 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Reliability of Cue Conflict and Beyond
Mar 12, 2026Understanding how neural networks rely on visual cues offers a human-interpretable view of their internal decision processes. The cue-conflict benchmark has been influential in probing shape-texture preference and in motivating the insight that stronger, human-like shape bias is often associated with improved in-domain performance. However, we find that the current stylization-based instantiation can yield unstable and ambiguous bias estimates. Specifically, stylization may not reliably instantiate perceptually valid and separable cues nor control their relative informativeness, ratio-based bias can obscure absolute cue sensitivity, and restricting evaluation to preselected classes can distort model predictions by ignoring the full decision space. Together, these factors can confound preference with cue validity, cue balance, and recognizability artifacts. We introduce REFINED-BIAS, an integrated dataset and evaluation framework for reliable and interpretable shape-texture bias diagnosis. REFINED-BIAS constructs balanced, human- and model- recognizable cue pairs using explicit definitions of shape and texture, and measures cue-specific sensitivity over the full label space via a ranking-based metric, enabling fairer cross-model comparisons. Across diverse training regimes and architectures, REFINED-BIAS enables fairer cross-model comparison, more faithful diagnosis of shape and texture biases, and clearer empirical conclusions, resolving inconsistencies that prior cue-conflict evaluations could not reliably disambiguate.
Beyond Spatial Frequency: Pixel-wise Temporal Frequency-based Deepfake Video Detection
Jul 03, 2025We introduce a deepfake video detection approach that exploits pixel-wise temporal inconsistencies, which traditional spatial frequency-based detectors often overlook. Traditional detectors represent temporal information merely by stacking spatial frequency spectra across frames, resulting in the failure to detect temporal artifacts in the pixel plane. Our approach performs a 1D Fourier transform on the time axis for each pixel, extracting features highly sensitive to temporal inconsistencies, especially in areas prone to unnatural movements. To precisely locate regions containing the temporal artifacts, we introduce an attention proposal module trained in an end-to-end manner. Additionally, our joint transformer module effectively integrates pixel-wise temporal frequency features with spatio-temporal context features, expanding the range of detectable forgery artifacts. Our framework represents a significant advancement in deepfake video detection, providing robust performance across diverse and challenging detection scenarios.
Understanding Flatness in Generative Models: Its Role and Benefits
Mar 14, 2025Flat minima, known to enhance generalization and robustness in supervised learning, remain largely unexplored in generative models. In this work, we systematically investigate the role of loss surface flatness in generative models, both theoretically and empirically, with a particular focus on diffusion models. We establish a theoretical claim that flatter minima improve robustness against perturbations in target prior distributions, leading to benefits such as reduced exposure bias -- where errors in noise estimation accumulate over iterations -- and significantly improved resilience to model quantization, preserving generative performance even under strong quantization constraints. We further observe that Sharpness-Aware Minimization (SAM), which explicitly controls the degree of flatness, effectively enhances flatness in diffusion models, whereas other well-known methods such as Stochastic Weight Averaging (SWA) and Exponential Moving Average (EMA), which promote flatness indirectly via ensembling, are less effective. Through extensive experiments on CIFAR-10, LSUN Tower, and FFHQ, we demonstrate that flat minima in diffusion models indeed improves not only generative performance but also robustness.
PRISM: Privacy-Preserving Improved Stochastic Masking for Federated Generative Models
Mar 11, 2025Despite recent advancements in federated learning (FL), the integration of generative models into FL has been limited due to challenges such as high communication costs and unstable training in heterogeneous data environments. To address these issues, we propose PRISM, a FL framework tailored for generative models that ensures (i) stable performance in heterogeneous data distributions and (ii) resource efficiency in terms of communication cost and final model size. The key of our method is to search for an optimal stochastic binary mask for a random network rather than updating the model weights, identifying a sparse subnetwork with high generative performance; i.e., a ``strong lottery ticket''. By communicating binary masks in a stochastic manner, PRISM minimizes communication overhead. This approach, combined with the utilization of maximum mean discrepancy (MMD) loss and a mask-aware dynamic moving average aggregation method (MADA) on the server side, facilitates stable and strong generative capabilities by mitigating local divergence in FL scenarios. Moreover, thanks to its sparsifying characteristic, PRISM yields a lightweight model without extra pruning or quantization, making it ideal for environments such as edge devices. Experiments on MNIST, FMNIST, CelebA, and CIFAR10 demonstrate that PRISM outperforms existing methods, while maintaining privacy with minimal communication costs. PRISM is the first to successfully generate images under challenging non-IID and privacy-preserving FL environments on complex datasets, where previous methods have struggled.
B-RIGHT: Benchmark Re-evaluation for Integrity in Generalized Human-Object Interaction Testing
Jan 28, 2025Human-object interaction (HOI) is an essential problem in artificial intelligence (AI) which aims to understand the visual world that involves complex relationships between humans and objects. However, current benchmarks such as HICO-DET face the following limitations: (1) severe class imbalance and (2) varying number of train and test sets for certain classes. These issues can potentially lead to either inflation or deflation of model performance during evaluation, ultimately undermining the reliability of evaluation scores. In this paper, we propose a systematic approach to develop a new class-balanced dataset, Benchmark Re-evaluation for Integrity in Generalized Human-object Interaction Testing (B-RIGHT), that addresses these imbalanced problems. B-RIGHT achieves class balance by leveraging balancing algorithm and automated generation-and-filtering processes, ensuring an equal number of instances for each HOI class. Furthermore, we design a balanced zero-shot test set to systematically evaluate models on unseen scenario. Re-evaluating existing models using B-RIGHT reveals substantial the reduction of score variance and changes in performance rankings compared to conventional HICO-DET. Our experiments demonstrate that evaluation under balanced conditions ensure more reliable and fair model comparisons.
BF-STVSR: B-Splines and Fourier-Best Friends for High Fidelity Spatial-Temporal Video Super-Resolution
Jan 19, 2025Enhancing low-resolution, low-frame-rate videos to high-resolution, high-frame-rate quality is essential for a seamless user experience, motivating advancements in Continuous Spatial-Temporal Video Super Resolution (C-STVSR). While prior methods employ Implicit Neural Representation (INR) for continuous encoding, they often struggle to capture the complexity of video data, relying on simple coordinate concatenation and pre-trained optical flow network for motion representation. Interestingly, we find that adding position encoding, contrary to common observations, does not improve-and even degrade performance. This issue becomes particularly pronounced when combined with pre-trained optical flow networks, which can limit the model's flexibility. To address these issues, we propose BF-STVSR, a C-STVSR framework with two key modules tailored to better represent spatial and temporal characteristics of video: 1) B-spline Mapper for smooth temporal interpolation, and 2) Fourier Mapper for capturing dominant spatial frequencies. Our approach achieves state-of-the-art PSNR and SSIM performance, showing enhanced spatial details and natural temporal consistency.
Dynamic-Aware Spatio-temporal Representation Learning for Dynamic MRI Reconstruction
Jan 15, 2025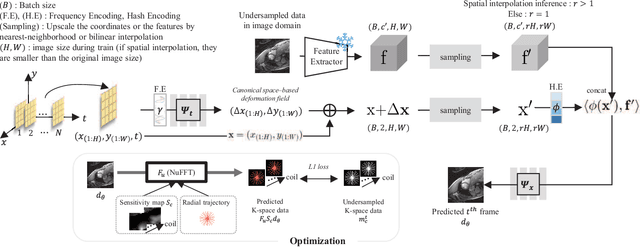
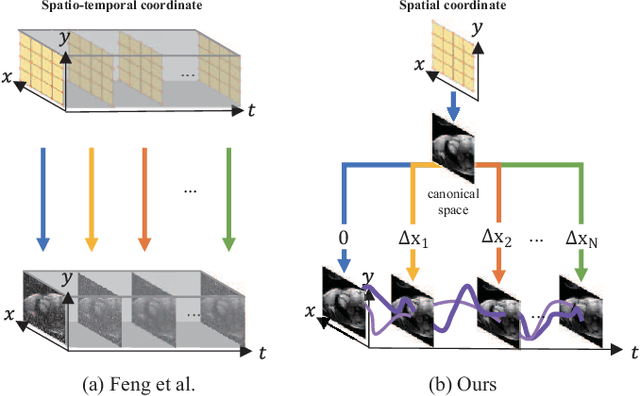

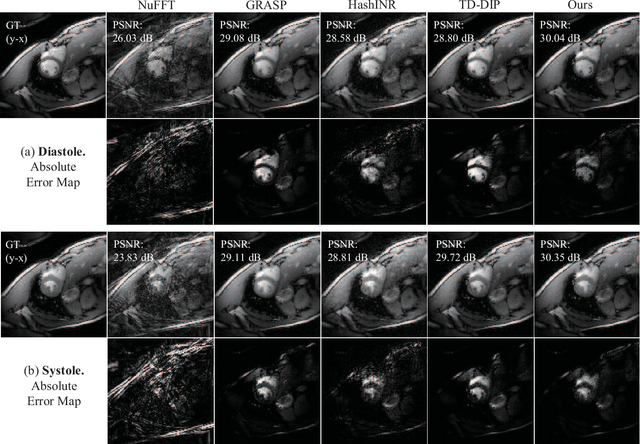
Dynamic MRI reconstruction, one of inverse problems, has seen a surge by the use of deep learning techniques. Especially, the practical difficulty of obtaining ground truth data has led to the emergence of unsupervised learning approaches. A recent promising method among them is implicit neural representation (INR), which defines the data as a continuous function that maps coordinate values to the corresponding signal values. This allows for filling in missing information only with incomplete measurements and solving the inverse problem effectively. Nevertheless, previous works incorporating this method have faced drawbacks such as long optimization time and the need for extensive hyperparameter tuning. To address these issues, we propose Dynamic-Aware INR (DA-INR), an INR-based model for dynamic MRI reconstruction that captures the spatial and temporal continuity of dynamic MRI data in the image domain and explicitly incorporates the temporal redundancy of the data into the model structure. As a result, DA-INR outperforms other models in reconstruction quality even at extreme undersampling ratios while significantly reducing optimization time and requiring minimal hyperparameter tuning.
Singular Value Scaling: Efficient Generative Model Compression via Pruned Weights Refinement
Dec 24, 2024



While pruning methods effectively maintain model performance without extra training costs, they often focus solely on preserving crucial connections, overlooking the impact of pruned weights on subsequent fine-tuning or distillation, leading to inefficiencies. Moreover, most compression techniques for generative models have been developed primarily for GANs, tailored to specific architectures like StyleGAN, and research into compressing Diffusion models has just begun. Even more, these methods are often applicable only to GANs or Diffusion models, highlighting the need for approaches that work across both model types. In this paper, we introduce Singular Value Scaling (SVS), a versatile technique for refining pruned weights, applicable to both model types. Our analysis reveals that pruned weights often exhibit dominant singular vectors, hindering fine-tuning efficiency and leading to suboptimal performance compared to random initialization. Our method enhances weight initialization by minimizing the disparities between singular values of pruned weights, thereby improving the fine-tuning process. This approach not only guides the compressed model toward superior solutions but also significantly speeds up fine-tuning. Extensive experiments on StyleGAN2, StyleGAN3 and DDPM demonstrate that SVS improves compression performance across model types without additional training costs. Our code is available at: https://github.com/LAIT-CVLab/Singular-Value-Scaling.
Nickel and Diming Your GAN: A Dual-Method Approach to Enhancing GAN Efficiency via Knowledge Distillation
May 19, 2024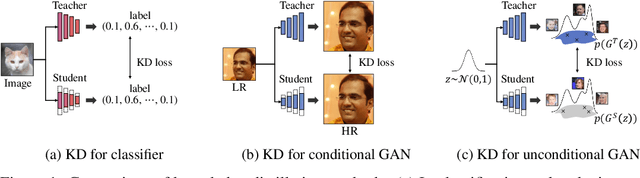

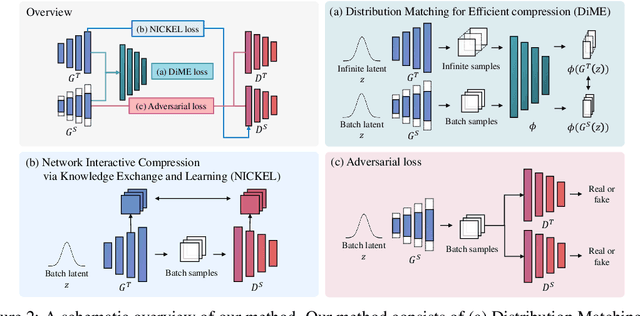
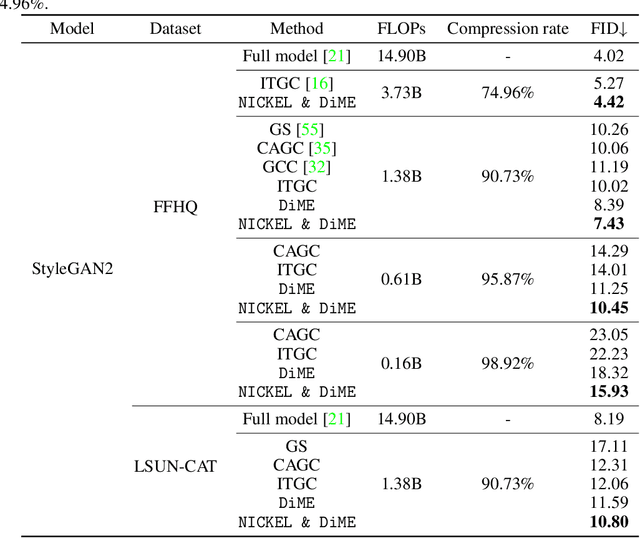
In this paper, we address the challenge of compressing generative adversarial networks (GANs) for deployment in resource-constrained environments by proposing two novel methodologies: Distribution Matching for Efficient compression (DiME) and Network Interactive Compression via Knowledge Exchange and Learning (NICKEL). DiME employs foundation models as embedding kernels for efficient distribution matching, leveraging maximum mean discrepancy to facilitate effective knowledge distillation. Simultaneously, NICKEL employs an interactive compression method that enhances the communication between the student generator and discriminator, achieving a balanced and stable compression process. Our comprehensive evaluation on the StyleGAN2 architecture with the FFHQ dataset shows the effectiveness of our approach, with NICKEL & DiME achieving FID scores of 10.45 and 15.93 at compression rates of 95.73% and 98.92%, respectively. Remarkably, our methods sustain generative quality even at an extreme compression rate of 99.69%, surpassing the previous state-of-the-art performance by a large margin. These findings not only demonstrate our methodologies' capacity to significantly lower GANs' computational demands but also pave the way for deploying high-quality GAN models in settings with limited resources. Our code will be released soon.
PosterLlama: Bridging Design Ability of Langauge Model to Contents-Aware Layout Generation
Apr 02, 2024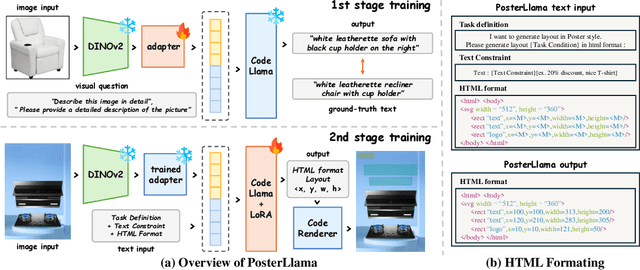
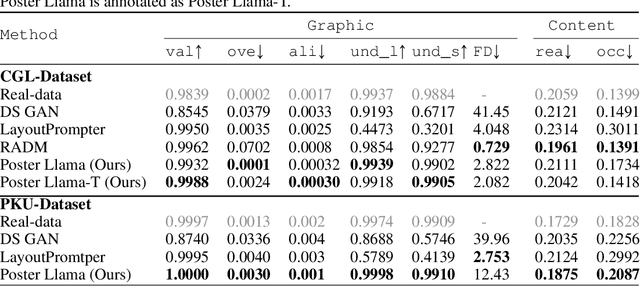
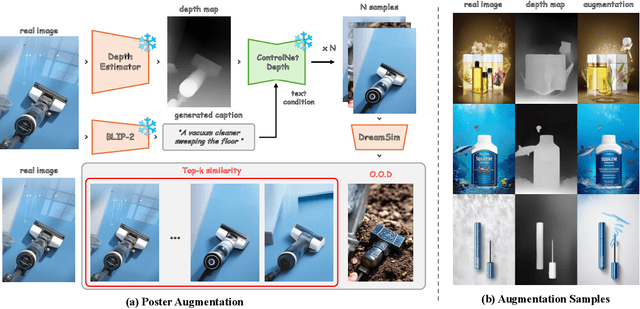

Visual layout plays a critical role in graphic design fields such as advertising, posters, and web UI design. The recent trend towards content-aware layout generation through generative models has shown promise, yet it often overlooks the semantic intricacies of layout design by treating it as a simple numerical optimization. To bridge this gap, we introduce PosterLlama, a network designed for generating visually and textually coherent layouts by reformatting layout elements into HTML code and leveraging the rich design knowledge embedded within language models. Furthermore, we enhance the robustness of our model with a unique depth-based poster augmentation strategy. This ensures our generated layouts remain semantically rich but also visually appealing, even with limited data. Our extensive evaluations across several benchmarks demonstrate that PosterLlama outperforms existing methods in producing authentic and content-aware layouts. It supports an unparalleled range of conditions, including but not limited to unconditional layout generation, element conditional layout generation, layout completion, among others, serving as a highly versatile user manipulation tool.