 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
Utility-Learning Tension in Self-Modifying Agents
Oct 05, 2025As systems trend toward superintelligence, a natural modeling premise is that agents can self-improve along every facet of their own design. We formalize this with a five-axis decomposition and a decision layer, separating incentives from learning behavior and analyzing axes in isolation. Our central result identifies and introduces a sharp utility--learning tension, the structural conflict in self-modifying systems whereby utility-driven changes that improve immediate or expected performance can also erode the statistical preconditions for reliable learning and generalization. Our findings show that distribution-free guarantees are preserved iff the policy-reachable model family is uniformly capacity-bounded; when capacity can grow without limit, utility-rational self-changes can render learnable tasks unlearnable. Under standard assumptions common in practice, these axes reduce to the same capacity criterion, yielding a single boundary for safe self-modification. Numerical experiments across several axes validate the theory by comparing destructive utility policies against our proposed two-gate policies that preserve learnability.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Driving Safety Prediction and Safe Route Mapping Using In-vehicle and Roadside Data
Sep 12, 2022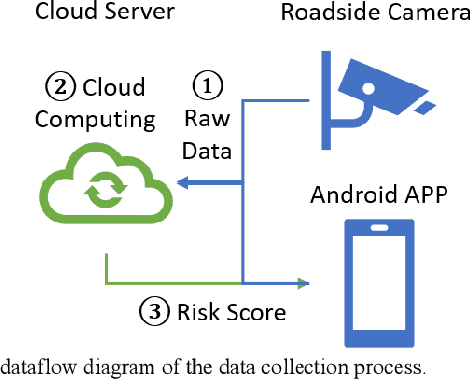
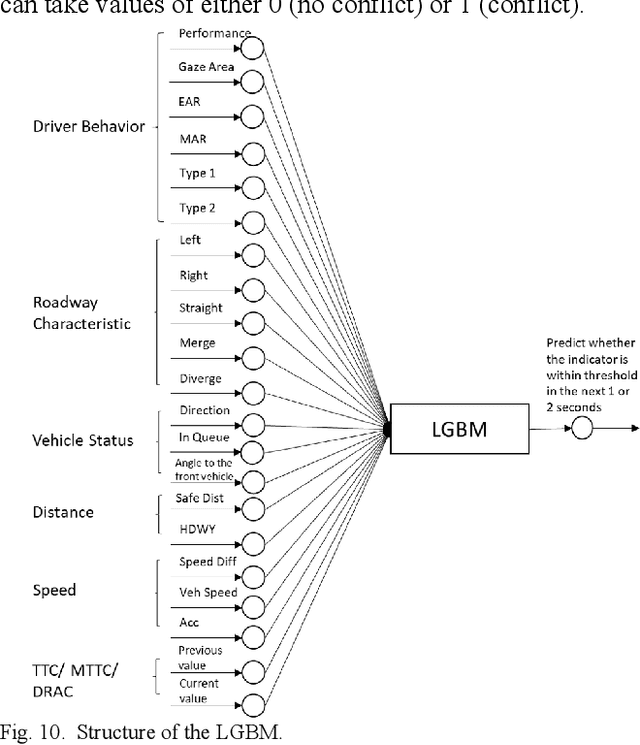
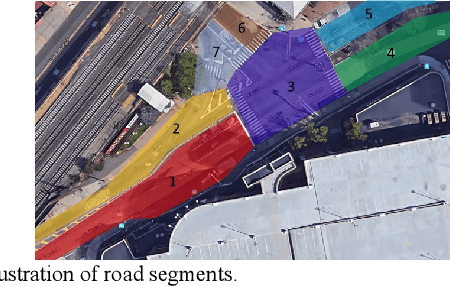
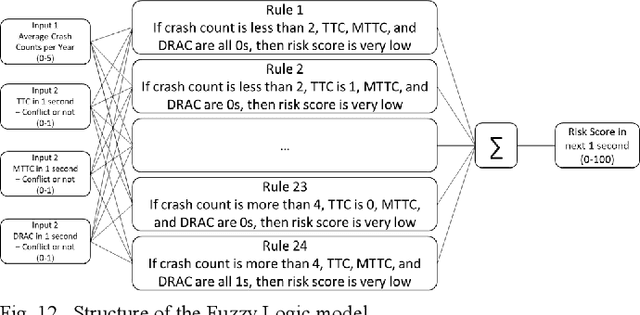
Risk assessment of roadways is commonly practiced based on historical crash data. Information on driver behaviors and real-time traffic situations is sometimes missing. In this paper, the Safe Route Mapping (SRM) model, a methodology for developing dynamic risk heat maps of roadways, is extended to consider driver behaviors when making predictions. An Android App is designed to gather drivers' information and upload it to a server. On the server, facial recognition extracts drivers' data, such as facial landmarks, gaze directions, and emotions. The driver's drowsiness and distraction are detected, and driving performance is evaluated. Meanwhile, dynamic traffic information is captured by a roadside camera and uploaded to the same server. A longitudinal-scanline-based arterial traffic video analytics is applied to recognize vehicles from the video to build speed and trajectory profiles. Based on these data, a LightGBM model is introduced to predict conflict indices for drivers in the next one or two seconds. Then, multiple data sources, including historical crash counts and predicted traffic conflict indicators, are combined using a Fuzzy logic model to calculate risk scores for road segments. The proposed SRM model is illustrated using data collected from an actual traffic intersection and a driving simulation platform. The prediction results show that the model is accurate, and the added driver behavior features will improve the model's performance. Finally, risk heat maps are generated for visualization purposes. The authorities can use the dynamic heat map to designate safe corridors and dispatch law enforcement and drivers for early warning and trip planning.
Regret Minimization for Partially Observable Deep Reinforcement Learning
Oct 25, 2018

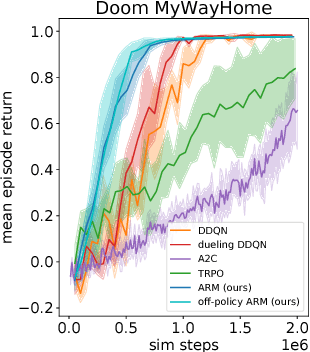

Deep reinforcement learning algorithms that estimate state and state-action value functions have been shown to be effective in a variety of challenging domains, including learning control strategies from raw image pixels. However, algorithms that estimate state and state-action value functions typically assume a fully observed state and must compensate for partial observations by using finite length observation histories or recurrent networks. In this work, we propose a new deep reinforcement learning algorithm based on counterfactual regret minimization that iteratively updates an approximation to an advantage-like function and is robust to partially observed state. We demonstrate that this new algorithm can substantially outperform strong baseline methods on several partially observed reinforcement learning tasks: learning first-person 3D navigation in Doom and Minecraft, and acting in the presence of partially observed objects in Doom and Pong.
A Novel Domain Adaptation Framework for Medical Image Segmentation
Oct 11, 2018

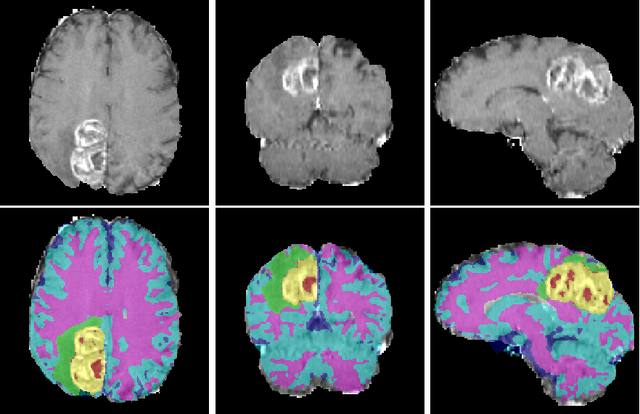

We propose a segmentation framework that uses deep neural networks and introduce two innovations. First, we describe a biophysics-based domain adaptation method. Second, we propose an automatic method to segment white and gray matter, and cerebrospinal fluid, in addition to tumorous tissue. Regarding our first innovation, we use a domain adaptation framework that combines a novel multispecies biophysical tumor growth model with a generative adversarial model to create realistic looking synthetic multimodal MR images with known segmentation. Regarding our second innovation, we propose an automatic approach to enrich available segmentation data by computing the segmentation for healthy tissues. This segmentation, which is done using diffeomorphic image registration between the BraTS training data and a set of prelabeled atlases, provides more information for training and reduces the class imbalance problem. Our overall approach is not specific to any particular neural network and can be used in conjunction with existing solutions. We demonstrate the performance improvement using a 2D U-Net for the BraTS'18 segmentation challenge. Our biophysics based domain adaptation achieves better results, as compared to the existing state-of-the-art GAN model used to create synthetic data for training.
SqueezeNext: Hardware-Aware Neural Network Design
Aug 27, 2018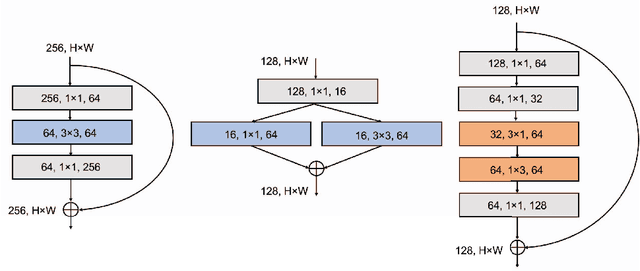
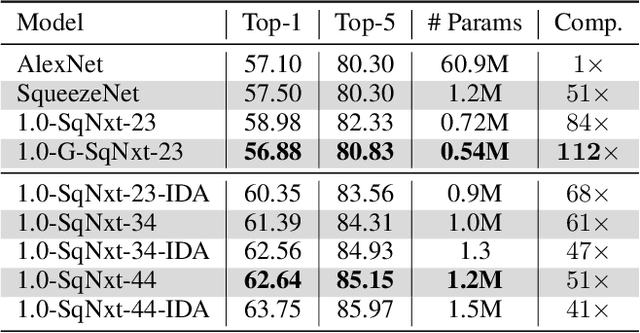
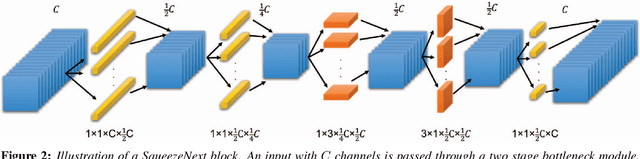
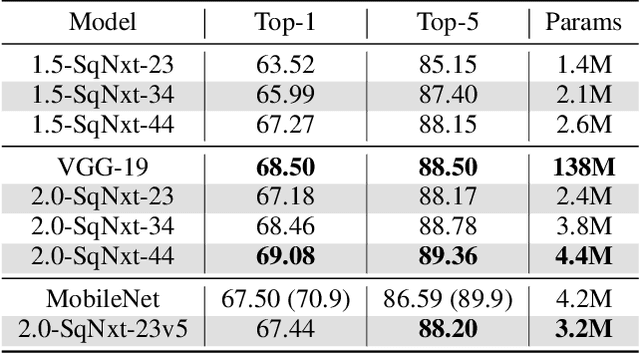
One of the main barriers for deploying neural networks on embedded systems has been large memory and power consumption of existing neural networks. In this work, we introduce SqueezeNext, a new family of neural network architectures whose design was guided by considering previous architectures such as SqueezeNet, as well as by simulation results on a neural network accelerator. This new network is able to match AlexNet's accuracy on the ImageNet benchmark with $112\times$ fewer parameters, and one of its deeper variants is able to achieve VGG-19 accuracy with only 4.4 Million parameters, ($31\times$ smaller than VGG-19). SqueezeNext also achieves better top-5 classification accuracy with $1.3\times$ fewer parameters as compared to MobileNet, but avoids using depthwise-separable convolutions that are inefficient on some mobile processor platforms. This wide range of accuracy gives the user the ability to make speed-accuracy tradeoffs, depending on the available resources on the target hardware. Using hardware simulation results for power and inference speed on an embedded system has guided us to design variations of the baseline model that are $2.59\times$/$8.26\times$ faster and $2.25\times$/$7.5\times$ more energy efficient as compared to SqueezeNet/AlexNet without any accuracy degradation.
Integrated Model, Batch and Domain Parallelism in Training Neural Networks
May 16, 2018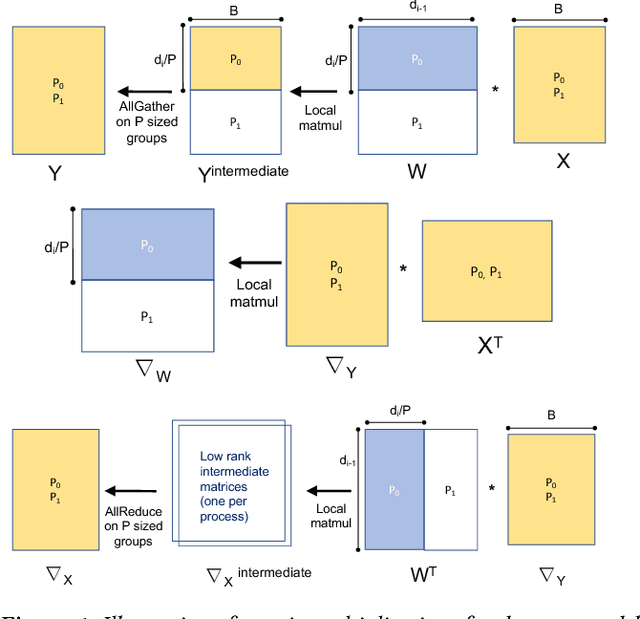
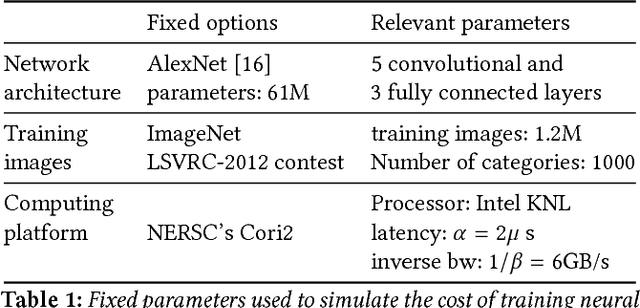
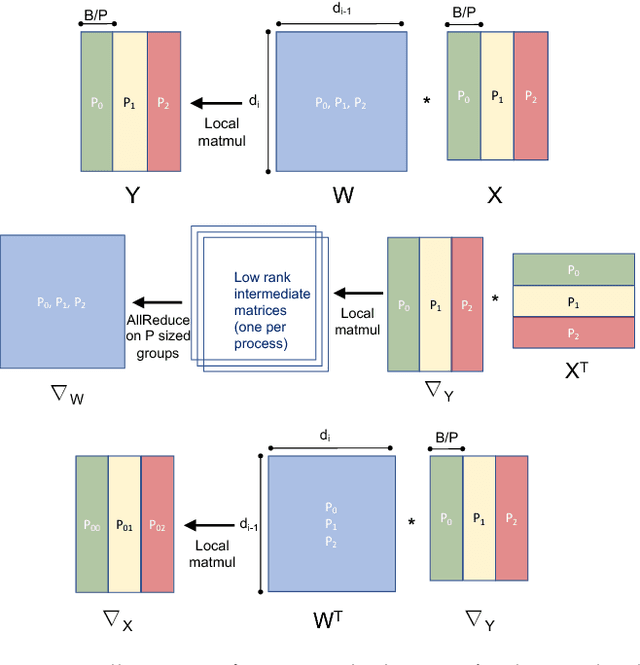

We propose a new integrated method of exploiting model, batch and domain parallelism for the training of deep neural networks (DNNs) on large distributed-memory computers using minibatch stochastic gradient descent (SGD). Our goal is to find an efficient parallelization strategy for a fixed batch size using $P$ processes. Our method is inspired by the communication-avoiding algorithms in numerical linear algebra. We see $P$ processes as logically divided into a $P_r \times P_c$ grid where the $P_r$ dimension is implicitly responsible for model/domain parallelism and the $P_c$ dimension is implicitly responsible for batch parallelism. In practice, the integrated matrix-based parallel algorithm encapsulates these types of parallelism automatically. We analyze the communication complexity and analytically demonstrate that the lowest communication costs are often achieved neither with pure model nor with pure data parallelism. We also show how the domain parallel approach can help in extending the theoretical scaling limit of the typical batch parallel method.
* 11 pages