 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBunched LPCNet : Vocoder for Low-cost Neural Text-To-Speech Systems
Aug 11, 2020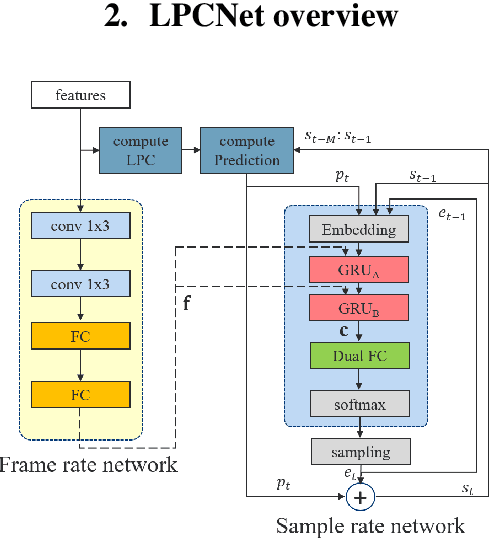
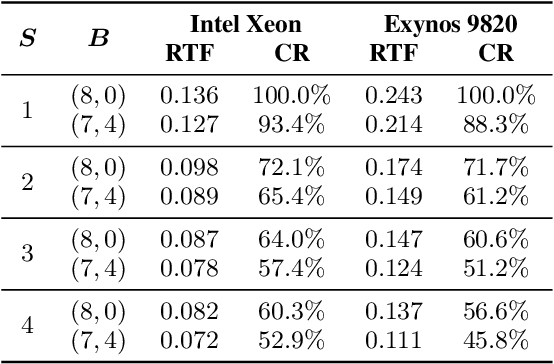
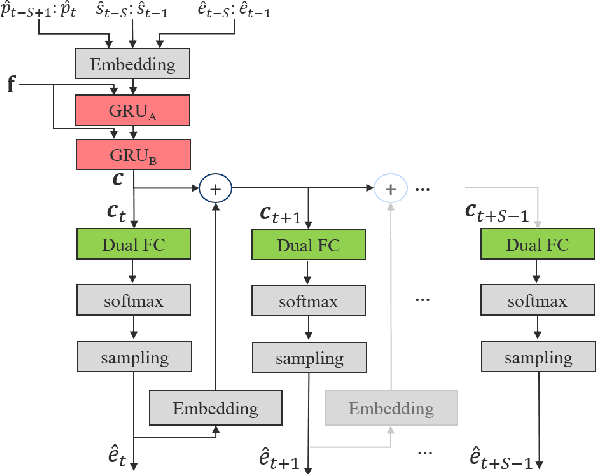
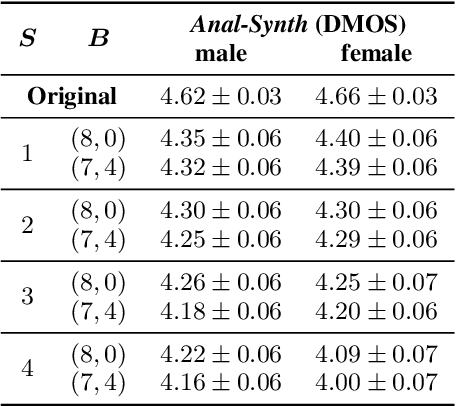
LPCNet is an efficient vocoder that combines linear prediction and deep neural network modules to keep the computational complexity low. In this work, we present two techniques to further reduce it's complexity, aiming for a low-cost LPCNet vocoder-based neural Text-to-Speech (TTS) System. These techniques are: 1) Sample-bunching, which allows LPCNet to generate more than one audio sample per inference; and 2) Bit-bunching, which reduces the computations in the final layer of LPCNet. With the proposed bunching techniques, LPCNet, in conjunction with a Deep Convolutional TTS (DCTTS) acoustic model, shows a 2.19x improvement over the baseline run-time when running on a mobile device, with a less than 0.1 decrease in TTS mean opinion score (MOS).
Iterative Compression of End-to-End ASR Model using AutoML
Aug 06, 2020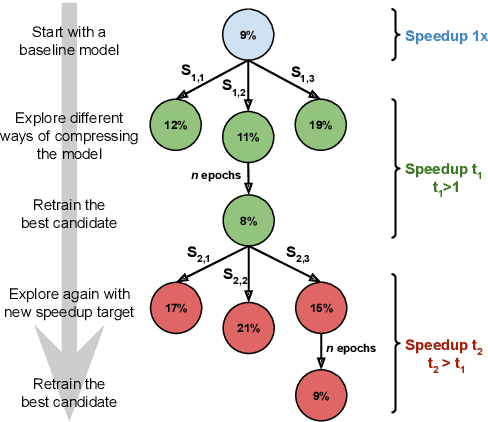
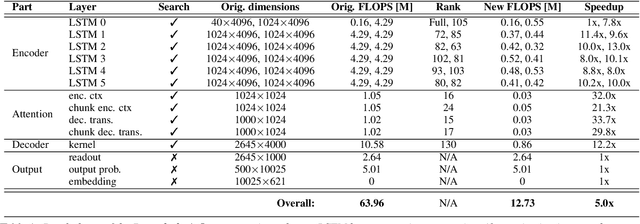
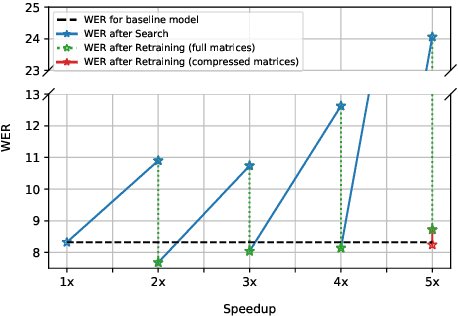
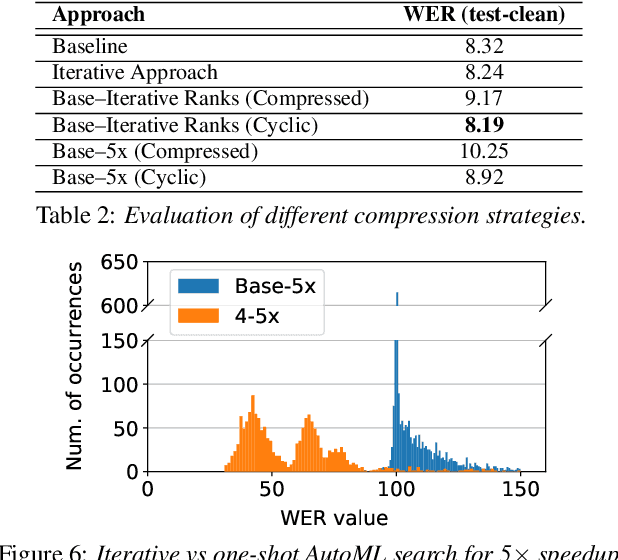
Increasing demand for on-device Automatic Speech Recognition (ASR) systems has resulted in renewed interests in developing automatic model compression techniques. Past research have shown that AutoML-based Low Rank Factorization (LRF) technique, when applied to an end-to-end Encoder-Attention-Decoder style ASR model, can achieve a speedup of up to 3.7x, outperforming laborious manual rank-selection approaches. However, we show that current AutoML-based search techniques only work up to a certain compression level, beyond which they fail to produce compressed models with acceptable word error rates (WER). In this work, we propose an iterative AutoML-based LRF approach that achieves over 5x compression without degrading the WER, thereby advancing the state-of-the-art in ASR compression.