 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight Equalizing Shift Scaler-Coupled Post-training Quantization
Paper and Code
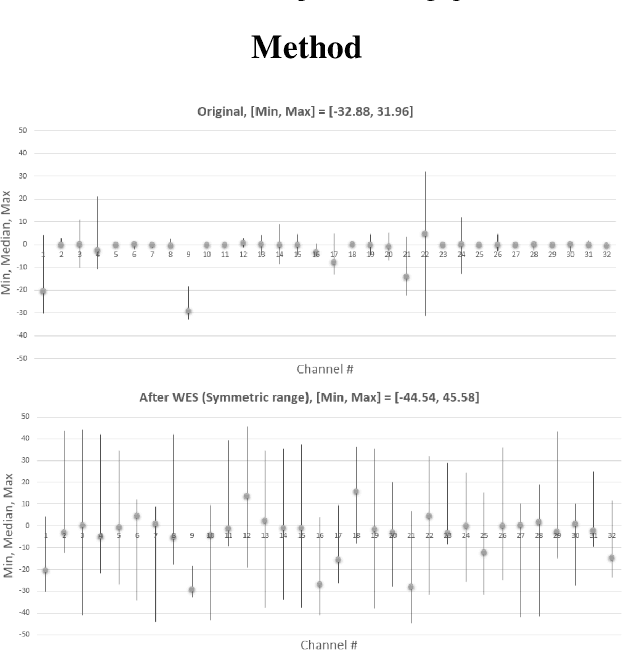
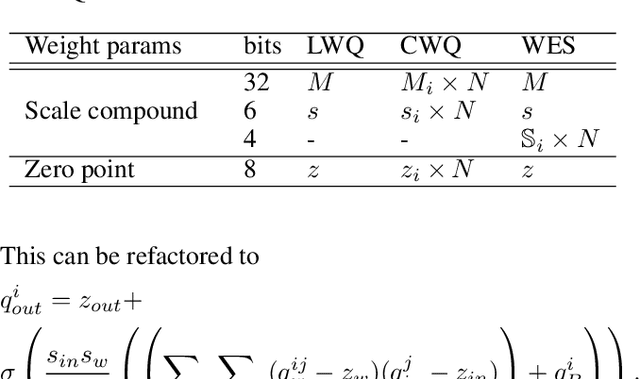
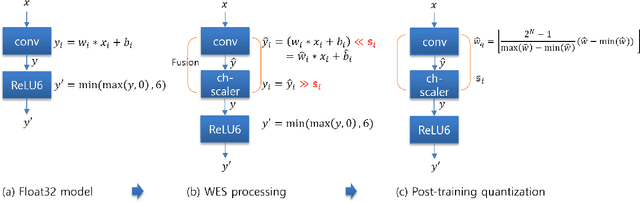
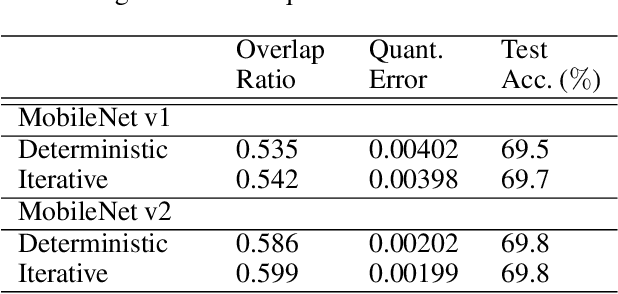
Post-training, layer-wise quantization is preferable because it is free from retraining and is hardware-friendly. Nevertheless, accuracy degradation has occurred when a neural network model has a big difference of per-out-channel weight ranges. In particular, the MobileNet family has a tragedy drop in top-1 accuracy from 70.60% ~ 71.87% to 0.1% on the ImageNet dataset after 8-bit weight quantization. To mitigate this significant accuracy reduction, we propose a new weight equalizing shift scaler, i.e. rescaling the weight range per channel by a 4-bit binary shift, prior to a layer-wise quantization. To recover the original output range, inverse binary shifting is efficiently fused to the existing per-layer scale compounding in the fixed-computing convolutional operator of the custom neural processing unit. The binary shift is a key feature of our algorithm, which significantly improved the accuracy performance without impeding the memory footprint. As a result, our proposed method achieved a top-1 accuracy of 69.78% ~ 70.96% in MobileNets and showed robust performance in varying network models and tasks, which is competitive to channel-wise quantization results.