 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrioritizing App Reviews for Developer Responses on Google Play
Feb 03, 2025The number of applications in Google Play has increased dramatically in recent years. On Google Play, users can write detailed reviews and rate apps, with these ratings significantly influencing app success and download numbers. Reviews often include notable information like feature requests, which are valuable for software maintenance. Users can update their reviews and ratings anytime. Studies indicate that apps with ratings below three stars are typically avoided by potential users. Since 2013, Google Play has allowed developers to respond to user reviews, helping resolve issues and potentially boosting overall ratings and download rates. However, responding to reviews is time-consuming, and only 13% to 18% of developers engage in this practice. To address this challenge, we propose a method to prioritize reviews based on response priority. We collected and preprocessed review data, extracted both textual and semantic features, and assessed their impact on the importance of responses. We labelled reviews as requiring a response or not and trained four different machine learning models to prioritize them. We evaluated the models performance using metrics such as F1-Score, Accuracy, Precision, and Recall. Our findings indicate that the XGBoost model is the most effective for prioritizing reviews needing a response.
An Efficient Model Maintenance Approach for MLOps
Dec 05, 2024In recent years, many industries have utilized machine learning models (ML) in their systems. Ideally, machine learning models should be trained on and applied to data from the same distributions. However, the data evolves over time in many application areas, leading to data and concept drift, which in turn causes the performance of the ML models to degrade over time. Therefore, maintaining up to date ML models plays a critical role in the MLOps pipeline. Existing ML model maintenance approaches are often computationally resource intensive, costly, time consuming, and model dependent. Thus, we propose an improved MLOps pipeline, a new model maintenance approach and a Similarity Based Model Reuse (SimReuse) tool to address the challenges of ML model maintenance. We identify seasonal and recurrent distribution patterns in time series datasets throughout a preliminary study. Recurrent distribution patterns enable us to reuse previously trained models for similar distributions in the future, thus avoiding frequent retraining. Then, we integrated the model reuse approach into the MLOps pipeline and proposed our improved MLOps pipeline. Furthermore, we develop SimReuse, a tool to implement the new components of our MLOps pipeline to store models and reuse them for inference of data segments with similar data distributions in the future. Our evaluation results on four time series datasets demonstrate that our model reuse approach can maintain the performance of models while significantly reducing maintenance time and costs. Our model reuse approach achieves ML performance comparable to the best baseline, while being 15 times more efficient in terms of computation time and costs. Therefore, industries and practitioners can benefit from our approach and use our tool to maintain the performance of their ML models in the deployment phase to reduce their maintenance costs.
An Empirical Study on the Usage of Automated Machine Learning Tools
Aug 28, 2022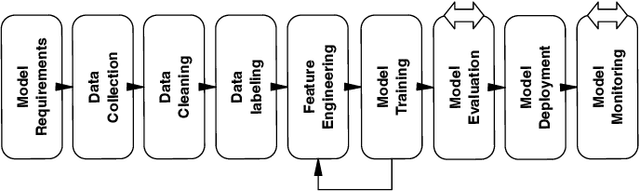
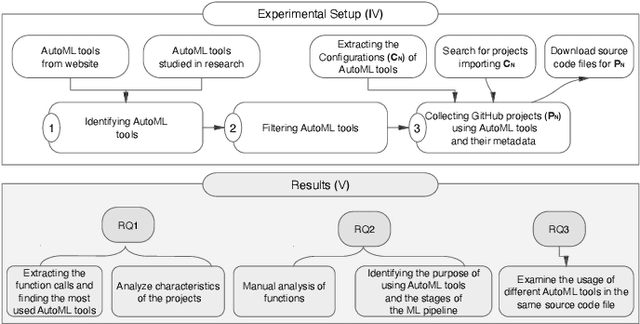

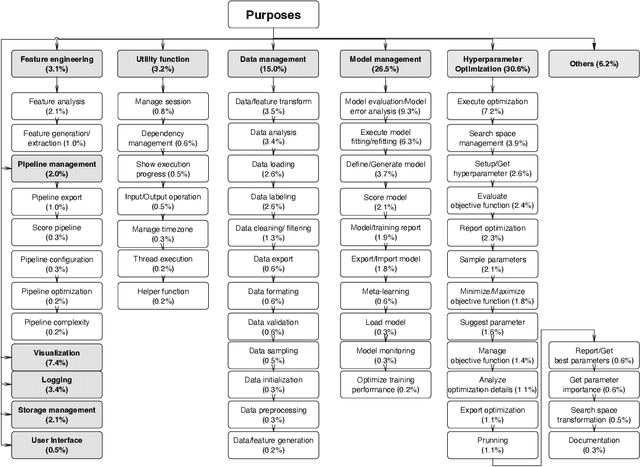
The popularity of automated machine learning (AutoML) tools in different domains has increased over the past few years. Machine learning (ML) practitioners use AutoML tools to automate and optimize the process of feature engineering, model training, and hyperparameter optimization and so on. Recent work performed qualitative studies on practitioners' experiences of using AutoML tools and compared different AutoML tools based on their performance and provided features, but none of the existing work studied the practices of using AutoML tools in real-world projects at a large scale. Therefore, we conducted an empirical study to understand how ML practitioners use AutoML tools in their projects. To this end, we examined the top 10 most used AutoML tools and their respective usages in a large number of open-source project repositories hosted on GitHub. The results of our study show 1) which AutoML tools are mostly used by ML practitioners and 2) the characteristics of the repositories that use these AutoML tools. Also, we identified the purpose of using AutoML tools (e.g. model parameter sampling, search space management, model evaluation/error-analysis, Data/ feature transformation, and data labeling) and the stages of the ML pipeline (e.g. feature engineering) where AutoML tools are used. Finally, we report how often AutoML tools are used together in the same source code files. We hope our results can help ML practitioners learn about different AutoML tools and their usages, so that they can pick the right tool for their purposes. Besides, AutoML tool developers can benefit from our findings to gain insight into the usages of their tools and improve their tools to better fit the users' usages and needs.
Studying the Practices of Deploying Machine Learning Projects on Docker
Jun 01, 2022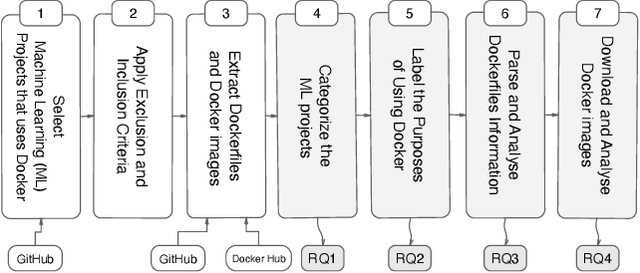
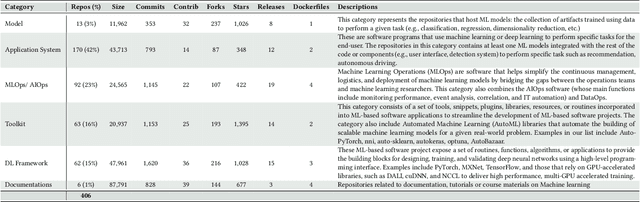
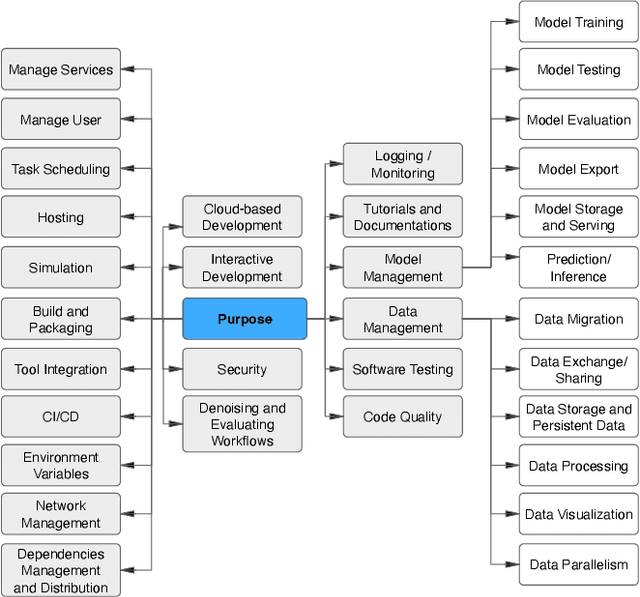

Docker is a containerization service that allows for convenient deployment of websites, databases, applications' APIs, and machine learning (ML) models with a few lines of code. Studies have recently explored the use of Docker for deploying general software projects with no specific focus on how Docker is used to deploy ML-based projects. In this study, we conducted an exploratory study to understand how Docker is being used to deploy ML-based projects. As the initial step, we examined the categories of ML-based projects that use Docker. We then examined why and how these projects use Docker, and the characteristics of the resulting Docker images. Our results indicate that six categories of ML-based projects use Docker for deployment, including ML Applications, MLOps/ AIOps, Toolkits, DL Frameworks, Models, and Documentation. We derived the taxonomy of 21 major categories representing the purposes of using Docker, including those specific to models such as model management tasks (e.g., testing, training). We then showed that ML engineers use Docker images mostly to help with the platform portability, such as transferring the software across the operating systems, runtimes such as GPU, and language constraints. However, we also found that more resources may be required to run the Docker images for building ML-based software projects due to the large number of files contained in the image layers with deeply nested directories. We hope to shed light on the emerging practices of deploying ML software projects using containers and highlight aspects that should be improved.