 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Selective Survey on Versatile Knowledge Distillation Paradigm for Neural Network Models
Nov 30, 2020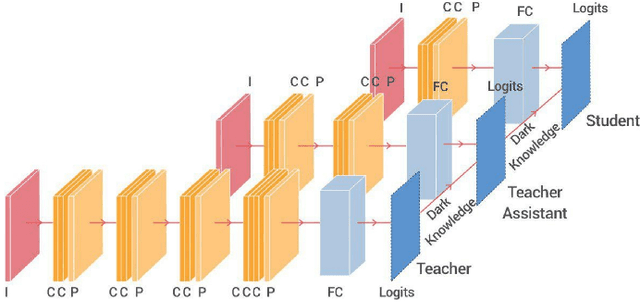
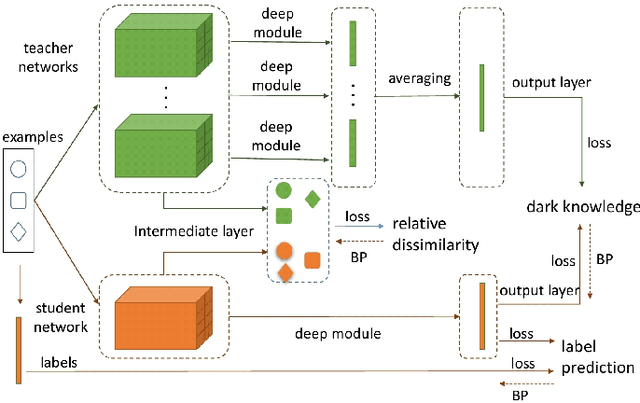
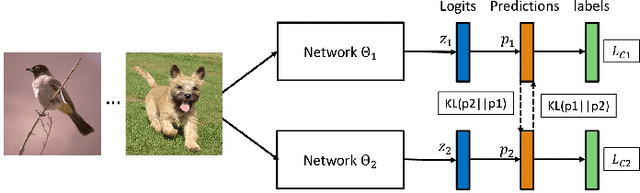
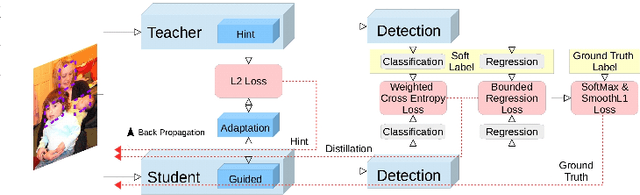
This paper aims to provide a selective survey about knowledge distillation(KD) framework for researchers and practitioners to take advantage of it for developing new optimized models in the deep neural network field. To this end, we give a brief overview of knowledge distillation and some related works including learning using privileged information(LUPI) and generalized distillation(GD). Even though knowledge distillation based on the teacher-student architecture was initially devised as a model compression technique, it has found versatile applications over various frameworks. In this paper, we review the characteristics of knowledge distillation from the hypothesis that the three important ingredients of knowledge distillation are distilled knowledge and loss,teacher-student paradigm, and the distillation process. In addition, we survey the versatility of the knowledge distillation by studying its direct applications and its usage in combination with other deep learning paradigms. Finally we present some future works in knowledge distillation including explainable knowledge distillation where the analytical analysis of the performance gain is studied and the self-supervised learning which is a hot research topic in deep learning community.
Weight Equalizing Shift Scaler-Coupled Post-training Quantization
Aug 13, 2020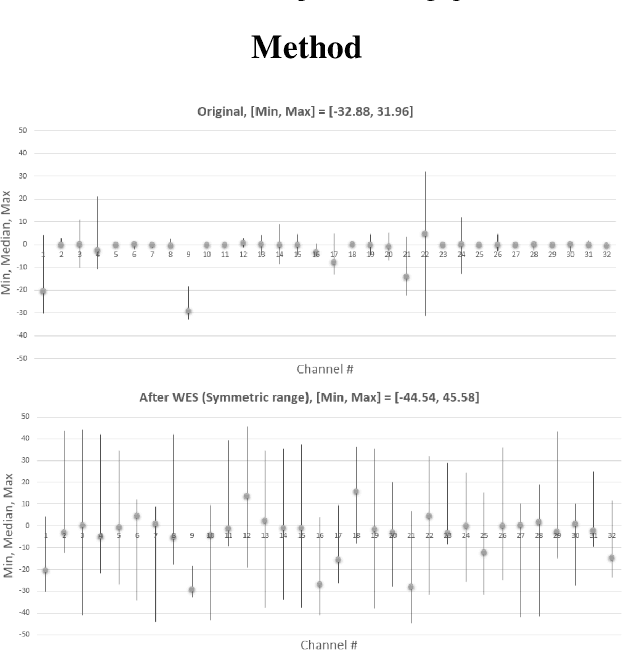
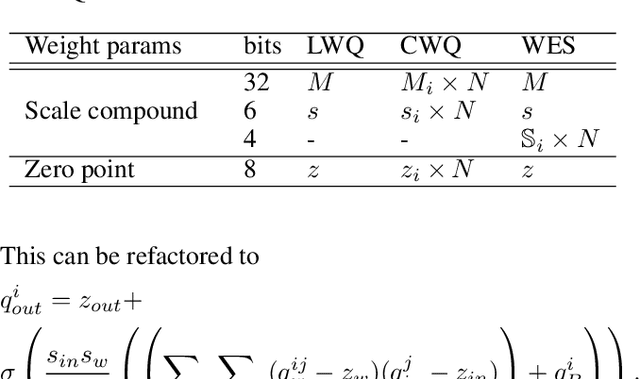
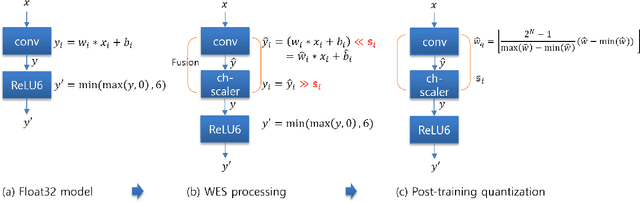
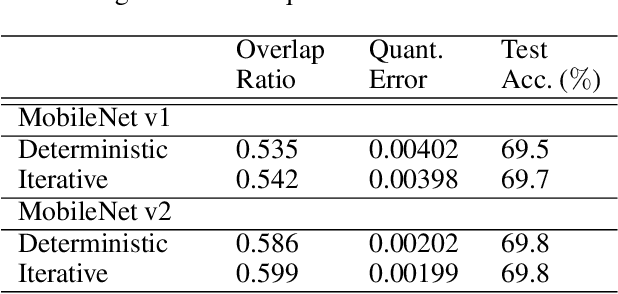
Post-training, layer-wise quantization is preferable because it is free from retraining and is hardware-friendly. Nevertheless, accuracy degradation has occurred when a neural network model has a big difference of per-out-channel weight ranges. In particular, the MobileNet family has a tragedy drop in top-1 accuracy from 70.60% ~ 71.87% to 0.1% on the ImageNet dataset after 8-bit weight quantization. To mitigate this significant accuracy reduction, we propose a new weight equalizing shift scaler, i.e. rescaling the weight range per channel by a 4-bit binary shift, prior to a layer-wise quantization. To recover the original output range, inverse binary shifting is efficiently fused to the existing per-layer scale compounding in the fixed-computing convolutional operator of the custom neural processing unit. The binary shift is a key feature of our algorithm, which significantly improved the accuracy performance without impeding the memory footprint. As a result, our proposed method achieved a top-1 accuracy of 69.78% ~ 70.96% in MobileNets and showed robust performance in varying network models and tasks, which is competitive to channel-wise quantization results.
Iterative Compression of End-to-End ASR Model using AutoML
Aug 06, 2020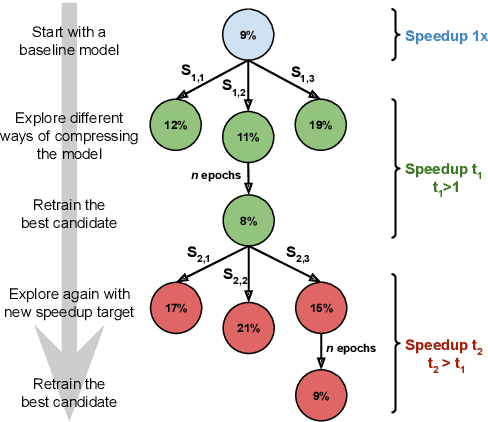
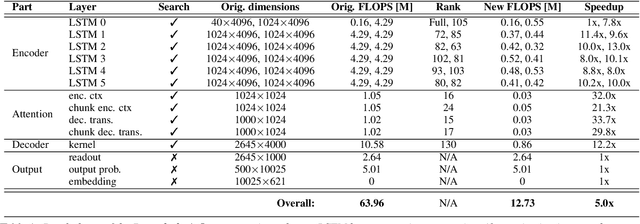
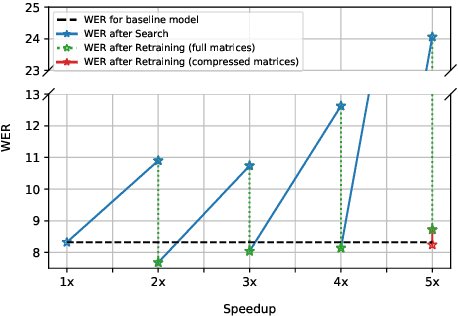
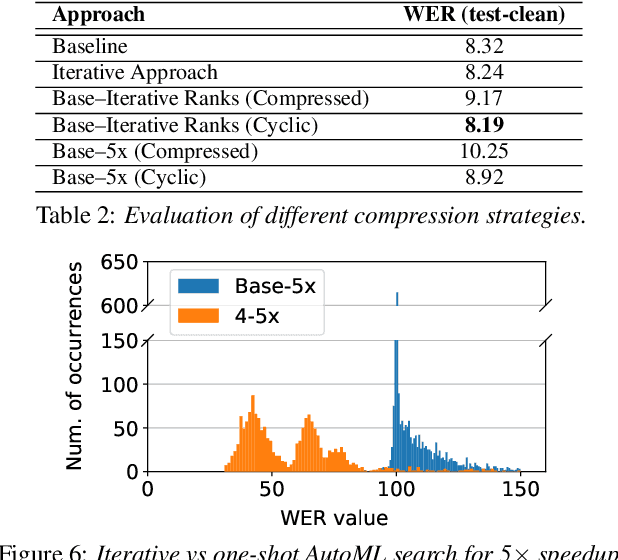
Increasing demand for on-device Automatic Speech Recognition (ASR) systems has resulted in renewed interests in developing automatic model compression techniques. Past research have shown that AutoML-based Low Rank Factorization (LRF) technique, when applied to an end-to-end Encoder-Attention-Decoder style ASR model, can achieve a speedup of up to 3.7x, outperforming laborious manual rank-selection approaches. However, we show that current AutoML-based search techniques only work up to a certain compression level, beyond which they fail to produce compressed models with acceptable word error rates (WER). In this work, we propose an iterative AutoML-based LRF approach that achieves over 5x compression without degrading the WER, thereby advancing the state-of-the-art in ASR compression.