses, UNCHA learns hyperbolic embeddings with more accurate part-whole ordering, capturing the underlying compositional structure in an image and improving its understanding of complex multi-object scenes. UNCHA achieves state-of-the-art performance on zero-shot classification, retrieval, and multi-label classification benchmarks. Our code and models are available at: https://github.com/jeeit17/UNCHA.git.
K-EXAONE Technical Report
Jan 05, 2026This technical report presents K-EXAONE, a large-scale multilingual language model developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
B-RIGHT: Benchmark Re-evaluation for Integrity in Generalized Human-Object Interaction Testing
Jan 28, 2025Human-object interaction (HOI) is an essential problem in artificial intelligence (AI) which aims to understand the visual world that involves complex relationships between humans and objects. However, current benchmarks such as HICO-DET face the following limitations: (1) severe class imbalance and (2) varying number of train and test sets for certain classes. These issues can potentially lead to either inflation or deflation of model performance during evaluation, ultimately undermining the reliability of evaluation scores. In this paper, we propose a systematic approach to develop a new class-balanced dataset, Benchmark Re-evaluation for Integrity in Generalized Human-object Interaction Testing (B-RIGHT), that addresses these imbalanced problems. B-RIGHT achieves class balance by leveraging balancing algorithm and automated generation-and-filtering processes, ensuring an equal number of instances for each HOI class. Furthermore, we design a balanced zero-shot test set to systematically evaluate models on unseen scenario. Re-evaluating existing models using B-RIGHT reveals substantial the reduction of score variance and changes in performance rankings compared to conventional HICO-DET. Our experiments demonstrate that evaluation under balanced conditions ensure more reliable and fair model comparisons.
Contribution-based Low-Rank Adaptation with Pre-training Model for Real Image Restoration
Aug 02, 2024



Recently, pre-trained model and efficient parameter tuning have achieved remarkable success in natural language processing and high-level computer vision with the aid of masked modeling and prompt tuning. In low-level computer vision, however, there have been limited investigations on pre-trained models and even efficient fine-tuning strategy has not yet been explored despite its importance and benefit in various real-world tasks such as alleviating memory inflation issue when integrating new tasks on AI edge devices. Here, we propose a novel efficient parameter tuning approach dubbed contribution-based low-rank adaptation (CoLoRA) for multiple image restorations along with effective pre-training method with random order degradations (PROD). Unlike prior arts that tune all network parameters, our CoLoRA effectively fine-tunes small amount of parameters by leveraging LoRA (low-rank adaptation) for each new vision task with our contribution-based method to adaptively determine layer by layer capacity for that task to yield comparable performance to full tuning. Furthermore, our PROD strategy allows to extend the capability of pre-trained models with improved performance as well as robustness to bridge synthetic pre-training and real-world fine-tuning. Our CoLoRA with PROD has demonstrated its superior performance in various image restoration tasks across diverse degradation types on both synthetic and real-world datasets for known and novel tasks.
BeyondScene: Higher-Resolution Human-Centric Scene Generation With Pretrained Diffusion
Apr 06, 2024
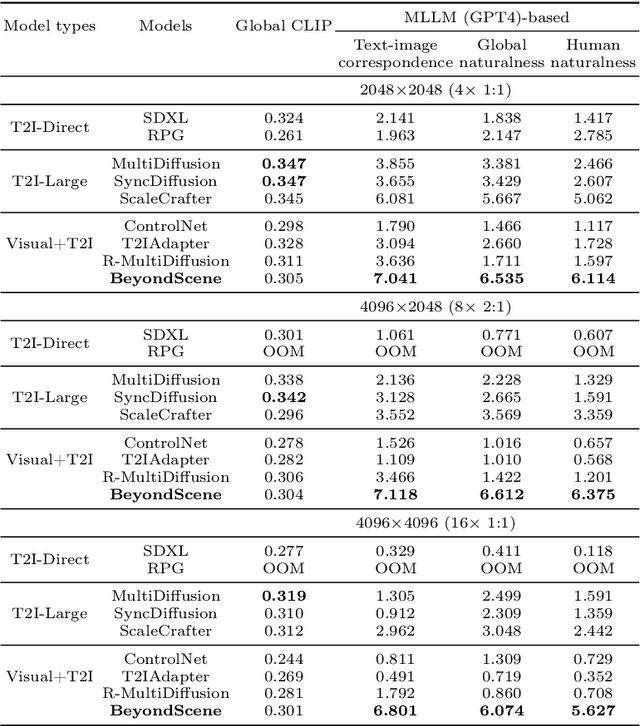

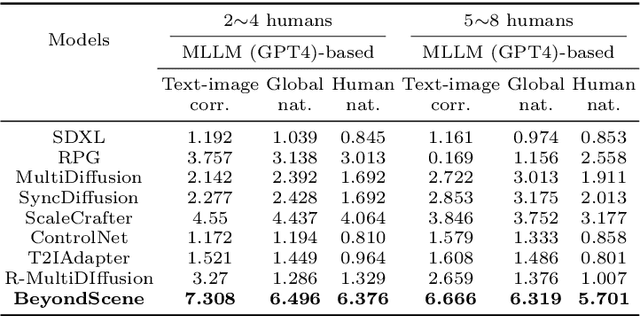
Generating higher-resolution human-centric scenes with details and controls remains a challenge for existing text-to-image diffusion models. This challenge stems from limited training image size, text encoder capacity (limited tokens), and the inherent difficulty of generating complex scenes involving multiple humans. While current methods attempted to address training size limit only, they often yielded human-centric scenes with severe artifacts. We propose BeyondScene, a novel framework that overcomes prior limitations, generating exquisite higher-resolution (over 8K) human-centric scenes with exceptional text-image correspondence and naturalness using existing pretrained diffusion models. BeyondScene employs a staged and hierarchical approach to initially generate a detailed base image focusing on crucial elements in instance creation for multiple humans and detailed descriptions beyond token limit of diffusion model, and then to seamlessly convert the base image to a higher-resolution output, exceeding training image size and incorporating details aware of text and instances via our novel instance-aware hierarchical enlargement process that consists of our proposed high-frequency injected forward diffusion and adaptive joint diffusion. BeyondScene surpasses existing methods in terms of correspondence with detailed text descriptions and naturalness, paving the way for advanced applications in higher-resolution human-centric scene creation beyond the capacity of pretrained diffusion models without costly retraining. Project page: https://janeyeon.github.io/beyond-scene.
Improvement in Variational Quantum Algorithms by Measurement Simplification
Dec 11, 2023



Variational Quantum Algorithms (VQAs) are expected to be promising algorithms with quantum advantages that can be run at quantum computers in the close future. In this work, we review simple rules in basic quantum circuits, and propose a simplification method, Measurement Simplification, that simplifies the expression for the measurement of quantum circuit. By the Measurement Simplification, we simplified the specific result expression of VQAs and obtained large improvements in calculation time and required memory size. Here we applied Measurement Simplification to Variational Quantum Linear Solver (VQLS), Variational Quantum Eigensolver (VQE) and other Quantum Machine Learning Algorithms to show an example of speedup in the calculation time and required memory size.
Detailed Human-Centric Text Description-Driven Large Scene Synthesis
Nov 30, 2023
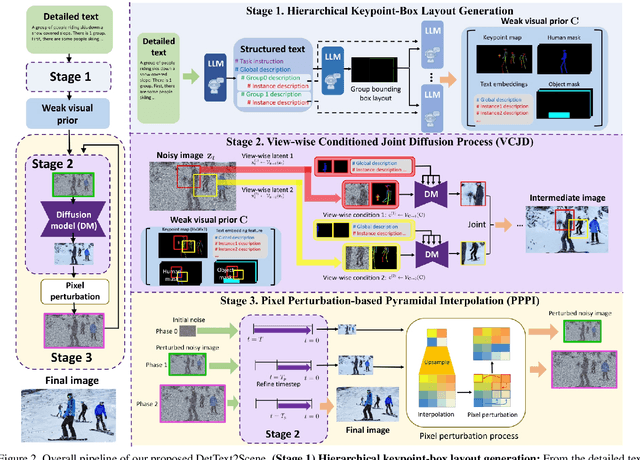


Text-driven large scene image synthesis has made significant progress with diffusion models, but controlling it is challenging. While using additional spatial controls with corresponding texts has improved the controllability of large scene synthesis, it is still challenging to faithfully reflect detailed text descriptions without user-provided controls. Here, we propose DetText2Scene, a novel text-driven large-scale image synthesis with high faithfulness, controllability, and naturalness in a global context for the detailed human-centric text description. Our DetText2Scene consists of 1) hierarchical keypoint-box layout generation from the detailed description by leveraging large language model (LLM), 2) view-wise conditioned joint diffusion process to synthesize a large scene from the given detailed text with LLM-generated grounded keypoint-box layout and 3) pixel perturbation-based pyramidal interpolation to progressively refine the large scene for global coherence. Our DetText2Scene significantly outperforms prior arts in text-to-large scene synthesis qualitatively and quantitatively, demonstrating strong faithfulness with detailed descriptions, superior controllability, and excellent naturalness in a global context.
DITTO-NeRF: Diffusion-based Iterative Text To Omni-directional 3D Model
Apr 06, 2023



The increasing demand for high-quality 3D content creation has motivated the development of automated methods for creating 3D object models from a single image and/or from a text prompt. However, the reconstructed 3D objects using state-of-the-art image-to-3D methods still exhibit low correspondence to the given image and low multi-view consistency. Recent state-of-the-art text-to-3D methods are also limited, yielding 3D samples with low diversity per prompt with long synthesis time. To address these challenges, we propose DITTO-NeRF, a novel pipeline to generate a high-quality 3D NeRF model from a text prompt or a single image. Our DITTO-NeRF consists of constructing high-quality partial 3D object for limited in-boundary (IB) angles using the given or text-generated 2D image from the frontal view and then iteratively reconstructing the remaining 3D NeRF using inpainting latent diffusion model. We propose progressive 3D object reconstruction schemes in terms of scales (low to high resolution), angles (IB angles initially to outer-boundary (OB) later), and masks (object to background boundary) in our DITTO-NeRF so that high-quality information on IB can be propagated into OB. Our DITTO-NeRF outperforms state-of-the-art methods in terms of fidelity and diversity qualitatively and quantitatively with much faster training times than prior arts on image/text-to-3D such as DreamFusion, and NeuralLift-360.