 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Video Diffusion Models with 2D Triplane and 3D Wavelet Representation
Feb 21, 2024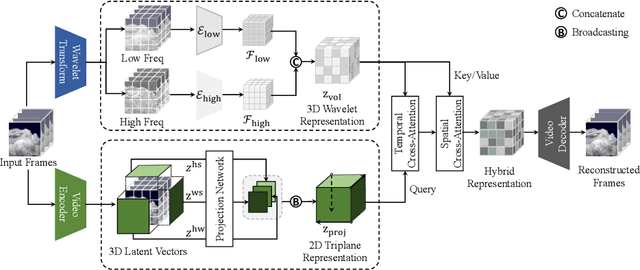

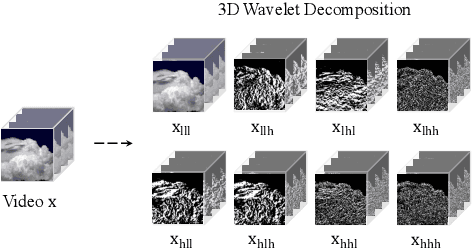
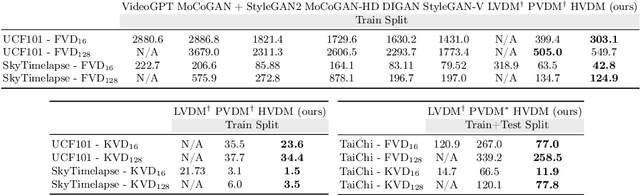
Generating high-quality videos that synthesize desired realistic content is a challenging task due to their intricate high-dimensionality and complexity of videos. Several recent diffusion-based methods have shown comparable performance by compressing videos to a lower-dimensional latent space, using traditional video autoencoder architecture. However, such method that employ standard frame-wise 2D and 3D convolution fail to fully exploit the spatio-temporal nature of videos. To address this issue, we propose a novel hybrid video diffusion model, called HVDM, which can capture spatio-temporal dependencies more effectively. The HVDM is trained by a hybrid video autoencoder which extracts a disentangled representation of the video including: (i) a global context information captured by a 2D projected latent (ii) a local volume information captured by 3D convolutions with wavelet decomposition (iii) a frequency information for improving the video reconstruction. Based on this disentangled representation, our hybrid autoencoder provide a more comprehensive video latent enriching the generated videos with fine structures and details. Experiments on video generation benchamarks (UCF101, SkyTimelapse, and TaiChi) demonstrate that the proposed approach achieves state-of-the-art video generation quality, showing a wide range of video applications (e.g., long video generation, image-to-video, and video dynamics control).
U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation
Jul 25, 2019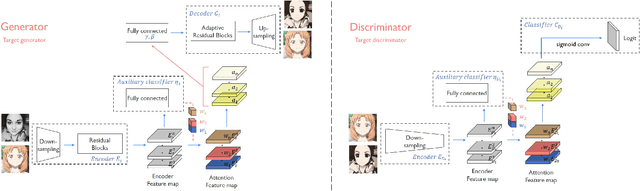
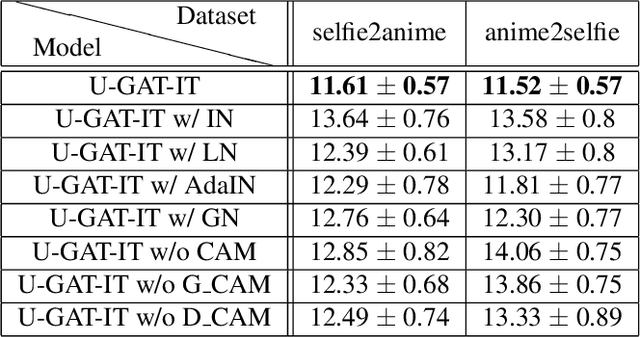

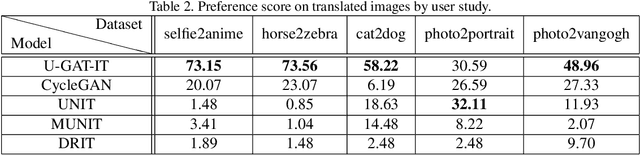
We propose a novel method for unsupervised image-to-image translation, which incorporates a new attention module and a new learnable normalization function in an end-to-end manner. The attention module guides our model to focus on more important regions distinguishing between source and target domains based on the attention map obtained by the auxiliary classifier. Unlike previous attention-based methods which cannot handle the geometric changes between domains, our model can translate both images requiring holistic changes and images requiring large shape changes. Moreover, our new AdaLIN (Adaptive Layer-Instance Normalization) function helps our attention-guided model to flexibly control the amount of change in shape and texture by learned parameters depending on datasets. Experimental results show the superiority of the proposed method compared to the existing state-of-the-art models with a fixed network architecture and hyper-parameters.