 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Active Inference Agents for Delayed and Long-Horizon Environments
May 26, 2025With the recent success of world-model agents, which extend the core idea of model-based reinforcement learning by learning a differentiable model for sample-efficient control across diverse tasks, active inference (AIF) offers a complementary, neuroscience-grounded paradigm that unifies perception, learning, and action within a single probabilistic framework powered by a generative model. Despite this promise, practical AIF agents still rely on accurate immediate predictions and exhaustive planning, a limitation that is exacerbated in delayed environments requiring plans over long horizons, tens to hundreds of steps. Moreover, most existing agents are evaluated on robotic or vision benchmarks which, while natural for biological agents, fall short of real-world industrial complexity. We address these limitations with a generative-policy architecture featuring (i) a multi-step latent transition that lets the generative model predict an entire horizon in a single look-ahead, (ii) an integrated policy network that enables the transition and receives gradients of the expected free energy, (iii) an alternating optimization scheme that updates model and policy from a replay buffer, and (iv) a single gradient step that plans over long horizons, eliminating exhaustive planning from the control loop. We evaluate our agent in an environment that mimics a realistic industrial scenario with delayed and long-horizon settings. The empirical results confirm the effectiveness of the proposed approach, demonstrating the coupled world-model with the AIF formalism yields an end-to-end probabilistic controller capable of effective decision making in delayed, long-horizon settings without handcrafted rewards or expensive planning.
Prioritizing App Reviews for Developer Responses on Google Play
Feb 03, 2025The number of applications in Google Play has increased dramatically in recent years. On Google Play, users can write detailed reviews and rate apps, with these ratings significantly influencing app success and download numbers. Reviews often include notable information like feature requests, which are valuable for software maintenance. Users can update their reviews and ratings anytime. Studies indicate that apps with ratings below three stars are typically avoided by potential users. Since 2013, Google Play has allowed developers to respond to user reviews, helping resolve issues and potentially boosting overall ratings and download rates. However, responding to reviews is time-consuming, and only 13% to 18% of developers engage in this practice. To address this challenge, we propose a method to prioritize reviews based on response priority. We collected and preprocessed review data, extracted both textual and semantic features, and assessed their impact on the importance of responses. We labelled reviews as requiring a response or not and trained four different machine learning models to prioritize them. We evaluated the models performance using metrics such as F1-Score, Accuracy, Precision, and Recall. Our findings indicate that the XGBoost model is the most effective for prioritizing reviews needing a response.
Active Inference Meeting Energy-Efficient Control of Parallel and Identical Machines
Jun 13, 2024We investigate the application of active inference in developing energy-efficient control agents for manufacturing systems. Active inference, rooted in neuroscience, provides a unified probabilistic framework integrating perception, learning, and action, with inherent uncertainty quantification elements. Our study explores deep active inference, an emerging field that combines deep learning with the active inference decision-making framework. Leveraging a deep active inference agent, we focus on controlling parallel and identical machine workstations to enhance energy efficiency. We address challenges posed by the problem's stochastic nature and delayed policy response by introducing tailored enhancements to existing agent architectures. Specifically, we introduce multi-step transition and hybrid horizon methods to mitigate the need for complex planning. Our experimental results demonstrate the effectiveness of these enhancements and highlight the potential of the active inference-based approach.
Navigating Autonomous Vehicle on Unmarked Roads with Diffusion-Based Motion Prediction and Active Inference
May 31, 2024



This paper presents a novel approach to improving autonomous vehicle control in environments lacking clear road markings by integrating a diffusion-based motion predictor within an Active Inference Framework (AIF). Using a simulated parking lot environment as a parallel to unmarked roads, we develop and test our model to predict and guide vehicle movements effectively. The diffusion-based motion predictor forecasts vehicle actions by leveraging probabilistic dynamics, while AIF aids in decision-making under uncertainty. Unlike traditional methods such as Model Predictive Control (MPC) and Reinforcement Learning (RL), our approach reduces computational demands and requires less extensive training, enhancing navigation safety and efficiency. Our results demonstrate the model's capability to navigate complex scenarios, marking significant progress in autonomous driving technology.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Driving Safety Prediction and Safe Route Mapping Using In-vehicle and Roadside Data
Sep 12, 2022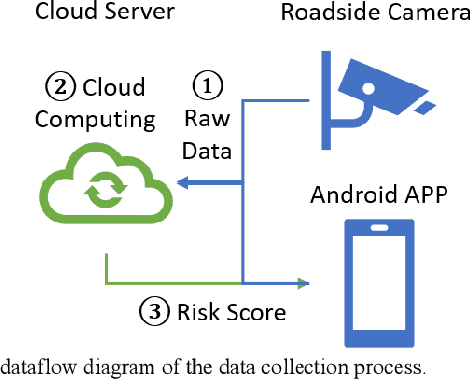
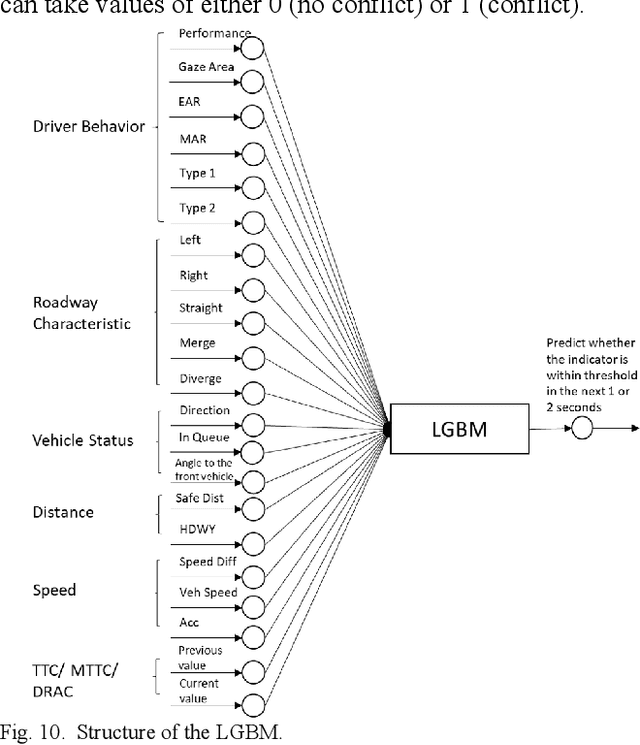
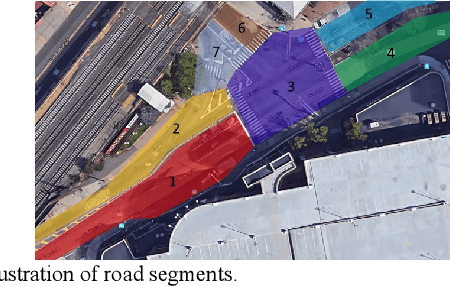
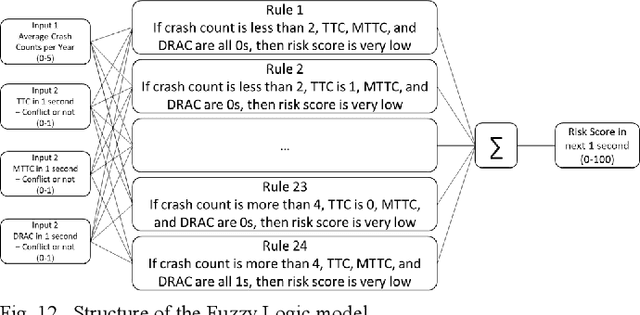
Risk assessment of roadways is commonly practiced based on historical crash data. Information on driver behaviors and real-time traffic situations is sometimes missing. In this paper, the Safe Route Mapping (SRM) model, a methodology for developing dynamic risk heat maps of roadways, is extended to consider driver behaviors when making predictions. An Android App is designed to gather drivers' information and upload it to a server. On the server, facial recognition extracts drivers' data, such as facial landmarks, gaze directions, and emotions. The driver's drowsiness and distraction are detected, and driving performance is evaluated. Meanwhile, dynamic traffic information is captured by a roadside camera and uploaded to the same server. A longitudinal-scanline-based arterial traffic video analytics is applied to recognize vehicles from the video to build speed and trajectory profiles. Based on these data, a LightGBM model is introduced to predict conflict indices for drivers in the next one or two seconds. Then, multiple data sources, including historical crash counts and predicted traffic conflict indicators, are combined using a Fuzzy logic model to calculate risk scores for road segments. The proposed SRM model is illustrated using data collected from an actual traffic intersection and a driving simulation platform. The prediction results show that the model is accurate, and the added driver behavior features will improve the model's performance. Finally, risk heat maps are generated for visualization purposes. The authorities can use the dynamic heat map to designate safe corridors and dispatch law enforcement and drivers for early warning and trip planning.
Real-time Driver Drowsiness Detection for Android Application Using Deep Neural Networks Techniques
Nov 05, 2018
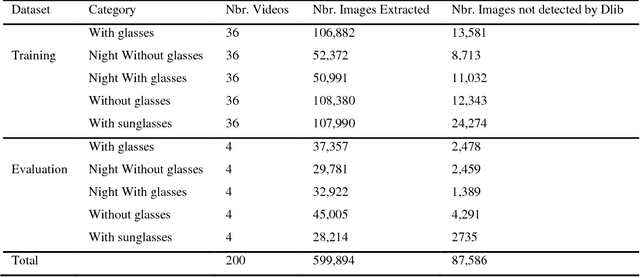


Road crashes and related forms of accidents are a common cause of injury and death among the human population. According to 2015 data from the World Health Organization, road traffic injuries resulted in approximately 1.25 million deaths worldwide, i.e. approximately every 25 seconds an individual will experience a fatal crash. While the cost of traffic accidents in Europe is estimated at around 160 billion Euros, driver drowsiness accounts for approximately 100,000 accidents per year in the United States alone as reported by The American National Highway Traffic Safety Administration (NHTSA). In this paper, a novel approach towards real-time drowsiness detection is proposed. This approach is based on a deep learning method that can be implemented on Android applications with high accuracy. The main contribution of this work is the compression of heavy baseline model to a lightweight model. Moreover, minimal network structure is designed based on facial landmark key point detection to recognize whether the driver is drowsy. The proposed model is able to achieve an accuracy of more than 80%. Keywords: Driver Monitoring System; Drowsiness Detection; Deep Learning; Real-time Deep Neural Network; Android.