 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantuneV2: Compiler-Based Local Metric-Driven Mixed Precision Quantization for Practical Embedded AI Applications
Jan 13, 2025



Mixed-precision quantization methods have been proposed to reduce model size while minimizing accuracy degradation. However, existing studies require retraining and do not consider the computational overhead and intermediate representations (IR) generated during the compilation process, limiting their application at the compiler level. This computational overhead refers to the runtime latency caused by frequent quantization and dequantization operations during inference. Performing these operations at the individual operator level causes significant runtime delays. To address these issues, we propose QuantuneV2, a compiler-based mixed-precision quantization method designed for practical embedded AI applications. QuantuneV2 performs inference only twice, once before quantization and once after quantization, and operates with a computational complexity of O(n) that increases linearly with the number of model parameters. We also made the sensitivity analysis more stable by using local metrics like weights, activation values, the Signal to Quantization Noise Ratio, and the Mean Squared Error. We also cut down on computational overhead by choosing the best IR and using operator fusion. Experimental results show that QuantuneV2 achieved up to a 10.28 percent improvement in accuracy and a 12.52 percent increase in speed compared to existing methods across five models: ResNet18v1, ResNet50v1, SqueezeNetv1, VGGNet, and MobileNetv2. This demonstrates that QuantuneV2 enhances model performance while maintaining computational efficiency, making it suitable for deployment in embedded AI environments.
ML$^2$Tuner: Efficient Code Tuning via Multi-Level Machine Learning Models
Nov 16, 2024The increasing complexity of deep learning models necessitates specialized hardware and software optimizations, particularly for deep learning accelerators. Existing autotuning methods often suffer from prolonged tuning times due to profiling invalid configurations, which can cause runtime errors. We introduce ML$^2$Tuner, a multi-level machine learning tuning technique that enhances autotuning efficiency by incorporating a validity prediction model to filter out invalid configurations and an advanced performance prediction model utilizing hidden features from the compilation process. Experimental results on an extended VTA accelerator demonstrate that ML$^2$Tuner achieves equivalent performance improvements using only 12.3% of the samples required with a similar approach as TVM and reduces invalid profiling attempts by an average of 60.8%, Highlighting its potential to enhance autotuning performance by filtering out invalid configurations
A Comprehensive Evaluation of Quantized Instruction-Tuned Large Language Models: An Experimental Analysis up to 405B
Sep 17, 2024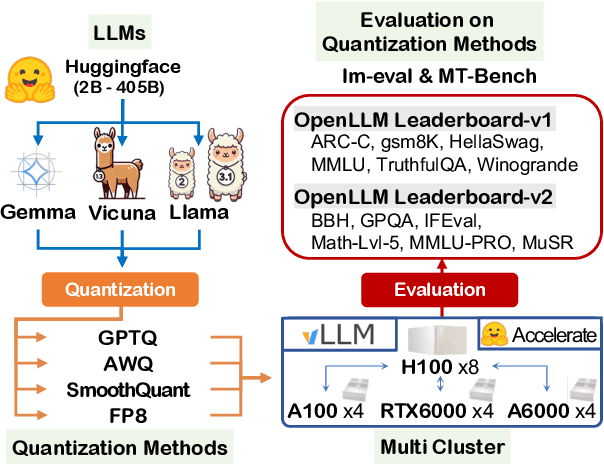
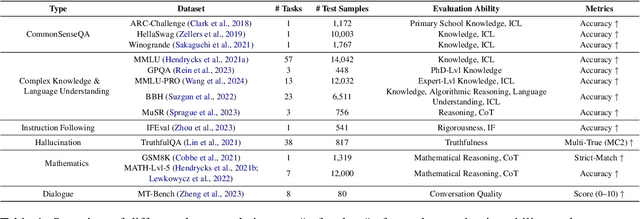
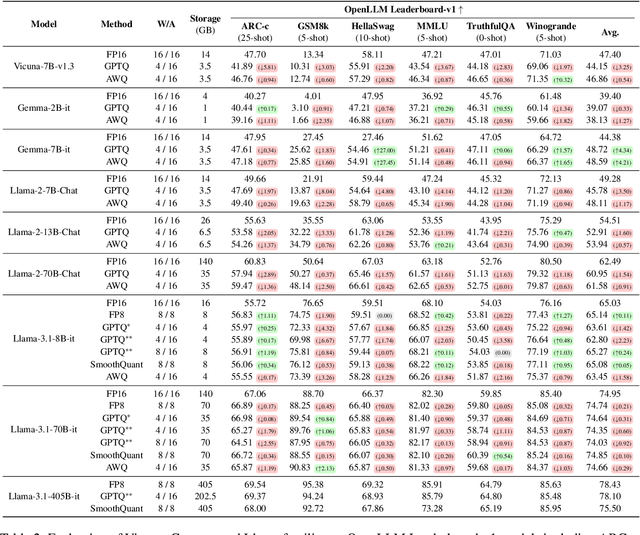
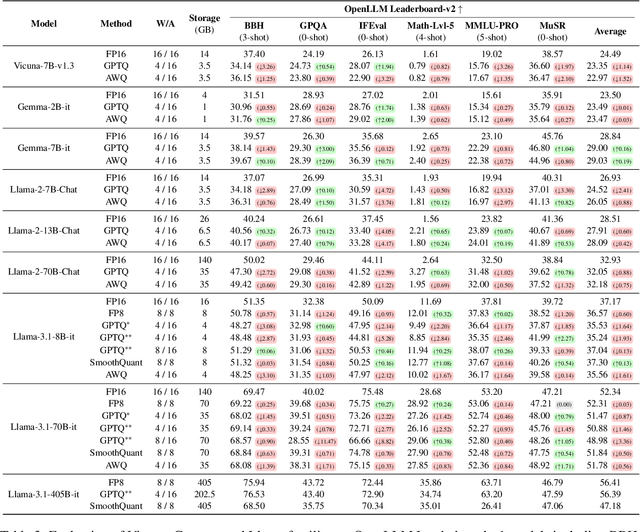
Prior research works have evaluated quantized LLMs using limited metrics such as perplexity or a few basic knowledge tasks and old datasets. Additionally, recent large-scale models such as Llama 3.1 with up to 405B have not been thoroughly examined. This paper evaluates the performance of instruction-tuned LLMs across various quantization methods (GPTQ, AWQ, SmoothQuant, and FP8) on models ranging from 7B to 405B. Using 13 benchmarks, we assess performance across six task types: commonsense Q\&A, knowledge and language understanding, instruction following, hallucination detection, mathematics, and dialogue. Our key findings reveal that (1) quantizing a larger LLM to a similar size as a smaller FP16 LLM generally performs better across most benchmarks, except for hallucination detection and instruction following; (2) performance varies significantly with different quantization methods, model size, and bit-width, with weight-only methods often yielding better results in larger models; (3) task difficulty does not significantly impact accuracy degradation due to quantization; and (4) the MT-Bench evaluation method has limited discriminatory power among recent high-performing LLMs.
Mixed Non-linear Quantization for Vision Transformers
Jul 26, 2024



The majority of quantization methods have been proposed to reduce the model size of Vision Transformers, yet most of them have overlooked the quantization of non-linear operations. Only a few works have addressed quantization for non-linear operations, but they applied a single quantization method across all non-linear operations. We believe that this can be further improved by employing a different quantization method for each non-linear operation. Therefore, to assign the most error-minimizing quantization method from the known methods to each non-linear layer, we propose a mixed non-linear quantization that considers layer-wise quantization sensitivity measured by SQNR difference metric. The results show that our method outperforms I-BERT, FQ-ViT, and I-ViT in both 8-bit and 6-bit settings for ViT, DeiT, and Swin models by an average of 0.6%p and 19.6%p, respectively. Our method outperforms I-BERT and I-ViT by 0.6%p and 20.8%p, respectively, when training time is limited. We plan to release our code at https://gitlab.com/ones-ai/mixed-non-linear-quantization.
LLMem: Estimating GPU Memory Usage for Fine-Tuning Pre-Trained LLMs
Apr 16, 2024



Fine-tuning pre-trained large language models (LLMs) with limited hardware presents challenges due to GPU memory constraints. Various distributed fine-tuning methods have been proposed to alleviate memory constraints on GPU. However, determining the most effective method for achieving rapid fine-tuning while preventing GPU out-of-memory issues in a given environment remains unclear. To address this challenge, we introduce LLMem, a solution that estimates the GPU memory consumption when applying distributed fine-tuning methods across multiple GPUs and identifies the optimal method. We conduct GPU memory usage estimation prior to fine-tuning, leveraging the fundamental structure of transformer-based decoder models and the memory usage distribution of each method. Experimental results show that LLMem accurately estimates peak GPU memory usage on a single GPU, with error rates of up to 1.6%. Additionally, it shows an average error rate of 3.0% when applying distributed fine-tuning methods to LLMs with more than a billion parameters on multi-GPU setups.
Visual Preference Inference: An Image Sequence-Based Preference Reasoning in Tabletop Object Manipulation
Mar 18, 2024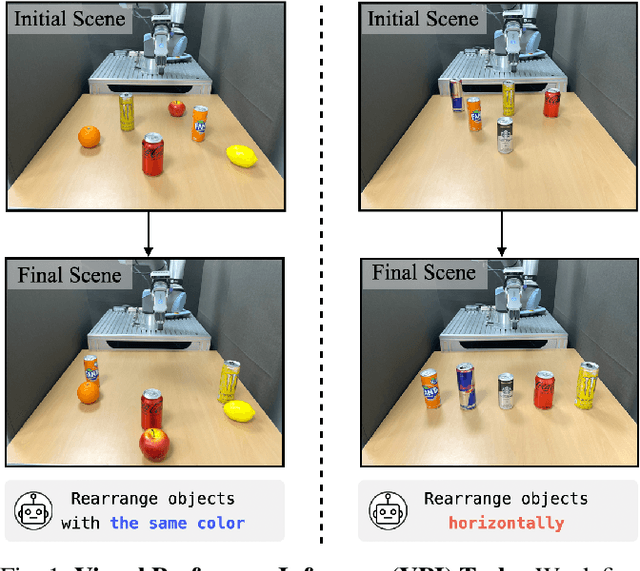


In robotic object manipulation, human preferences can often be influenced by the visual attributes of objects, such as color and shape. These properties play a crucial role in operating a robot to interact with objects and align with human intention. In this paper, we focus on the problem of inferring underlying human preferences from a sequence of raw visual observations in tabletop manipulation environments with a variety of object types, named Visual Preference Inference (VPI). To facilitate visual reasoning in the context of manipulation, we introduce the Chain-of-Visual-Residuals (CoVR) method. CoVR employs a prompting mechanism that describes the difference between the consecutive images (i.e., visual residuals) and incorporates such texts with a sequence of images to infer the user's preference. This approach significantly enhances the ability to understand and adapt to dynamic changes in its visual environment during manipulation tasks. Furthermore, we incorporate such texts along with a sequence of images to infer the user's preferences. Our method outperforms baseline methods in terms of extracting human preferences from visual sequences in both simulation and real-world environments. Code and videos are available at: \href{https://joonhyung-lee.github.io/vpi/}{https://joonhyung-lee.github.io/vpi/}
Tensor Slicing and Optimization for Multicore NPUs
Apr 06, 2023

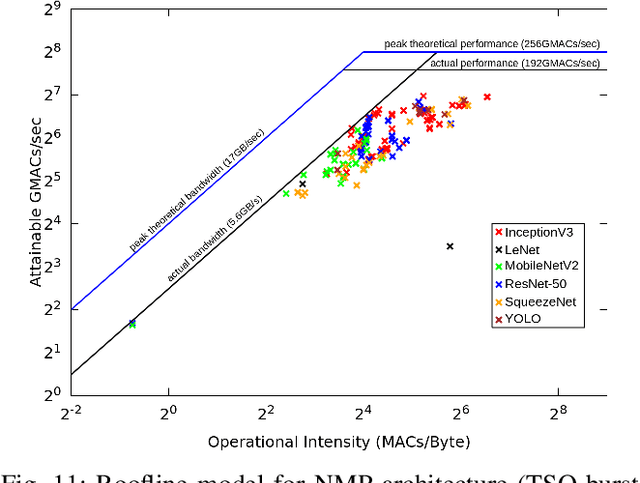

Although code generation for Convolution Neural Network (CNN) models has been extensively studied, performing efficient data slicing and parallelization for highly-constrai\-ned Multicore Neural Processor Units (NPUs) is still a challenging problem. Given the size of convolutions' input/output tensors and the small footprint of NPU on-chip memories, minimizing memory transactions while maximizing parallelism and MAC utilization are central to any effective solution. This paper proposes a TensorFlow XLA/LLVM compiler optimization pass for Multicore NPUs, called Tensor Slicing Optimization (TSO), which: (a) maximizes convolution parallelism and memory usage across NPU cores; and (b) reduces data transfers between host and NPU on-chip memories by using DRAM memory burst time estimates to guide tensor slicing. To evaluate the proposed approach, a set of experiments was performed using the NeuroMorphic Processor (NMP), a multicore NPU containing 32 RISC-V cores extended with novel CNN instructions. Experimental results show that TSO is capable of identifying the best tensor slicing that minimizes execution time for a set of CNN models. Speed-ups of up to 21.7\% result when comparing the TSO burst-based technique to a no-burst data slicing approach. To validate the generality of the TSO approach, the algorithm was also ported to the Glow Machine Learning framework. The performance of the models were measured on both Glow and TensorFlow XLA/LLVM compilers, revealing similar results.
Q-HyViT: Post-Training Quantization for Hybrid Vision Transformer with Bridge Block Reconstruction
Mar 22, 2023



Recently, vision transformers (ViT) have replaced convolutional neural network models in numerous tasks, including classification, detection, and segmentation. However, the high computational requirements of ViTs hinder their widespread implementation. To address this issue, researchers have proposed efficient hybrid transformer architectures that combine convolutional and transformer layers and optimize attention computation for linear complexity. Additionally, post-training quantization has been proposed as a means of mitigating computational demands. Combining quantization techniques and efficient hybrid transformer structures is crucial to maximize the acceleration of vision transformers on mobile devices. However, no prior investigation has applied quantization to efficient hybrid transformers. In this paper, at first, we discover that the straightforward manner to apply the existing PTQ methods for ViT to efficient hybrid transformers results in a drastic accuracy drop due to the following challenges: (i) highly dynamic ranges, (ii) zero-point overflow, (iii) diverse normalization, and (iv) limited model parameters (<5M). To overcome these challenges, we propose a new post-training quantization method, which is the first to quantize efficient hybrid vision transformers (MobileViTv1 and MobileViTv2) with a significant margin (an average improvement of 7.75%) compared to existing PTQ methods (EasyQuant, FQ-ViT, and PTQ4ViT). We plan to release our code at https://github.com/Q-HyViT.
CPrune: Compiler-Informed Model Pruning for Efficient Target-Aware DNN Execution
Jul 04, 2022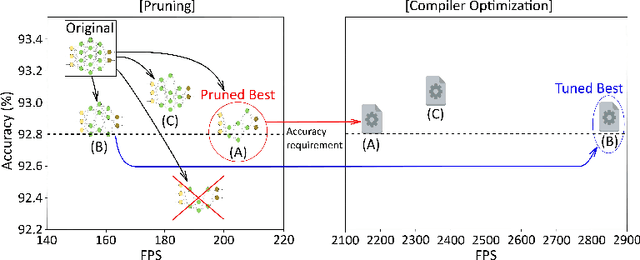
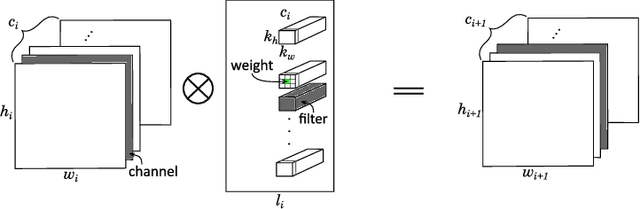
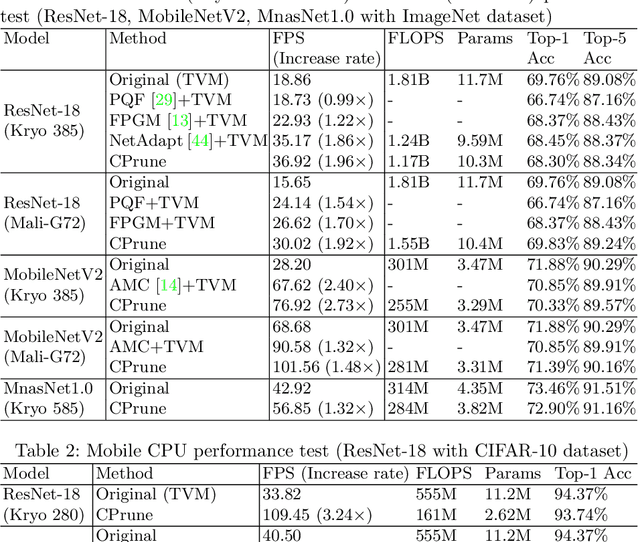
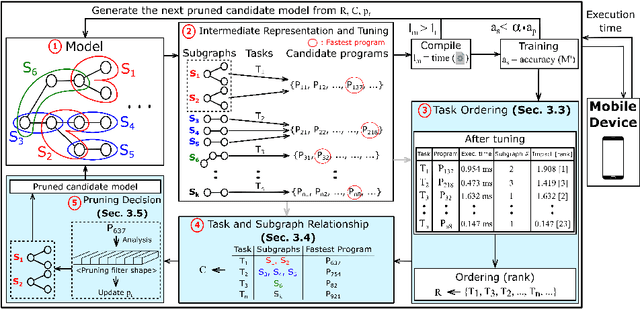
Mobile devices run deep learning models for various purposes, such as image classification and speech recognition. Due to the resource constraints of mobile devices, researchers have focused on either making a lightweight deep neural network (DNN) model using model pruning or generating an efficient code using compiler optimization. Surprisingly, we found that the straightforward integration between model compression and compiler auto-tuning often does not produce the most efficient model for a target device. We propose CPrune, a compiler-informed model pruning for efficient target-aware DNN execution to support an application with a required target accuracy. CPrune makes a lightweight DNN model through informed pruning based on the structural information of subgraphs built during the compiler tuning process. Our experimental results show that CPrune increases the DNN execution speed up to 2.73x compared to the state-of-the-art TVM auto-tune while satisfying the accuracy requirement.
Quantune: Post-training Quantization of Convolutional Neural Networks using Extreme Gradient Boosting for Fast Deployment
Feb 21, 2022
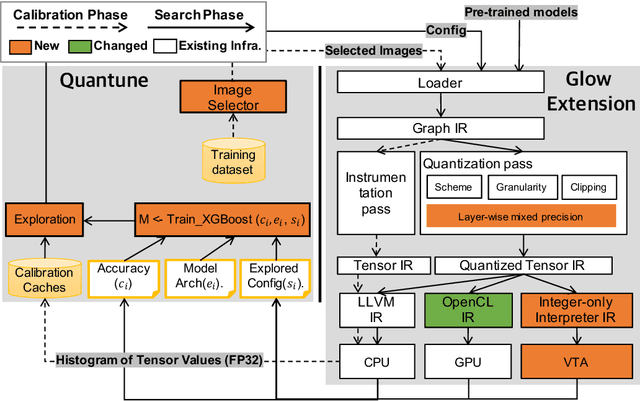
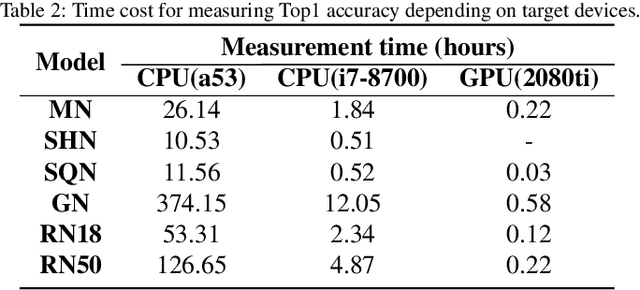
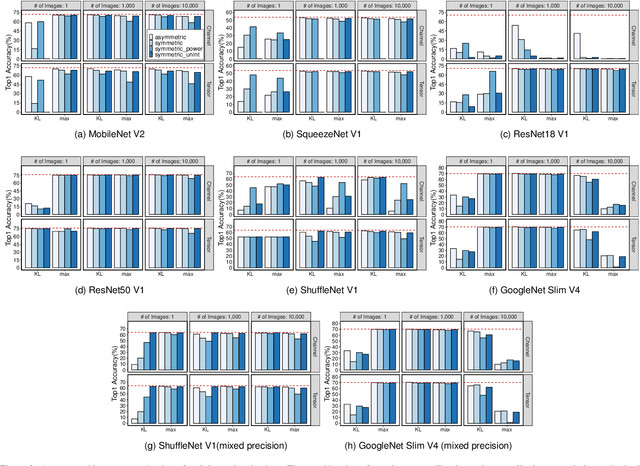
To adopt convolutional neural networks (CNN) for a range of resource-constrained targets, it is necessary to compress the CNN models by performing quantization, whereby precision representation is converted to a lower bit representation. To overcome problems such as sensitivity of the training dataset, high computational requirements, and large time consumption, post-training quantization methods that do not require retraining have been proposed. In addition, to compensate for the accuracy drop without retraining, previous studies on post-training quantization have proposed several complementary methods: calibration, schemes, clipping, granularity, and mixed-precision. To generate a quantized model with minimal error, it is necessary to study all possible combinations of the methods because each of them is complementary and the CNN models have different characteristics. However, an exhaustive or a heuristic search is either too time-consuming or suboptimal. To overcome this challenge, we propose an auto-tuner known as Quantune, which builds a gradient tree boosting model to accelerate the search for the configurations of quantization and reduce the quantization error. We evaluate and compare Quantune with the random, grid, and genetic algorithms. The experimental results show that Quantune reduces the search time for quantization by approximately 36.5x with an accuracy loss of 0.07 ~ 0.65% across six CNN models, including the fragile ones (MobileNet, SqueezeNet, and ShuffleNet). To support multiple targets and adopt continuously evolving quantization works, Quantune is implemented on a full-fledged compiler for deep learning as an open-sourced project.