 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-HyViT: Post-Training Quantization for Hybrid Vision Transformer with Bridge Block Reconstruction
Mar 22, 2023



Recently, vision transformers (ViT) have replaced convolutional neural network models in numerous tasks, including classification, detection, and segmentation. However, the high computational requirements of ViTs hinder their widespread implementation. To address this issue, researchers have proposed efficient hybrid transformer architectures that combine convolutional and transformer layers and optimize attention computation for linear complexity. Additionally, post-training quantization has been proposed as a means of mitigating computational demands. Combining quantization techniques and efficient hybrid transformer structures is crucial to maximize the acceleration of vision transformers on mobile devices. However, no prior investigation has applied quantization to efficient hybrid transformers. In this paper, at first, we discover that the straightforward manner to apply the existing PTQ methods for ViT to efficient hybrid transformers results in a drastic accuracy drop due to the following challenges: (i) highly dynamic ranges, (ii) zero-point overflow, (iii) diverse normalization, and (iv) limited model parameters (<5M). To overcome these challenges, we propose a new post-training quantization method, which is the first to quantize efficient hybrid vision transformers (MobileViTv1 and MobileViTv2) with a significant margin (an average improvement of 7.75%) compared to existing PTQ methods (EasyQuant, FQ-ViT, and PTQ4ViT). We plan to release our code at https://github.com/Q-HyViT.
Quantune: Post-training Quantization of Convolutional Neural Networks using Extreme Gradient Boosting for Fast Deployment
Feb 21, 2022
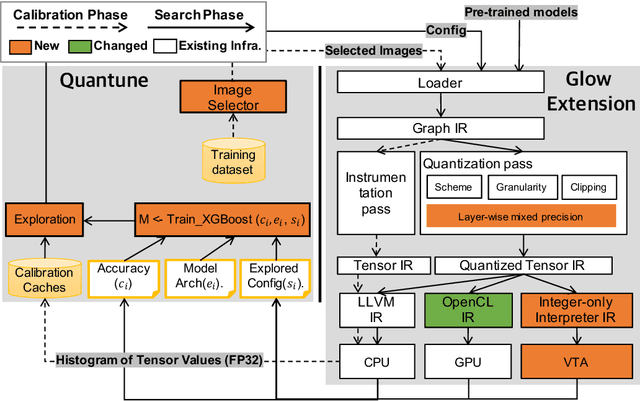
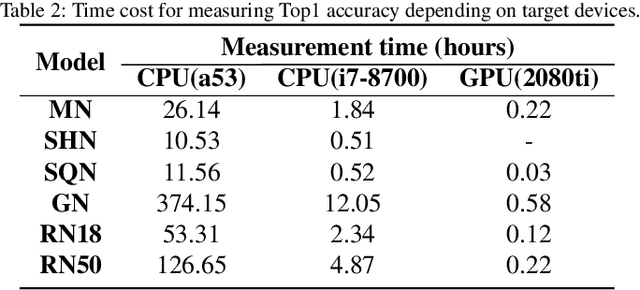
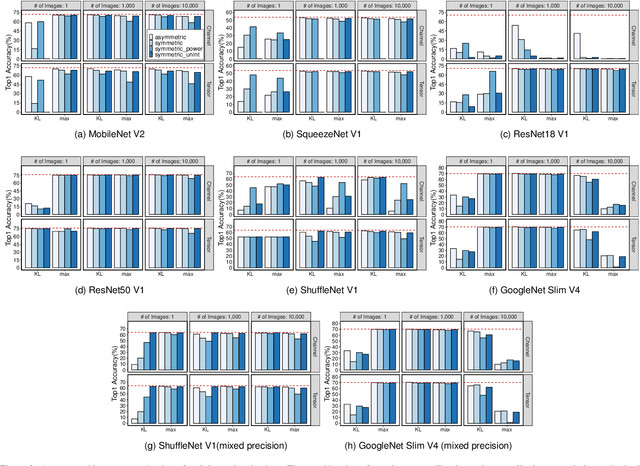
To adopt convolutional neural networks (CNN) for a range of resource-constrained targets, it is necessary to compress the CNN models by performing quantization, whereby precision representation is converted to a lower bit representation. To overcome problems such as sensitivity of the training dataset, high computational requirements, and large time consumption, post-training quantization methods that do not require retraining have been proposed. In addition, to compensate for the accuracy drop without retraining, previous studies on post-training quantization have proposed several complementary methods: calibration, schemes, clipping, granularity, and mixed-precision. To generate a quantized model with minimal error, it is necessary to study all possible combinations of the methods because each of them is complementary and the CNN models have different characteristics. However, an exhaustive or a heuristic search is either too time-consuming or suboptimal. To overcome this challenge, we propose an auto-tuner known as Quantune, which builds a gradient tree boosting model to accelerate the search for the configurations of quantization and reduce the quantization error. We evaluate and compare Quantune with the random, grid, and genetic algorithms. The experimental results show that Quantune reduces the search time for quantization by approximately 36.5x with an accuracy loss of 0.07 ~ 0.65% across six CNN models, including the fragile ones (MobileNet, SqueezeNet, and ShuffleNet). To support multiple targets and adopt continuously evolving quantization works, Quantune is implemented on a full-fledged compiler for deep learning as an open-sourced project.