 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Evaluation of Quantized Instruction-Tuned Large Language Models: An Experimental Analysis up to 405B
Sep 17, 2024
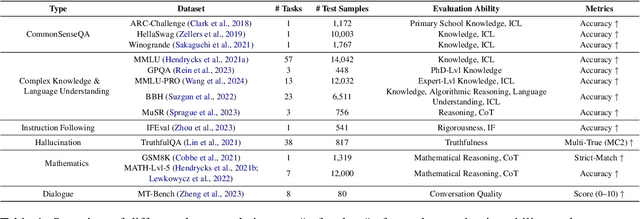
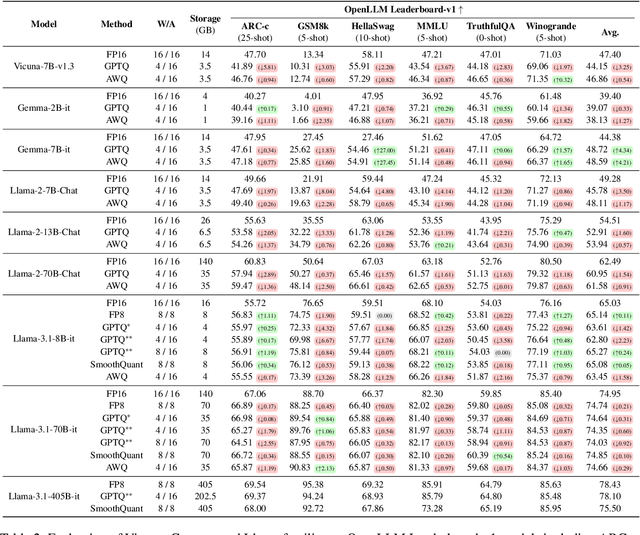
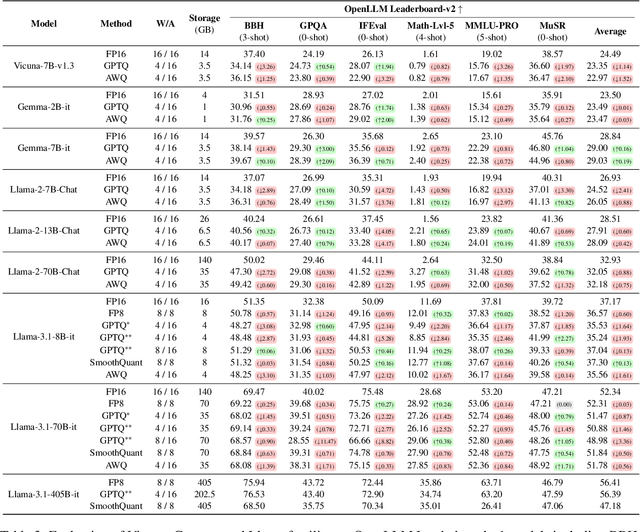
Prior research works have evaluated quantized LLMs using limited metrics such as perplexity or a few basic knowledge tasks and old datasets. Additionally, recent large-scale models such as Llama 3.1 with up to 405B have not been thoroughly examined. This paper evaluates the performance of instruction-tuned LLMs across various quantization methods (GPTQ, AWQ, SmoothQuant, and FP8) on models ranging from 7B to 405B. Using 13 benchmarks, we assess performance across six task types: commonsense Q\&A, knowledge and language understanding, instruction following, hallucination detection, mathematics, and dialogue. Our key findings reveal that (1) quantizing a larger LLM to a similar size as a smaller FP16 LLM generally performs better across most benchmarks, except for hallucination detection and instruction following; (2) performance varies significantly with different quantization methods, model size, and bit-width, with weight-only methods often yielding better results in larger models; (3) task difficulty does not significantly impact accuracy degradation due to quantization; and (4) the MT-Bench evaluation method has limited discriminatory power among recent high-performing LLMs.
Weight Equalizing Shift Scaler-Coupled Post-training Quantization
Aug 13, 2020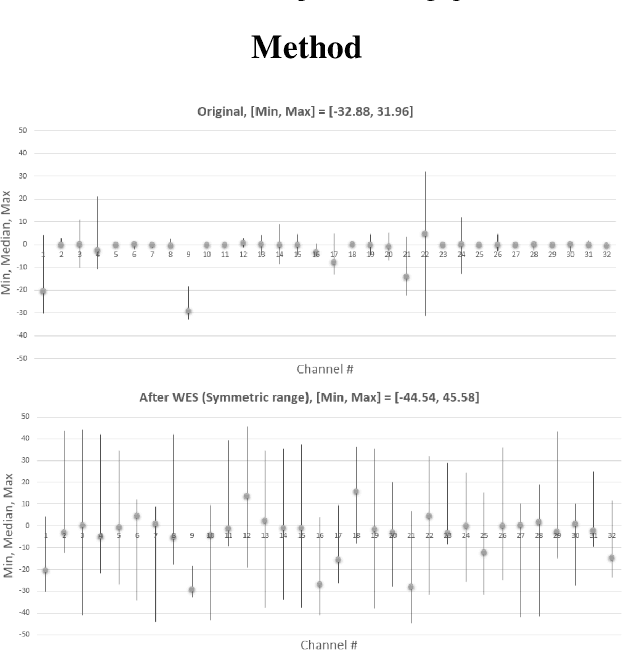
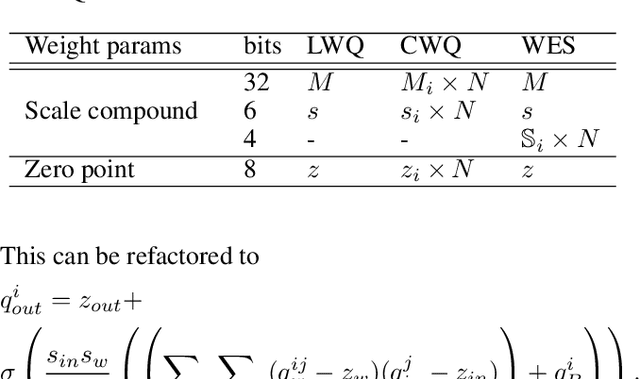
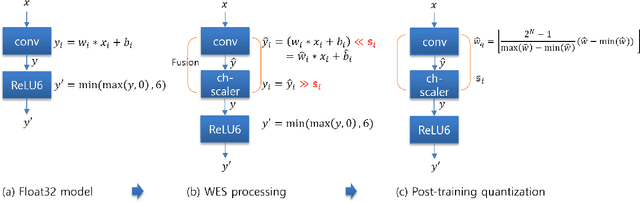
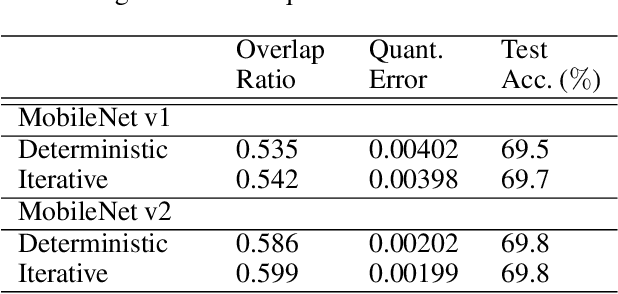
Post-training, layer-wise quantization is preferable because it is free from retraining and is hardware-friendly. Nevertheless, accuracy degradation has occurred when a neural network model has a big difference of per-out-channel weight ranges. In particular, the MobileNet family has a tragedy drop in top-1 accuracy from 70.60% ~ 71.87% to 0.1% on the ImageNet dataset after 8-bit weight quantization. To mitigate this significant accuracy reduction, we propose a new weight equalizing shift scaler, i.e. rescaling the weight range per channel by a 4-bit binary shift, prior to a layer-wise quantization. To recover the original output range, inverse binary shifting is efficiently fused to the existing per-layer scale compounding in the fixed-computing convolutional operator of the custom neural processing unit. The binary shift is a key feature of our algorithm, which significantly improved the accuracy performance without impeding the memory footprint. As a result, our proposed method achieved a top-1 accuracy of 69.78% ~ 70.96% in MobileNets and showed robust performance in varying network models and tasks, which is competitive to channel-wise quantization results.
Advancing GraphSAGE with A Data-Driven Node Sampling
Apr 29, 2019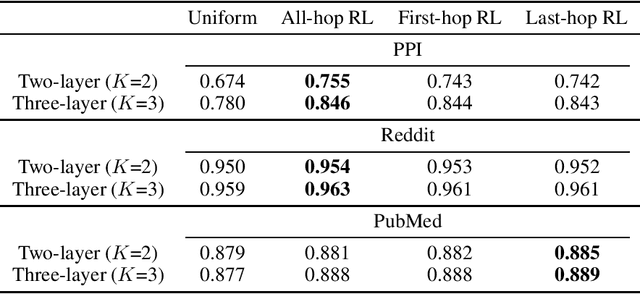
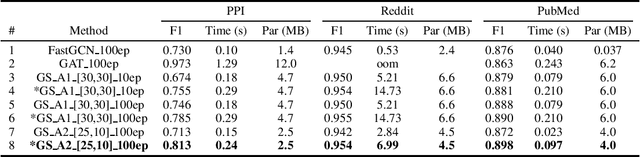
As an efficient and scalable graph neural network, GraphSAGE has enabled an inductive capability for inferring unseen nodes or graphs by aggregating subsampled local neighborhoods and by learning in a mini-batch gradient descent fashion. The neighborhood sampling used in GraphSAGE is effective in order to improve computing and memory efficiency when inferring a batch of target nodes with diverse degrees in parallel. Despite this advantage, the default uniform sampling suffers from high variance in training and inference, leading to sub-optimum accuracy. We propose a new data-driven sampling approach to reason about the real-valued importance of a neighborhood by a non-linear regressor, and to use the value as a criterion for subsampling neighborhoods. The regressor is learned using a value-based reinforcement learning. The implied importance for each combination of vertex and neighborhood is inductively extracted from the negative classification loss output of GraphSAGE. As a result, in an inductive node classification benchmark using three datasets, our method enhanced the baseline using the uniform sampling, outperforming recent variants of a graph neural network in accuracy.