 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight Equalizing Shift Scaler-Coupled Post-training Quantization
Aug 13, 2020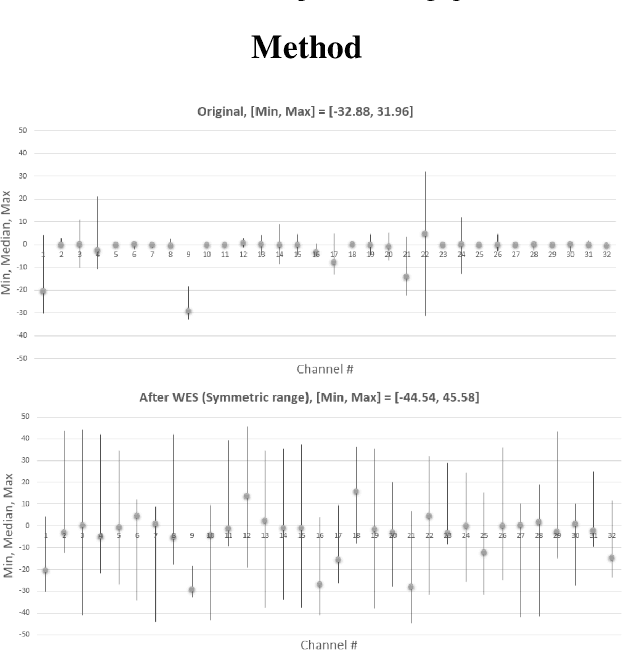
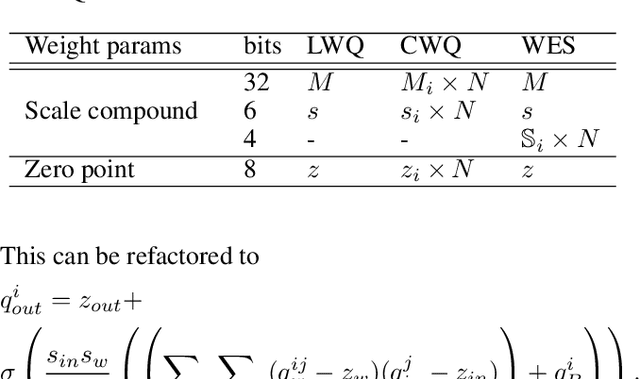
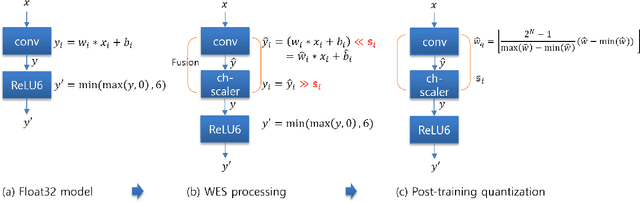
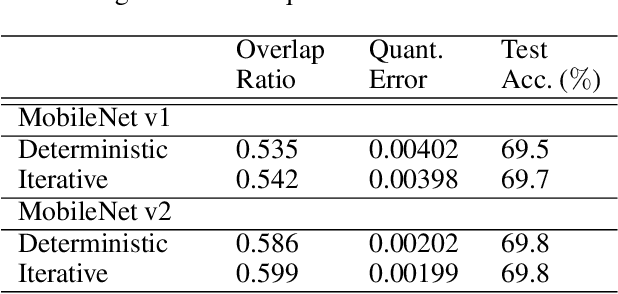
Post-training, layer-wise quantization is preferable because it is free from retraining and is hardware-friendly. Nevertheless, accuracy degradation has occurred when a neural network model has a big difference of per-out-channel weight ranges. In particular, the MobileNet family has a tragedy drop in top-1 accuracy from 70.60% ~ 71.87% to 0.1% on the ImageNet dataset after 8-bit weight quantization. To mitigate this significant accuracy reduction, we propose a new weight equalizing shift scaler, i.e. rescaling the weight range per channel by a 4-bit binary shift, prior to a layer-wise quantization. To recover the original output range, inverse binary shifting is efficiently fused to the existing per-layer scale compounding in the fixed-computing convolutional operator of the custom neural processing unit. The binary shift is a key feature of our algorithm, which significantly improved the accuracy performance without impeding the memory footprint. As a result, our proposed method achieved a top-1 accuracy of 69.78% ~ 70.96% in MobileNets and showed robust performance in varying network models and tasks, which is competitive to channel-wise quantization results.
SqueezeNext: Hardware-Aware Neural Network Design
Aug 27, 2018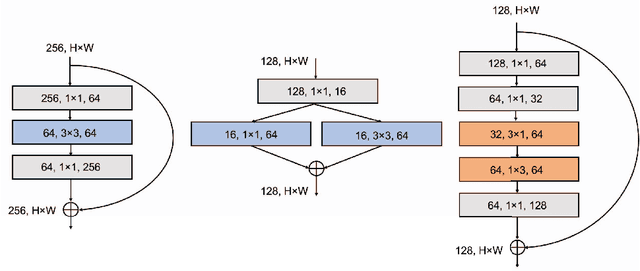
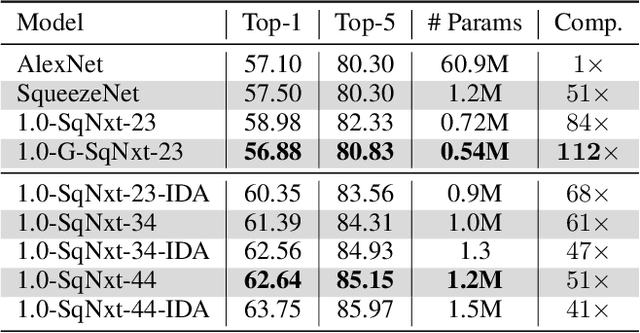
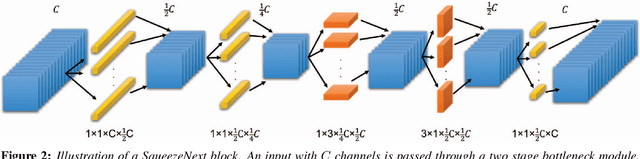
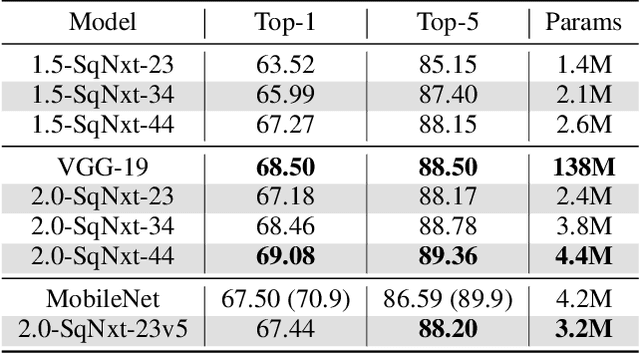
One of the main barriers for deploying neural networks on embedded systems has been large memory and power consumption of existing neural networks. In this work, we introduce SqueezeNext, a new family of neural network architectures whose design was guided by considering previous architectures such as SqueezeNet, as well as by simulation results on a neural network accelerator. This new network is able to match AlexNet's accuracy on the ImageNet benchmark with $112\times$ fewer parameters, and one of its deeper variants is able to achieve VGG-19 accuracy with only 4.4 Million parameters, ($31\times$ smaller than VGG-19). SqueezeNext also achieves better top-5 classification accuracy with $1.3\times$ fewer parameters as compared to MobileNet, but avoids using depthwise-separable convolutions that are inefficient on some mobile processor platforms. This wide range of accuracy gives the user the ability to make speed-accuracy tradeoffs, depending on the available resources on the target hardware. Using hardware simulation results for power and inference speed on an embedded system has guided us to design variations of the baseline model that are $2.59\times$/$8.26\times$ faster and $2.25\times$/$7.5\times$ more energy efficient as compared to SqueezeNet/AlexNet without any accuracy degradation.