 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegret Minimization for Partially Observable Deep Reinforcement Learning
Paper and Code


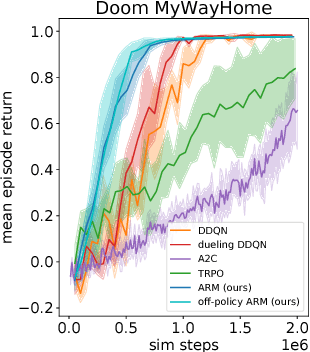

Deep reinforcement learning algorithms that estimate state and state-action value functions have been shown to be effective in a variety of challenging domains, including learning control strategies from raw image pixels. However, algorithms that estimate state and state-action value functions typically assume a fully observed state and must compensate for partial observations by using finite length observation histories or recurrent networks. In this work, we propose a new deep reinforcement learning algorithm based on counterfactual regret minimization that iteratively updates an approximation to an advantage-like function and is robust to partially observed state. We demonstrate that this new algorithm can substantially outperform strong baseline methods on several partially observed reinforcement learning tasks: learning first-person 3D navigation in Doom and Minecraft, and acting in the presence of partially observed objects in Doom and Pong.