 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Gaussian Temporal Difference Error For Uncertainty-aware Reinforcement Learning
Aug 05, 2024



Conventional uncertainty-aware temporal difference (TD) learning methods often rely on simplistic assumptions, typically including a zero-mean Gaussian distribution for TD errors. Such oversimplification can lead to inaccurate error representations and compromised uncertainty estimation. In this paper, we introduce a novel framework for generalized Gaussian error modeling in deep reinforcement learning, applicable to both discrete and continuous control settings. Our framework enhances the flexibility of error distribution modeling by incorporating higher-order moments, particularly kurtosis, thereby improving the estimation and mitigation of data-dependent noise, i.e., aleatoric uncertainty. We examine the influence of the shape parameter of the generalized Gaussian distribution (GGD) on aleatoric uncertainty and provide a closed-form expression that demonstrates an inverse relationship between uncertainty and the shape parameter. Additionally, we propose a theoretically grounded weighting scheme to fully leverage the GGD. To address epistemic uncertainty, we enhance the batch inverse variance weighting by incorporating bias reduction and kurtosis considerations, resulting in improved robustness. Extensive experimental evaluations using policy gradient algorithms demonstrate the consistent efficacy of our method, showcasing significant performance improvements.
LLMem: Estimating GPU Memory Usage for Fine-Tuning Pre-Trained LLMs
Apr 16, 2024



Fine-tuning pre-trained large language models (LLMs) with limited hardware presents challenges due to GPU memory constraints. Various distributed fine-tuning methods have been proposed to alleviate memory constraints on GPU. However, determining the most effective method for achieving rapid fine-tuning while preventing GPU out-of-memory issues in a given environment remains unclear. To address this challenge, we introduce LLMem, a solution that estimates the GPU memory consumption when applying distributed fine-tuning methods across multiple GPUs and identifies the optimal method. We conduct GPU memory usage estimation prior to fine-tuning, leveraging the fundamental structure of transformer-based decoder models and the memory usage distribution of each method. Experimental results show that LLMem accurately estimates peak GPU memory usage on a single GPU, with error rates of up to 1.6%. Additionally, it shows an average error rate of 3.0% when applying distributed fine-tuning methods to LLMs with more than a billion parameters on multi-GPU setups.
MoDiTalker: Motion-Disentangled Diffusion Model for High-Fidelity Talking Head Generation
Mar 28, 2024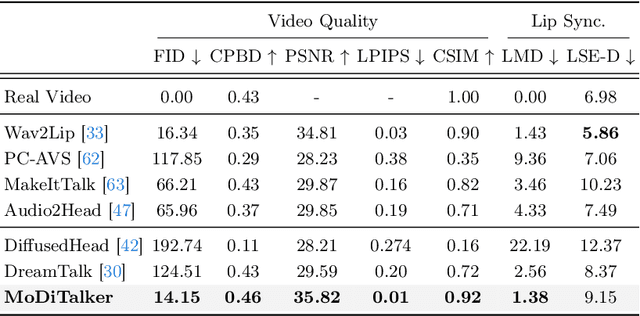
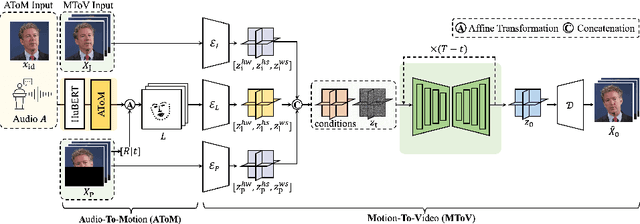

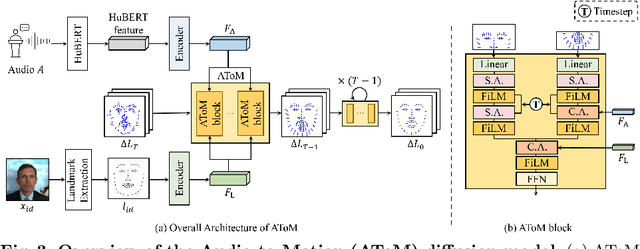
Conventional GAN-based models for talking head generation often suffer from limited quality and unstable training. Recent approaches based on diffusion models aimed to address these limitations and improve fidelity. However, they still face challenges, including extensive sampling times and difficulties in maintaining temporal consistency due to the high stochasticity of diffusion models. To overcome these challenges, we propose a novel motion-disentangled diffusion model for high-quality talking head generation, dubbed MoDiTalker. We introduce the two modules: audio-to-motion (AToM), designed to generate a synchronized lip motion from audio, and motion-to-video (MToV), designed to produce high-quality head video following the generated motion. AToM excels in capturing subtle lip movements by leveraging an audio attention mechanism. In addition, MToV enhances temporal consistency by leveraging an efficient tri-plane representation. Our experiments conducted on standard benchmarks demonstrate that our model achieves superior performance compared to existing models. We also provide comprehensive ablation studies and user study results.
Hybrid Video Diffusion Models with 2D Triplane and 3D Wavelet Representation
Feb 21, 2024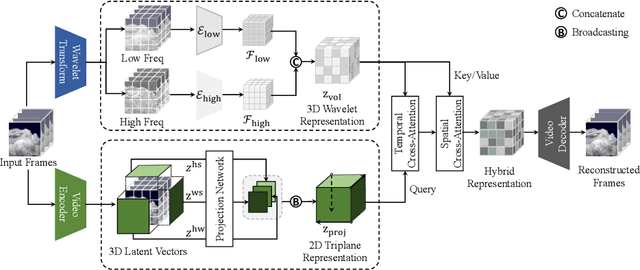

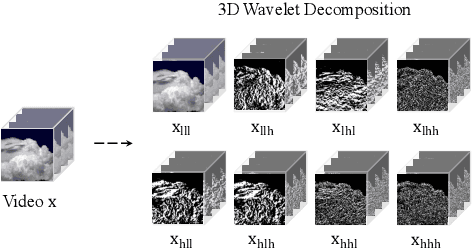
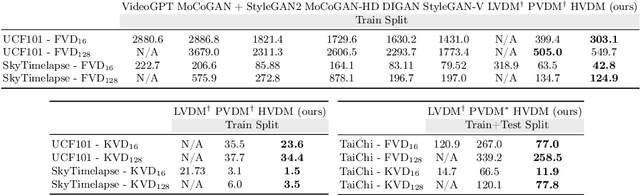
Generating high-quality videos that synthesize desired realistic content is a challenging task due to their intricate high-dimensionality and complexity of videos. Several recent diffusion-based methods have shown comparable performance by compressing videos to a lower-dimensional latent space, using traditional video autoencoder architecture. However, such method that employ standard frame-wise 2D and 3D convolution fail to fully exploit the spatio-temporal nature of videos. To address this issue, we propose a novel hybrid video diffusion model, called HVDM, which can capture spatio-temporal dependencies more effectively. The HVDM is trained by a hybrid video autoencoder which extracts a disentangled representation of the video including: (i) a global context information captured by a 2D projected latent (ii) a local volume information captured by 3D convolutions with wavelet decomposition (iii) a frequency information for improving the video reconstruction. Based on this disentangled representation, our hybrid autoencoder provide a more comprehensive video latent enriching the generated videos with fine structures and details. Experiments on video generation benchamarks (UCF101, SkyTimelapse, and TaiChi) demonstrate that the proposed approach achieves state-of-the-art video generation quality, showing a wide range of video applications (e.g., long video generation, image-to-video, and video dynamics control).
DiffMatch: Diffusion Model for Dense Matching
May 30, 2023
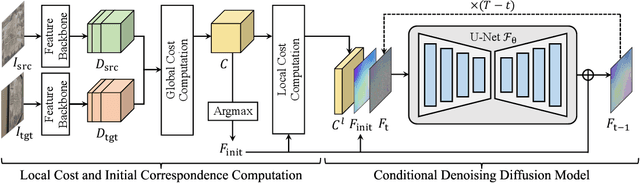

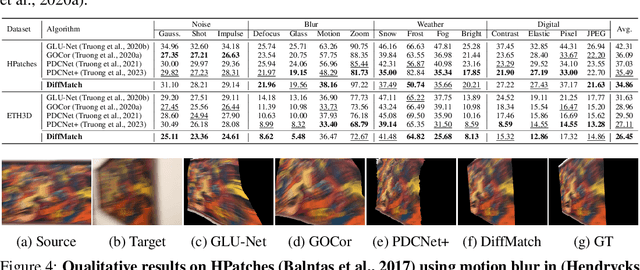
The objective for establishing dense correspondence between paired images consists of two terms: a data term and a prior term. While conventional techniques focused on defining hand-designed prior terms, which are difficult to formulate, recent approaches have focused on learning the data term with deep neural networks without explicitly modeling the prior, assuming that the model itself has the capacity to learn an optimal prior from a large-scale dataset. The performance improvement was obvious, however, they often fail to address inherent ambiguities of matching, such as textureless regions, repetitive patterns, and large displacements. To address this, we propose DiffMatch, a novel conditional diffusion-based framework designed to explicitly model both the data and prior terms. Unlike previous approaches, this is accomplished by leveraging a conditional denoising diffusion model. DiffMatch consists of two main components: conditional denoising diffusion module and cost injection module. We stabilize the training process and reduce memory usage with a stage-wise training strategy. Furthermore, to boost performance, we introduce an inference technique that finds a better path to the accurate matching field. Our experimental results demonstrate significant performance improvements of our method over existing approaches, and the ablation studies validate our design choices along with the effectiveness of each component. Project page is available at https://ku-cvlab.github.io/DiffMatch/.