 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVersatile and Fast Location-Based Private Information Retrieval with Fully Homomorphic Encryption over the Torus
Jun 15, 2025Location-based services often require users to share sensitive locational data, raising privacy concerns due to potential misuse or exploitation by untrusted servers. In response, we present VeLoPIR, a versatile location-based private information retrieval (PIR) system designed to preserve user privacy while enabling efficient and scalable query processing. VeLoPIR introduces three operational modes-interval validation, coordinate validation, and identifier matching-that support a broad range of real-world applications, including information and emergency alerts. To enhance performance, VeLoPIR incorporates multi-level algorithmic optimizations with parallel structures, achieving significant scalability across both CPU and GPU platforms. We also provide formal security and privacy proofs, confirming the system's robustness under standard cryptographic assumptions. Extensive experiments on real-world datasets demonstrate that VeLoPIR achieves up to 11.55 times speed-up over a prior baseline. The implementation of VeLoPIR is publicly available at https://github.com/PrivStatBool/VeLoPIR.
Data-Driven Sequential Sampling for Tail Risk Mitigation
Mar 10, 2025Given a finite collection of stochastic alternatives, we study the problem of sequentially allocating a fixed sampling budget to identify the optimal alternative with a high probability, where the optimal alternative is defined as the one with the smallest value of extreme tail risk. We particularly consider a situation where these alternatives generate heavy-tailed losses whose probability distributions are unknown and may not admit any specific parametric representation. In this setup, we propose data-driven sequential sampling policies that maximize the rate at which the likelihood of falsely selecting suboptimal alternatives decays to zero. We rigorously demonstrate the superiority of the proposed methods over existing approaches, which is further validated via numerical studies.
Optimizing Input Data Collection for Ranking and Selection
Feb 23, 2025



We study a ranking and selection (R&S) problem when all solutions share common parametric Bayesian input models updated with the data collected from multiple independent data-generating sources. Our objective is to identify the best system by designing a sequential sampling algorithm that collects input and simulation data given a budget. We adopt the most probable best (MPB) as the estimator of the optimum and show that its posterior probability of optimality converges to one at an exponential rate as the sampling budget increases. Assuming that the input parameters belong to a finite set, we characterize the $\epsilon$-optimal static sampling ratios for input and simulation data that maximize the convergence rate. Using these ratios as guidance, we propose the optimal sampling algorithm for R&S (OSAR) that achieves the $\epsilon$-optimal ratios almost surely in the limit. We further extend OSAR by adopting the kernel ridge regression to improve the simulation output mean prediction. This not only improves OSAR's finite-sample performance, but also lets us tackle the case where the input parameters lie in a continuous space with a strong consistency guarantee for finding the optimum. We numerically demonstrate that OSAR outperforms a state-of-the-art competitor.
LLMem: Estimating GPU Memory Usage for Fine-Tuning Pre-Trained LLMs
Apr 16, 2024



Fine-tuning pre-trained large language models (LLMs) with limited hardware presents challenges due to GPU memory constraints. Various distributed fine-tuning methods have been proposed to alleviate memory constraints on GPU. However, determining the most effective method for achieving rapid fine-tuning while preventing GPU out-of-memory issues in a given environment remains unclear. To address this challenge, we introduce LLMem, a solution that estimates the GPU memory consumption when applying distributed fine-tuning methods across multiple GPUs and identifies the optimal method. We conduct GPU memory usage estimation prior to fine-tuning, leveraging the fundamental structure of transformer-based decoder models and the memory usage distribution of each method. Experimental results show that LLMem accurately estimates peak GPU memory usage on a single GPU, with error rates of up to 1.6%. Additionally, it shows an average error rate of 3.0% when applying distributed fine-tuning methods to LLMs with more than a billion parameters on multi-GPU setups.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Self-Supervised Learning from Non-Object Centric Images with a Geometric Transformation Sensitive Architecture
Apr 27, 2023



Most invariance-based self-supervised methods rely on single object-centric images (e.g., ImageNet images) for pretraining, learning invariant representations from geometric transformations. However, when images are not object-centric, the semantics of the image can be significantly altered due to cropping. Furthermore, as the model learns geometrically insensitive features, it may struggle to capture location information. For this reason, we propose a Geometric Transformation Sensitive Architecture that learns features sensitive to geometric transformations, specifically four-fold rotation, random crop, and multi-crop. Our method encourages the student to learn sensitive features by using targets that are sensitive to those transforms via pooling and rotating of the teacher feature map and predicting rotation. Additionally, since training insensitively to multi-crop can capture long-term dependencies, we use patch correspondence loss to train the model sensitively while capturing long-term dependencies. Our approach demonstrates improved performance when using non-object-centric images as pretraining data compared to other methods that learn geometric transformation-insensitive representations. We surpass the DINO[\citet{caron2021emerging}] baseline in tasks including image classification, semantic segmentation, detection, and instance segmentation with improvements of 6.1 $Acc$, 3.3 $mIoU$, 3.4 $AP^b$, and 2.7 $AP^m$. Code and pretrained models are publicly available at:
Tensor Slicing and Optimization for Multicore NPUs
Apr 06, 2023

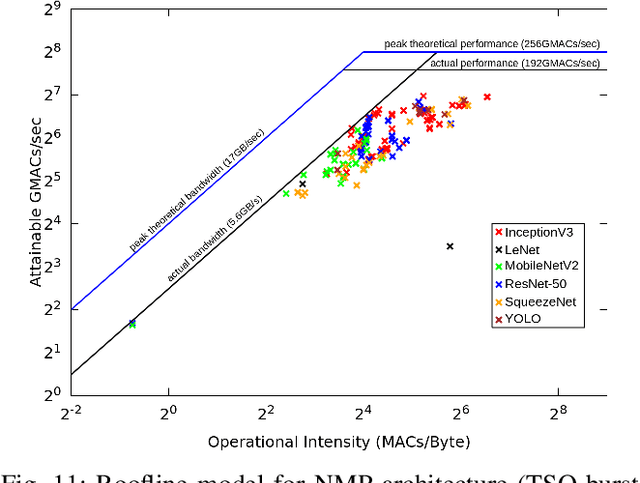

Although code generation for Convolution Neural Network (CNN) models has been extensively studied, performing efficient data slicing and parallelization for highly-constrai\-ned Multicore Neural Processor Units (NPUs) is still a challenging problem. Given the size of convolutions' input/output tensors and the small footprint of NPU on-chip memories, minimizing memory transactions while maximizing parallelism and MAC utilization are central to any effective solution. This paper proposes a TensorFlow XLA/LLVM compiler optimization pass for Multicore NPUs, called Tensor Slicing Optimization (TSO), which: (a) maximizes convolution parallelism and memory usage across NPU cores; and (b) reduces data transfers between host and NPU on-chip memories by using DRAM memory burst time estimates to guide tensor slicing. To evaluate the proposed approach, a set of experiments was performed using the NeuroMorphic Processor (NMP), a multicore NPU containing 32 RISC-V cores extended with novel CNN instructions. Experimental results show that TSO is capable of identifying the best tensor slicing that minimizes execution time for a set of CNN models. Speed-ups of up to 21.7\% result when comparing the TSO burst-based technique to a no-burst data slicing approach. To validate the generality of the TSO approach, the algorithm was also ported to the Glow Machine Learning framework. The performance of the models were measured on both Glow and TensorFlow XLA/LLVM compilers, revealing similar results.
Selection of the Most Probable Best
Jul 15, 2022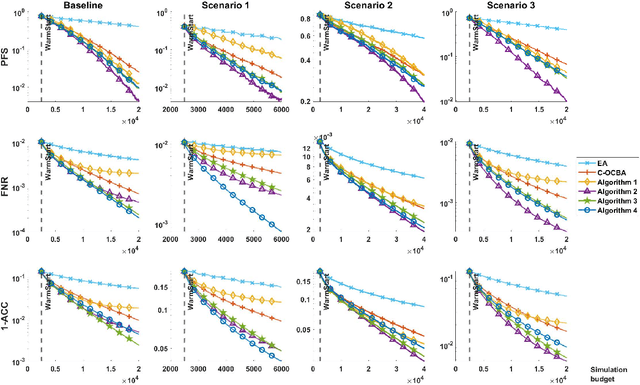

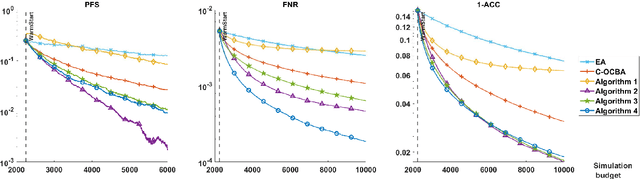
We consider an expected-value ranking and selection problem where all k solutions' simulation outputs depend on a common uncertain input model. Given that the uncertainty of the input model is captured by a probability simplex on a finite support, we define the most probable best (MPB) to be the solution whose probability of being optimal is the largest. To devise an efficient sampling algorithm to find the MPB, we first derive a lower bound to the large deviation rate of the probability of falsely selecting the MPB, then formulate an optimal computing budget allocation (OCBA) problem to find the optimal static sampling ratios for all solution-input model pairs that maximize the lower bound. We devise a series of sequential algorithms that apply interpretable and computationally efficient sampling rules and prove their sampling ratios achieve the optimality conditions for the OCBA problem as the simulation budget increases. The algorithms are benchmarked against a state-of-the-art sequential sampling algorithm designed for contextual ranking and selection problems and demonstrated to have superior empirical performances at finding the MPB.
CPrune: Compiler-Informed Model Pruning for Efficient Target-Aware DNN Execution
Jul 04, 2022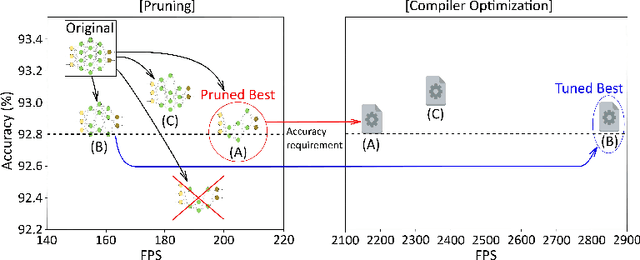
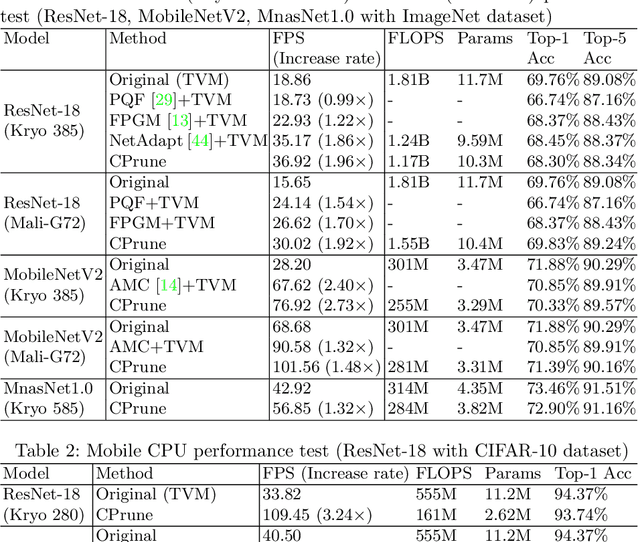
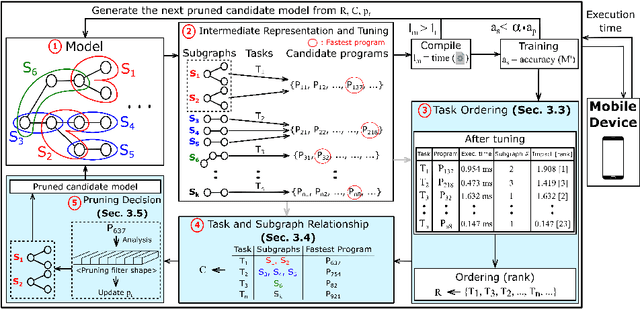
Mobile devices run deep learning models for various purposes, such as image classification and speech recognition. Due to the resource constraints of mobile devices, researchers have focused on either making a lightweight deep neural network (DNN) model using model pruning or generating an efficient code using compiler optimization. Surprisingly, we found that the straightforward integration between model compression and compiler auto-tuning often does not produce the most efficient model for a target device. We propose CPrune, a compiler-informed model pruning for efficient target-aware DNN execution to support an application with a required target accuracy. CPrune makes a lightweight DNN model through informed pruning based on the structural information of subgraphs built during the compiler tuning process. Our experimental results show that CPrune increases the DNN execution speed up to 2.73x compared to the state-of-the-art TVM auto-tune while satisfying the accuracy requirement.
Quantune: Post-training Quantization of Convolutional Neural Networks using Extreme Gradient Boosting for Fast Deployment
Feb 21, 2022
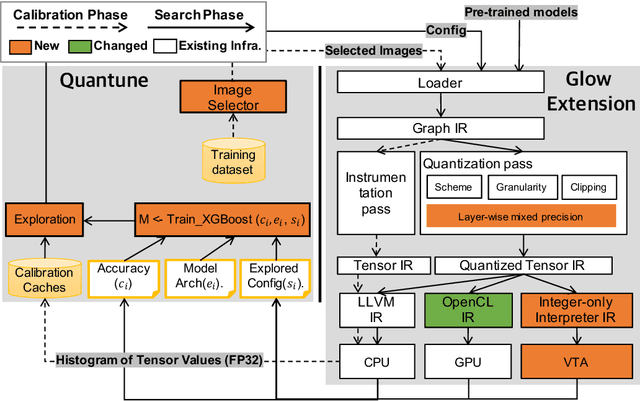
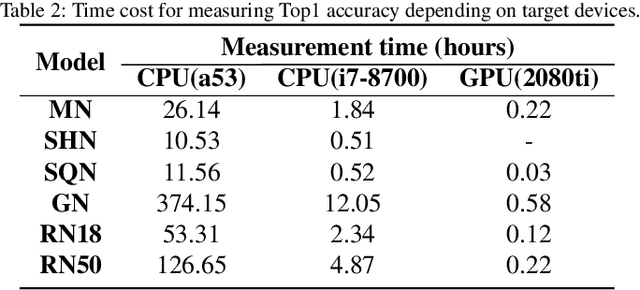
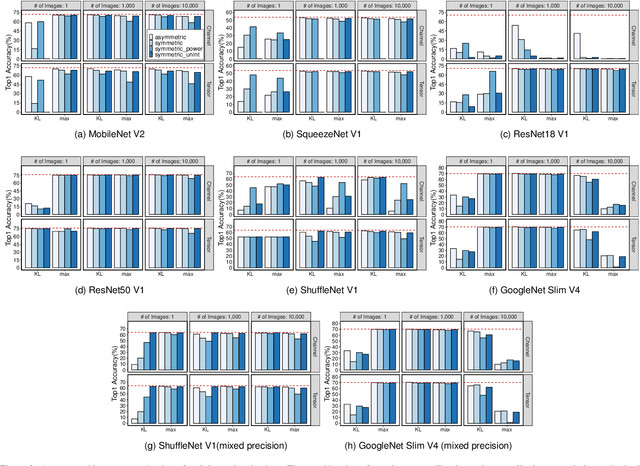
To adopt convolutional neural networks (CNN) for a range of resource-constrained targets, it is necessary to compress the CNN models by performing quantization, whereby precision representation is converted to a lower bit representation. To overcome problems such as sensitivity of the training dataset, high computational requirements, and large time consumption, post-training quantization methods that do not require retraining have been proposed. In addition, to compensate for the accuracy drop without retraining, previous studies on post-training quantization have proposed several complementary methods: calibration, schemes, clipping, granularity, and mixed-precision. To generate a quantized model with minimal error, it is necessary to study all possible combinations of the methods because each of them is complementary and the CNN models have different characteristics. However, an exhaustive or a heuristic search is either too time-consuming or suboptimal. To overcome this challenge, we propose an auto-tuner known as Quantune, which builds a gradient tree boosting model to accelerate the search for the configurations of quantization and reduce the quantization error. We evaluate and compare Quantune with the random, grid, and genetic algorithms. The experimental results show that Quantune reduces the search time for quantization by approximately 36.5x with an accuracy loss of 0.07 ~ 0.65% across six CNN models, including the fragile ones (MobileNet, SqueezeNet, and ShuffleNet). To support multiple targets and adopt continuously evolving quantization works, Quantune is implemented on a full-fledged compiler for deep learning as an open-sourced project.