 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPTQ-ViT: Post-Training Quantization of Non-linear Functions for Integer-only Vision Transformers
Nov 19, 2025



Previous Quantization-Aware Training (QAT) methods for vision transformers rely on expensive retraining to recover accuracy loss in non-linear layer quantization, limiting their use in resource-constrained environments. In contrast, existing Post-Training Quantization (PTQ) methods either partially quantize non-linear functions or adjust activation distributions to maintain accuracy but fail to achieve fully integer-only inference. In this paper, we introduce IPTQ-ViT, a novel PTQ framework for fully integer-only vision transformers without retraining. We present approximation functions: a polynomial-based GELU optimized for vision data and a bit-shifting-based Softmax designed to improve approximation accuracy in PTQ. In addition, we propose a unified metric integrating quantization sensitivity, perturbation, and computational cost to select the optimal approximation function per activation layer. IPTQ-ViT outperforms previous PTQ methods, achieving up to 6.44\%p (avg. 1.78\%p) top-1 accuracy improvement for image classification, 1.0 mAP for object detection. IPTQ-ViT outperforms partial floating-point PTQ methods under W8A8 and W4A8, and achieves accuracy and latency comparable to integer-only QAT methods. We plan to release our code https://github.com/gihwan-kim/IPTQ-ViT.git.
A Survey on Inference Engines for Large Language Models: Perspectives on Optimization and Efficiency
May 03, 2025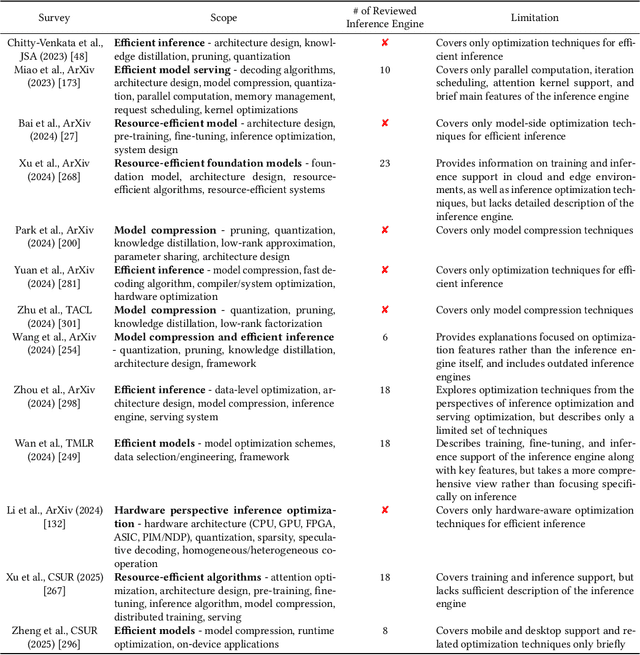
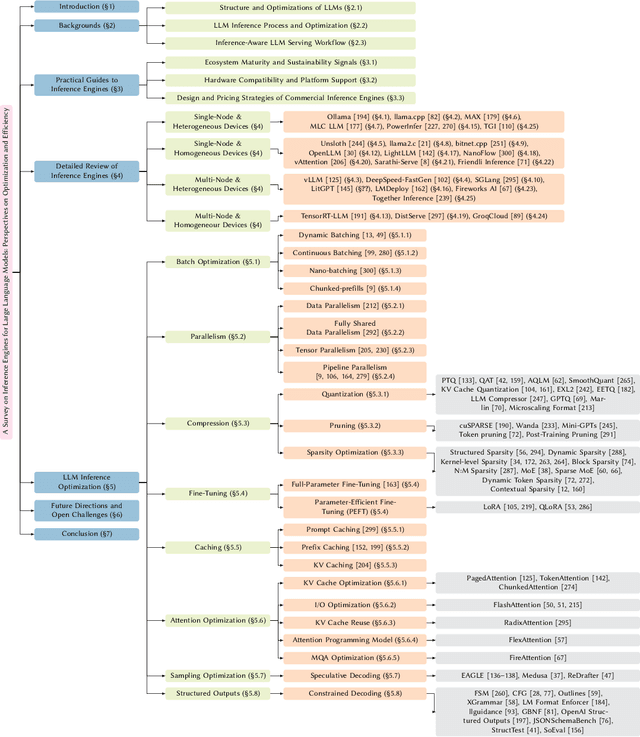
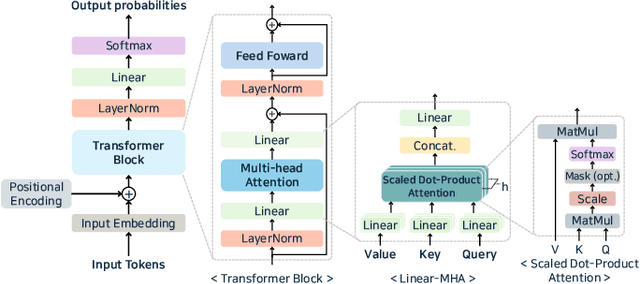

Large language models (LLMs) are widely applied in chatbots, code generators, and search engines. Workloads such as chain-of-thought, complex reasoning, and agent services significantly increase the inference cost by invoking the model repeatedly. Optimization methods such as parallelism, compression, and caching have been adopted to reduce costs, but the diverse service requirements make it hard to select the right method. Recently, specialized LLM inference engines have emerged as a key component for integrating the optimization methods into service-oriented infrastructures. However, a systematic study on inference engines is still lacking. This paper provides a comprehensive evaluation of 25 open-source and commercial inference engines. We examine each inference engine in terms of ease-of-use, ease-of-deployment, general-purpose support, scalability, and suitability for throughput- and latency-aware computation. Furthermore, we explore the design goals of each inference engine by investigating the optimization techniques it supports. In addition, we assess the ecosystem maturity of open source inference engines and handle the performance and cost policy of commercial solutions. We outline future research directions that include support for complex LLM-based services, support of various hardware, and enhanced security, offering practical guidance to researchers and developers in selecting and designing optimized LLM inference engines. We also provide a public repository to continually track developments in this fast-evolving field: https://github.com/sihyeong/Awesome-LLM-Inference-Engine
LLM-Guided Open RAN: Empowering Hierarchical RAN Intelligent Control
Apr 25, 2025

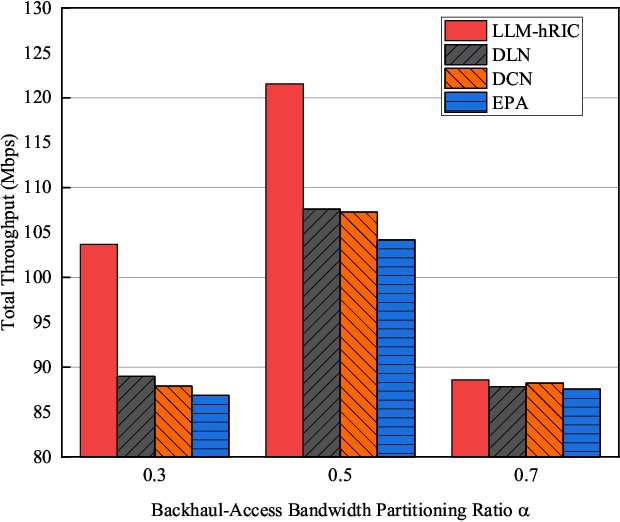
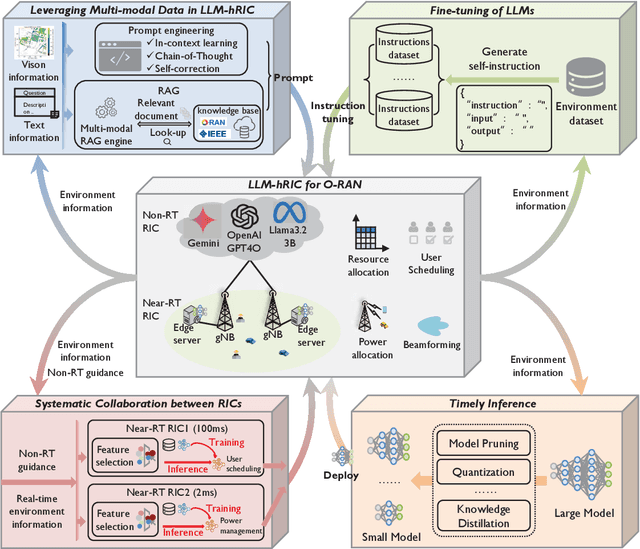
Recent advancements in large language models (LLMs) have led to a significant interest in deploying LLMempowered algorithms for wireless communication networks. Meanwhile, open radio access network (O-RAN) techniques offer unprecedented flexibility, with the non-real-time (non-RT) radio access network (RAN) intelligent controller (RIC) (non-RT RIC) and near-real-time (near-RT) RIC (near-RT RIC) components enabling intelligent resource management across different time scales. In this paper, we propose the LLM empowered hierarchical RIC (LLM-hRIC) framework to improve the collaboration between RICs. This framework integrates LLMs with reinforcement learning (RL) for efficient network resource management. In this framework, LLMs-empowered non-RT RICs provide strategic guidance and high-level policies based on environmental context. Concurrently, RL-empowered near-RT RICs perform low-latency tasks based on strategic guidance and local near-RT observation. We evaluate the LLM-hRIC framework in an integrated access and backhaul (IAB) network setting. Simulation results demonstrate that the proposed framework achieves superior performance. Finally, we discuss the key future challenges in applying LLMs to O-RAN.
QuantuneV2: Compiler-Based Local Metric-Driven Mixed Precision Quantization for Practical Embedded AI Applications
Jan 13, 2025



Mixed-precision quantization methods have been proposed to reduce model size while minimizing accuracy degradation. However, existing studies require retraining and do not consider the computational overhead and intermediate representations (IR) generated during the compilation process, limiting their application at the compiler level. This computational overhead refers to the runtime latency caused by frequent quantization and dequantization operations during inference. Performing these operations at the individual operator level causes significant runtime delays. To address these issues, we propose QuantuneV2, a compiler-based mixed-precision quantization method designed for practical embedded AI applications. QuantuneV2 performs inference only twice, once before quantization and once after quantization, and operates with a computational complexity of O(n) that increases linearly with the number of model parameters. We also made the sensitivity analysis more stable by using local metrics like weights, activation values, the Signal to Quantization Noise Ratio, and the Mean Squared Error. We also cut down on computational overhead by choosing the best IR and using operator fusion. Experimental results show that QuantuneV2 achieved up to a 10.28 percent improvement in accuracy and a 12.52 percent increase in speed compared to existing methods across five models: ResNet18v1, ResNet50v1, SqueezeNetv1, VGGNet, and MobileNetv2. This demonstrates that QuantuneV2 enhances model performance while maintaining computational efficiency, making it suitable for deployment in embedded AI environments.
ML$^2$Tuner: Efficient Code Tuning via Multi-Level Machine Learning Models
Nov 16, 2024The increasing complexity of deep learning models necessitates specialized hardware and software optimizations, particularly for deep learning accelerators. Existing autotuning methods often suffer from prolonged tuning times due to profiling invalid configurations, which can cause runtime errors. We introduce ML$^2$Tuner, a multi-level machine learning tuning technique that enhances autotuning efficiency by incorporating a validity prediction model to filter out invalid configurations and an advanced performance prediction model utilizing hidden features from the compilation process. Experimental results on an extended VTA accelerator demonstrate that ML$^2$Tuner achieves equivalent performance improvements using only 12.3% of the samples required with a similar approach as TVM and reduces invalid profiling attempts by an average of 60.8%, Highlighting its potential to enhance autotuning performance by filtering out invalid configurations
A Comprehensive Evaluation of Quantized Instruction-Tuned Large Language Models: An Experimental Analysis up to 405B
Sep 17, 2024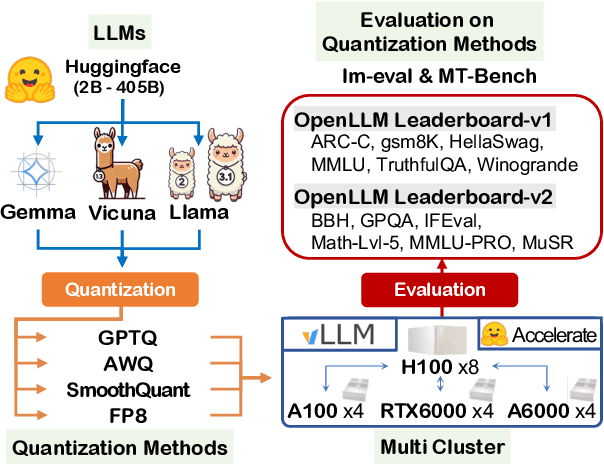
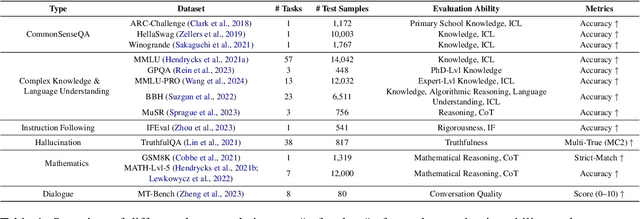
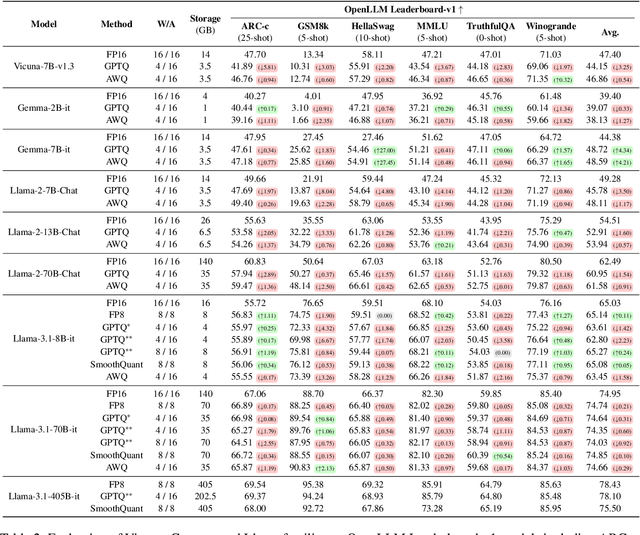
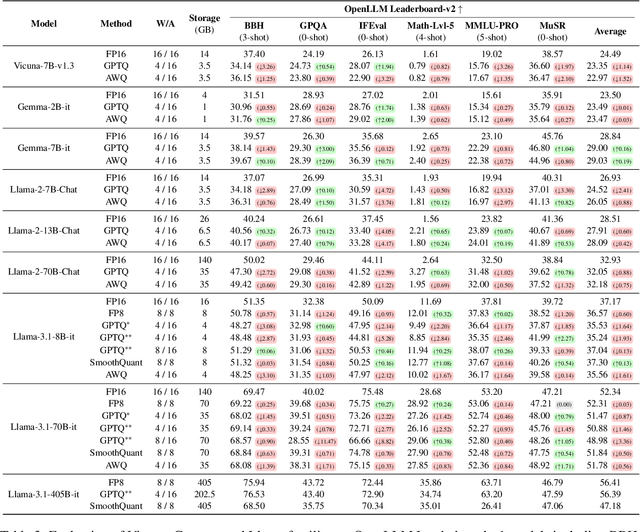
Prior research works have evaluated quantized LLMs using limited metrics such as perplexity or a few basic knowledge tasks and old datasets. Additionally, recent large-scale models such as Llama 3.1 with up to 405B have not been thoroughly examined. This paper evaluates the performance of instruction-tuned LLMs across various quantization methods (GPTQ, AWQ, SmoothQuant, and FP8) on models ranging from 7B to 405B. Using 13 benchmarks, we assess performance across six task types: commonsense Q\&A, knowledge and language understanding, instruction following, hallucination detection, mathematics, and dialogue. Our key findings reveal that (1) quantizing a larger LLM to a similar size as a smaller FP16 LLM generally performs better across most benchmarks, except for hallucination detection and instruction following; (2) performance varies significantly with different quantization methods, model size, and bit-width, with weight-only methods often yielding better results in larger models; (3) task difficulty does not significantly impact accuracy degradation due to quantization; and (4) the MT-Bench evaluation method has limited discriminatory power among recent high-performing LLMs.
Mixed Non-linear Quantization for Vision Transformers
Jul 26, 2024



The majority of quantization methods have been proposed to reduce the model size of Vision Transformers, yet most of them have overlooked the quantization of non-linear operations. Only a few works have addressed quantization for non-linear operations, but they applied a single quantization method across all non-linear operations. We believe that this can be further improved by employing a different quantization method for each non-linear operation. Therefore, to assign the most error-minimizing quantization method from the known methods to each non-linear layer, we propose a mixed non-linear quantization that considers layer-wise quantization sensitivity measured by SQNR difference metric. The results show that our method outperforms I-BERT, FQ-ViT, and I-ViT in both 8-bit and 6-bit settings for ViT, DeiT, and Swin models by an average of 0.6%p and 19.6%p, respectively. Our method outperforms I-BERT and I-ViT by 0.6%p and 20.8%p, respectively, when training time is limited. We plan to release our code at https://gitlab.com/ones-ai/mixed-non-linear-quantization.
Visual Preference Inference: An Image Sequence-Based Preference Reasoning in Tabletop Object Manipulation
Mar 18, 2024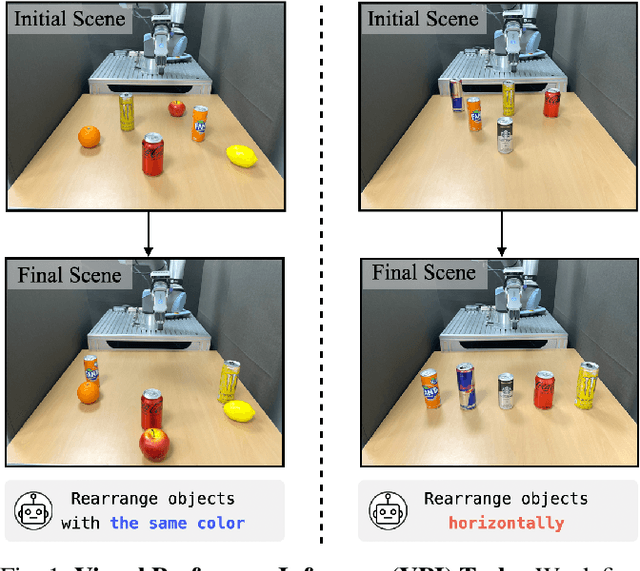


In robotic object manipulation, human preferences can often be influenced by the visual attributes of objects, such as color and shape. These properties play a crucial role in operating a robot to interact with objects and align with human intention. In this paper, we focus on the problem of inferring underlying human preferences from a sequence of raw visual observations in tabletop manipulation environments with a variety of object types, named Visual Preference Inference (VPI). To facilitate visual reasoning in the context of manipulation, we introduce the Chain-of-Visual-Residuals (CoVR) method. CoVR employs a prompting mechanism that describes the difference between the consecutive images (i.e., visual residuals) and incorporates such texts with a sequence of images to infer the user's preference. This approach significantly enhances the ability to understand and adapt to dynamic changes in its visual environment during manipulation tasks. Furthermore, we incorporate such texts along with a sequence of images to infer the user's preferences. Our method outperforms baseline methods in terms of extracting human preferences from visual sequences in both simulation and real-world environments. Code and videos are available at: \href{https://joonhyung-lee.github.io/vpi/}{https://joonhyung-lee.github.io/vpi/}
Positioning Using Wireless Networks: Applications, Recent Progress and Future Challenges
Mar 18, 2024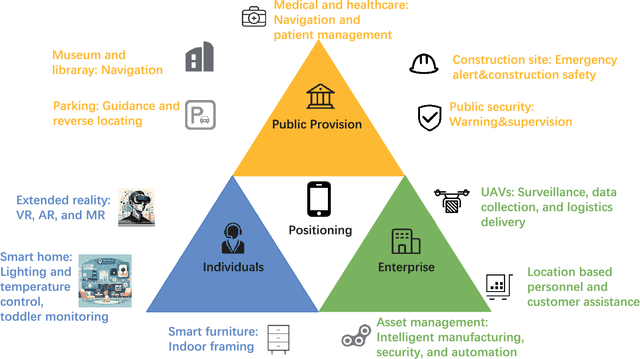
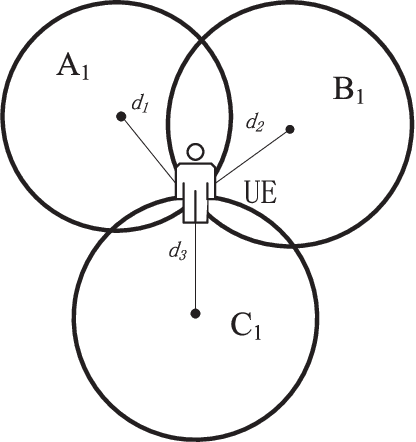
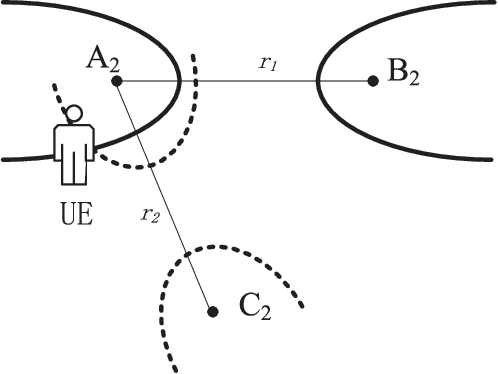
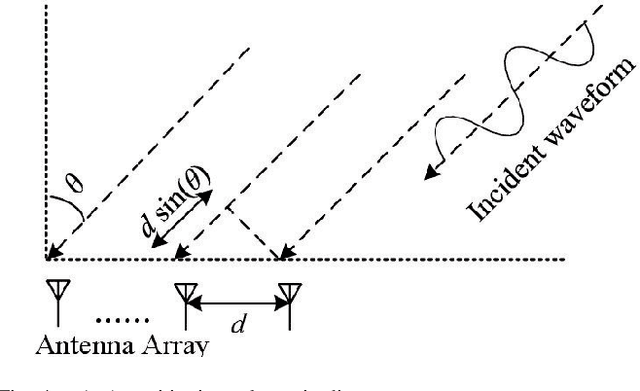
Positioning has recently received considerable attention as a key enabler in emerging applications such as extended reality, unmanned aerial vehicles and smart environments. These applications require both data communication and high-precision positioning, and thus they are particularly well-suited to be offered in wireless networks (WNs). The purpose of this paper is to provide a comprehensive overview of existing works and new trends in the field of positioning techniques from both the academic and industrial perspectives. The paper provides a comprehensive overview of positioning in WNs, covering the background, applications, measurements, state-of-the-art technologies and future challenges. The paper outlines the applications of positioning from the perspectives of public facilities, enterprises and individual users. We investigate the key performance indicators and measurements of positioning systems, followed by the review of the key enabler techniques such as artificial intelligence/large models and adaptive systems. Next, we discuss a number of typical wireless positioning technologies. We extend our overview beyond the academic progress, to include the standardization efforts, and finally, we provide insight into the challenges that remain. The comprehensive overview of exisitng efforts and new trends in the field of positioning from both the academic and industrial communities would be a useful reference to researchers in the field.
Q-HyViT: Post-Training Quantization for Hybrid Vision Transformer with Bridge Block Reconstruction
Mar 22, 2023



Recently, vision transformers (ViT) have replaced convolutional neural network models in numerous tasks, including classification, detection, and segmentation. However, the high computational requirements of ViTs hinder their widespread implementation. To address this issue, researchers have proposed efficient hybrid transformer architectures that combine convolutional and transformer layers and optimize attention computation for linear complexity. Additionally, post-training quantization has been proposed as a means of mitigating computational demands. Combining quantization techniques and efficient hybrid transformer structures is crucial to maximize the acceleration of vision transformers on mobile devices. However, no prior investigation has applied quantization to efficient hybrid transformers. In this paper, at first, we discover that the straightforward manner to apply the existing PTQ methods for ViT to efficient hybrid transformers results in a drastic accuracy drop due to the following challenges: (i) highly dynamic ranges, (ii) zero-point overflow, (iii) diverse normalization, and (iv) limited model parameters (<5M). To overcome these challenges, we propose a new post-training quantization method, which is the first to quantize efficient hybrid vision transformers (MobileViTv1 and MobileViTv2) with a significant margin (an average improvement of 7.75%) compared to existing PTQ methods (EasyQuant, FQ-ViT, and PTQ4ViT). We plan to release our code at https://github.com/Q-HyViT.