 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIA: Supervised Fine-Tuning of Large Language Models for Automatic Issue Assignment
Jan 05, 2026Issue assignment is a critical process in software maintenance, where new issue reports are validated and assigned to suitable developers. However, manual issue assignment is often inconsistent and error-prone, especially in large open-source projects where thousands of new issues are reported monthly. Existing automated approaches have shown promise, but many rely heavily on large volumes of project-specific training data or relational information that is often sparse and noisy, which limits their effectiveness. To address these challenges, we propose LIA (LLM-based Issue Assignment), which employs supervised fine-tuning to adapt an LLM, DeepSeek-R1-Distill-Llama-8B in this work, for automatic issue assignment. By leveraging the LLM's pretrained semantic understanding of natural language and software-related text, LIA learns to generate ranked developer recommendations directly from issue titles and descriptions. The ranking is based on the model's learned understanding of historical issue-to-developer assignments, using patterns from past tasks to infer which developers are most likely to handle new issues. Through comprehensive evaluation, we show that LIA delivers substantial improvements over both its base pretrained model and state-of-the-art baselines. It achieves up to +187.8% higher Hit@1 compared to the DeepSeek-R1-Distill-Llama-8B pretrained base model, and outperforms four leading issue assignment methods by as much as +211.2% in Hit@1 score. These results highlight the effectiveness of domain-adapted LLMs for software maintenance tasks and establish LIA as a practical, high-performing solution for issue assignment.
LinkAnchor: An Autonomous LLM-Based Agent for Issue-to-Commit Link Recovery
Aug 17, 2025Issue-to-commit link recovery plays an important role in software traceability and improves project management. However, it remains a challenging task. A study on GitHub shows that only 42.2% of the issues are correctly linked to their commits. This highlights the potential for further development and research in this area. Existing studies have employed various AI/ML-based approaches, and with the recent development of large language models, researchers have leveraged LLMs to tackle this problem. These approaches suffer from two main issues. First, LLMs are constrained by limited context windows and cannot ingest all of the available data sources, such as long commit histories, extensive issue comments, and large code repositories. Second, most methods operate on individual issue-commit pairs; that is, given a single issue-commit pair, they determine whether the commit resolves the issue. This quickly becomes impractical in real-world repositories containing tens of thousands of commits. To address these limitations, we present LinkAnchor, the first autonomous LLM-based agent designed for issue-to-commit link recovery. The lazy-access architecture of LinkAnchor enables the underlying LLM to access the rich context of software, spanning commits, issue comments, and code files, without exceeding the token limit by dynamically retrieving only the most relevant contextual data. Additionally, LinkAnchor is able to automatically pinpoint the target commit rather than exhaustively scoring every possible candidate. Our evaluations show that LinkAnchor outperforms state-of-the-art issue-to-commit link recovery approaches by 60-262% in Hit@1 score across all our case study projects. We also publicly release LinkAnchor as a ready-to-use tool, along with our replication package. LinkAnchor is designed and tested for GitHub and Jira, and is easily extendable to other platforms.
Prioritizing App Reviews for Developer Responses on Google Play
Feb 03, 2025The number of applications in Google Play has increased dramatically in recent years. On Google Play, users can write detailed reviews and rate apps, with these ratings significantly influencing app success and download numbers. Reviews often include notable information like feature requests, which are valuable for software maintenance. Users can update their reviews and ratings anytime. Studies indicate that apps with ratings below three stars are typically avoided by potential users. Since 2013, Google Play has allowed developers to respond to user reviews, helping resolve issues and potentially boosting overall ratings and download rates. However, responding to reviews is time-consuming, and only 13% to 18% of developers engage in this practice. To address this challenge, we propose a method to prioritize reviews based on response priority. We collected and preprocessed review data, extracted both textual and semantic features, and assessed their impact on the importance of responses. We labelled reviews as requiring a response or not and trained four different machine learning models to prioritize them. We evaluated the models performance using metrics such as F1-Score, Accuracy, Precision, and Recall. Our findings indicate that the XGBoost model is the most effective for prioritizing reviews needing a response.
Predicting the Understandability of Computational Notebooks through Code Metrics Analysis
Jun 16, 2024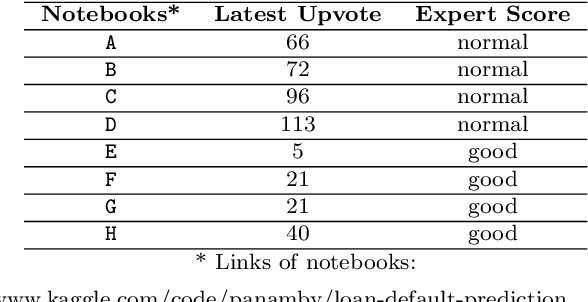
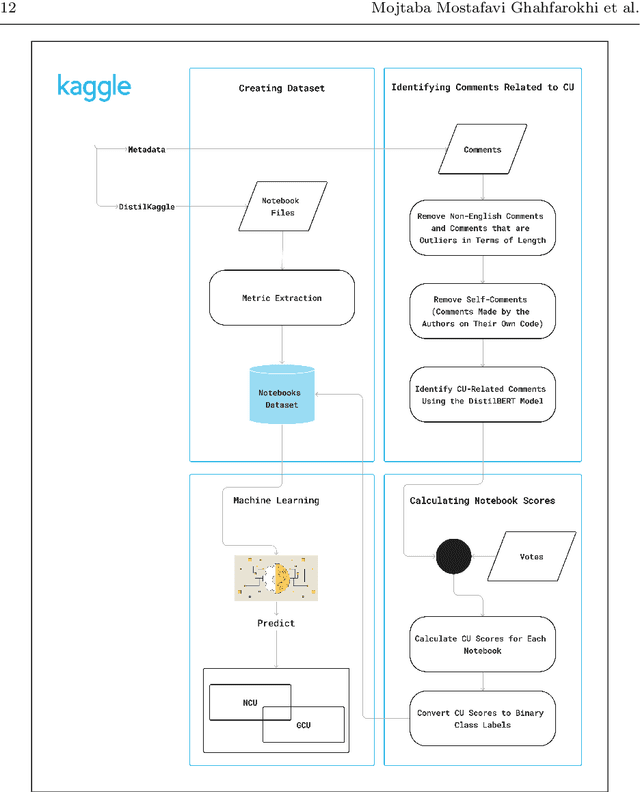
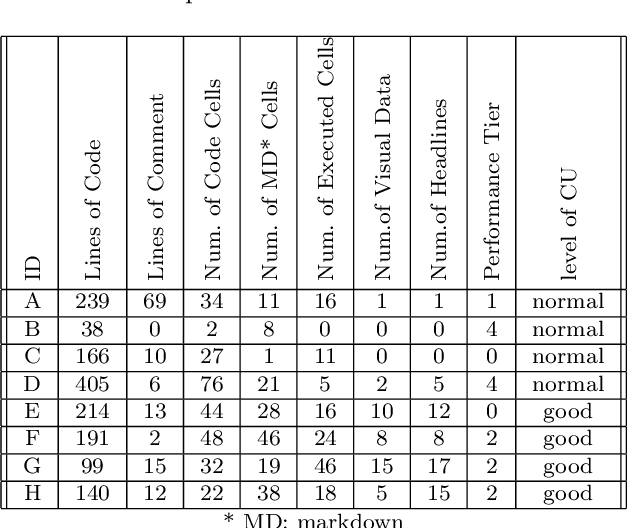
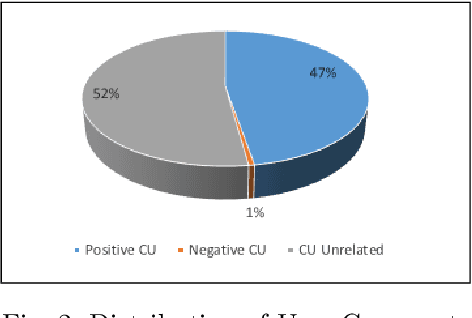
Computational notebooks have become the primary coding environment for data scientists. However, research on their code quality is still emerging, and the code shared is often of poor quality. Given the importance of maintenance and reusability, understanding the metrics that affect notebook code comprehensibility is crucial. Code understandability, a qualitative variable, is closely tied to user opinions. Traditional approaches to measuring it either use limited questionnaires to review a few code pieces or rely on metadata such as likes and votes in software repositories. Our approach enhances the measurement of Jupyter notebook understandability by leveraging user comments related to code understandability. As a case study, we used 542,051 Kaggle Jupyter notebooks from our previous research, named DistilKaggle. We employed a fine-tuned DistilBERT transformer to identify user comments associated with code understandability. We established a criterion called User Opinion Code Understandability (UOCU), which considers the number of relevant comments, upvotes on those comments, total notebook views, and total notebook upvotes. UOCU proved to be more effective than previous methods. Furthermore, we trained machine learning models to predict notebook code understandability based solely on their metrics. We collected 34 metrics for 132,723 final notebooks as features in our dataset, using UOCU as the label. Our predictive model, using the Random Forest classifier, achieved 89% accuracy in predicting the understandability levels of computational notebooks.
GIRT-Model: Automated Generation of Issue Report Templates
Feb 08, 2024
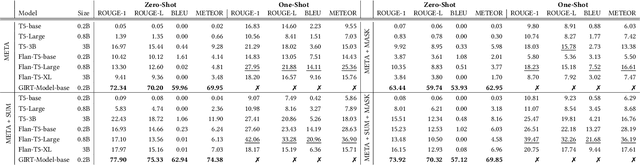
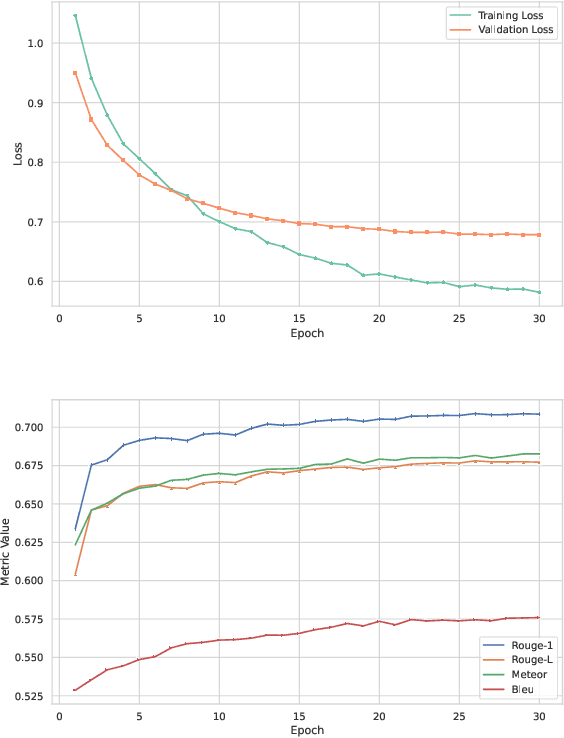
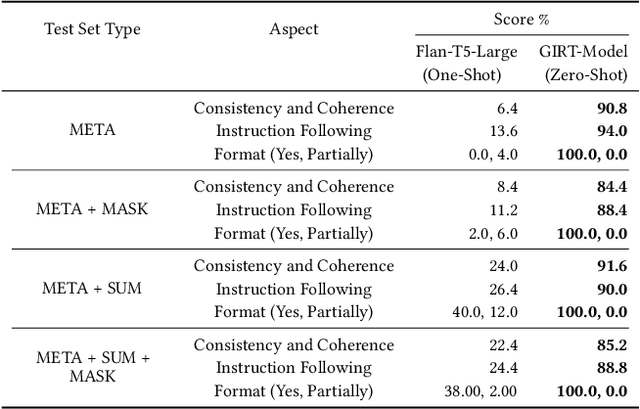
Platforms such as GitHub and GitLab introduce Issue Report Templates (IRTs) to enable more effective issue management and better alignment with developer expectations. However, these templates are not widely adopted in most repositories, and there is currently no tool available to aid developers in generating them. In this work, we introduce GIRT-Model, an assistant language model that automatically generates IRTs based on the developer's instructions regarding the structure and necessary fields. We create GIRT-Instruct, a dataset comprising pairs of instructions and IRTs, with the IRTs sourced from GitHub repositories. We use GIRT-Instruct to instruction-tune a T5-base model to create the GIRT-Model. In our experiments, GIRT-Model outperforms general language models (T5 and Flan-T5 with different parameter sizes) in IRT generation by achieving significantly higher scores in ROUGE, BLEU, METEOR, and human evaluation. Additionally, we analyze the effectiveness of GIRT-Model in a user study in which participants wrote short IRTs with GIRT-Model. Our results show that the participants find GIRT-Model useful in the automated generation of templates. We hope that through the use of GIRT-Model, we can encourage more developers to adopt IRTs in their repositories. We publicly release our code, dataset, and model at https://github.com/ISE-Research/girt-model.
MenuCraft: Interactive Menu System Design with Large Language Models
Mar 08, 2023Menu system design is a challenging task involving many design options and various human factors. For example, one crucial factor that designers need to consider is the semantic and systematic relation of menu commands. However, capturing these relations can be challenging due to limited available resources. With the advancement of neural language models, large language models can utilize their vast pre-existing knowledge in designing and refining menu systems. In this paper, we propose MenuCraft, an AI-assisted designer for menu design that enables collaboration between the designer and a dialogue system to design menus. MenuCraft offers an interactive language-based menu design tool that simplifies the menu design process and enables easy customization of design options. MenuCraft supports a variety of interactions through dialog that allows performing few-shot learning.
Semantically-enhanced Topic Recommendation System for Software Projects
May 31, 2022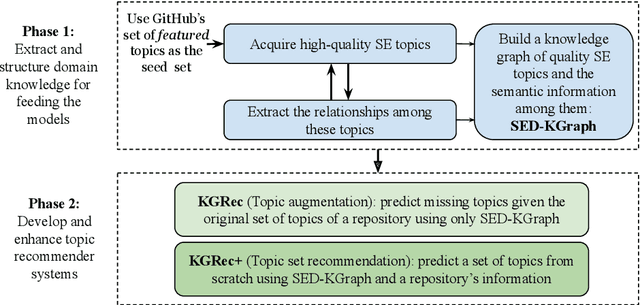

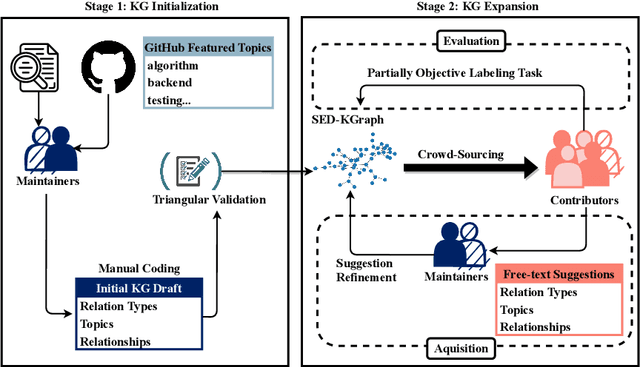
Software-related platforms have enabled their users to collaboratively label software entities with topics. Tagging software repositories with relevant topics can be exploited for facilitating various downstream tasks. For instance, a correct and complete set of topics assigned to a repository can increase its visibility. Consequently, this improves the outcome of tasks such as browsing, searching, navigation, and organization of repositories. Unfortunately, assigned topics are usually highly noisy, and some repositories do not have well-assigned topics. Thus, there have been efforts on recommending topics for software projects, however, the semantic relationships among these topics have not been exploited so far. We propose two recommender models for tagging software projects that incorporate the semantic relationship among topics. Our approach has two main phases; (1) we first take a collaborative approach to curate a dataset of quality topics specifically for the domain of software engineering and development. We also enrich this data with the semantic relationships among these topics and encapsulate them in a knowledge graph we call SED-KGraph. Then, (2) we build two recommender systems; The first one operates only based on the list of original topics assigned to a repository and the relationships specified in our knowledge graph. The second predictive model, however, assumes there are no topics available for a repository, hence it proceeds to predict the relevant topics based on both textual information of a software project and SED-KGraph. We built SED-KGraph in a crowd-sourced project with 170 contributors from both academia and industry. The experiment results indicate that our solutions outperform baselines that neglect the semantic relationships among topics by at least 25% and 23% in terms of ASR and MAP metrics.
Automated Recovery of Issue-Commit Links Leveraging Both Textual and Non-textual Data
Jul 05, 2021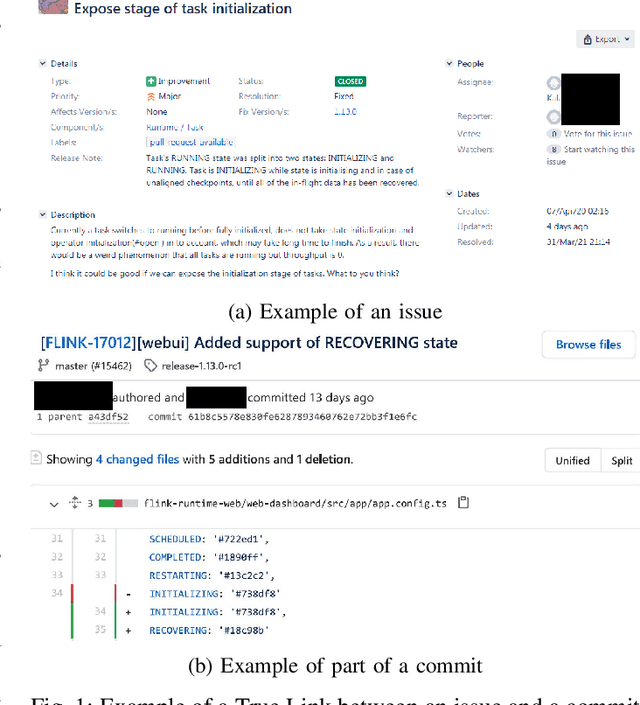
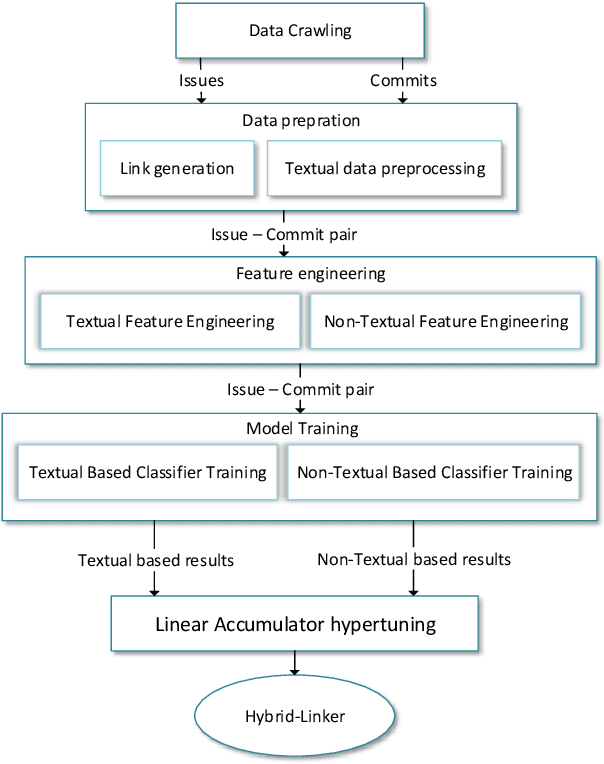
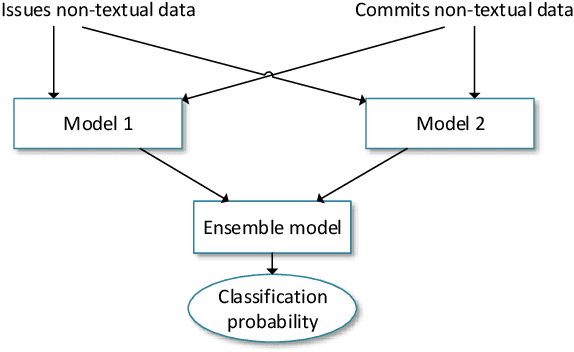
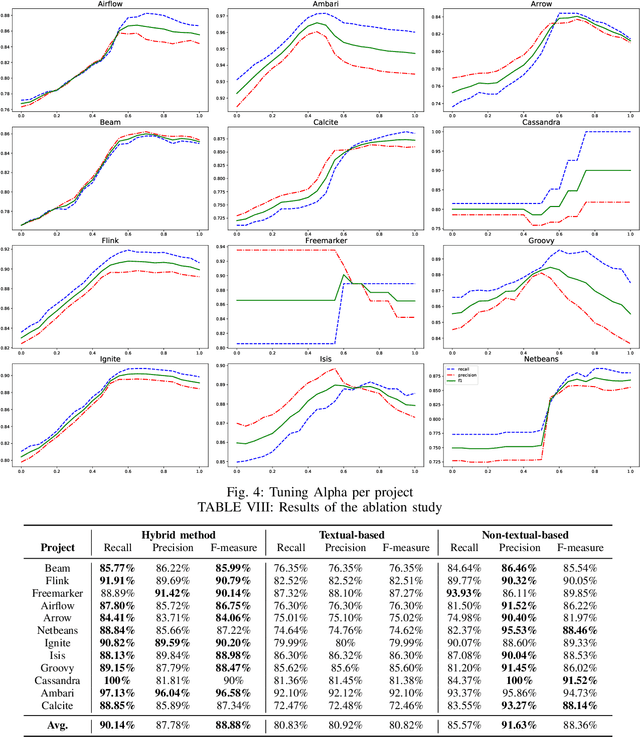
An issue documents discussions around required changes in issue-tracking systems, while a commit contains the change itself in the version control systems. Recovering links between issues and commits can facilitate many software evolution tasks such as bug localization, and software documentation. A previous study on over half a million issues from GitHub reports only about 42.2% of issues are manually linked by developers to their pertinent commits. Automating the linking of commit-issue pairs can contribute to the improvement of the said tasks. By far, current state-of-the-art approaches for automated commit-issue linking suffer from low precision, leading to unreliable results, sometimes to the point that imposes human supervision on the predicted links. The low performance gets even more severe when there is a lack of textual information in either commits or issues. Current approaches are also proven computationally expensive. We propose Hybrid-Linker to overcome such limitations by exploiting two information channels; (1) a non-textual-based component that operates on non-textual, automatically recorded information of the commit-issue pairs to predict a link, and (2) a textual-based one which does the same using textual information of the commit-issue pairs. Then, combining the results from the two classifiers, Hybrid-Linker makes the final prediction. Thus, every time one component falls short in predicting a link, the other component fills the gap and improves the results. We evaluate Hybrid-Linker against competing approaches, namely FRLink and DeepLink on a dataset of 12 projects. Hybrid-Linker achieves 90.1%, 87.8%, and 88.9% based on recall, precision, and F-measure, respectively. It also outperforms FRLink and DeepLink by 31.3%, and 41.3%, regarding the F-measure. Moreover, Hybrid-Linker exhibits extensive improvements in terms of performance as well.
Improving Quality of a Post's Set of Answers in Stack Overflow
May 30, 2020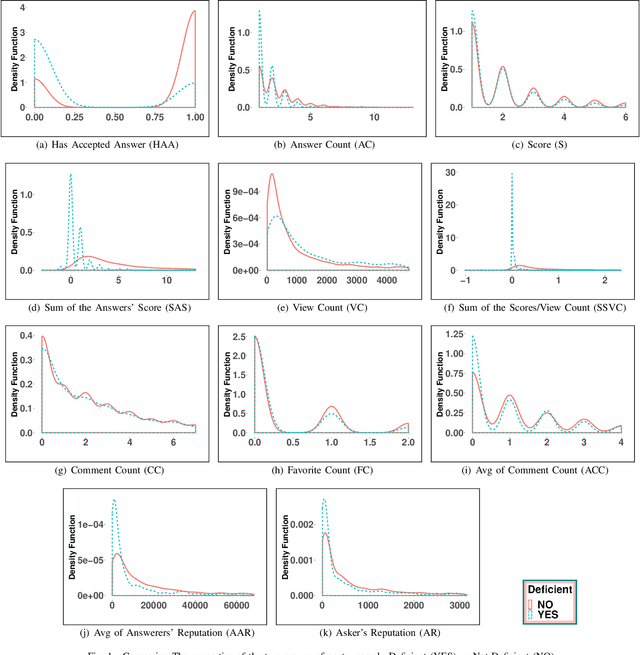
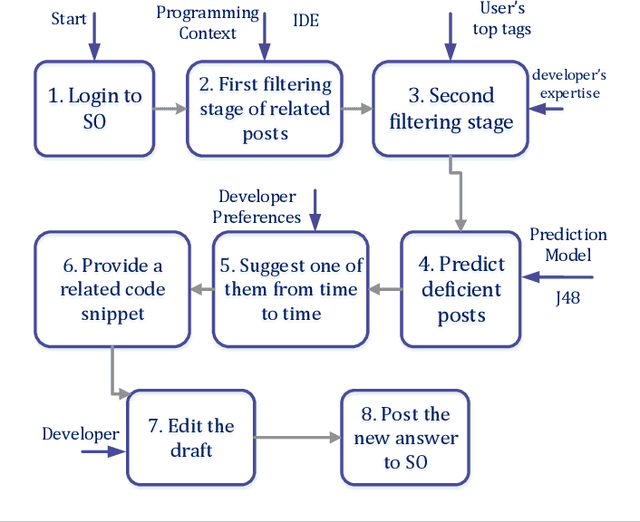

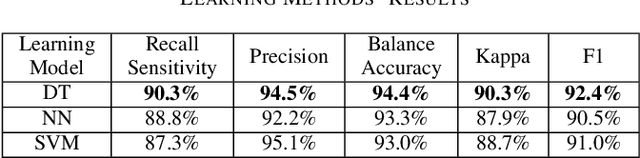
Community Question Answering platforms such as Stack Overflow help a wide range of users solve their challenges online. As the popularity of these communities has grown over the years, both the number of members and posts have escalated. Also, due to the diverse backgrounds, skills, expertise, and viewpoints of users, each question may obtain more than one answers. Therefore, the focus has changed toward producing posts that have a set of answers more valuable for the community as a whole, not just one accepted-answer aimed at satisfying only the question-asker. Same as every universal community, a large number of low-quality posts on Stack Overflow require improvement. We call these posts deficient and define them as posts with questions that either have no answer yet or can be improved by other ones. In this paper, we propose an approach to automate the identification process of such posts and boost their set of answers, utilizing the help of related experts. With the help of 60 participants, we trained a classification model to identify deficient posts by investigating the relationship between characteristics of 3075 questions posted on Stack Overflow and their need for better answers set. Then, we developed an Eclipse plugin named SOPI and integrated the prediction model in the plugin to link these deficient posts to related developers and help them improve the answer set. We evaluated both the functionality of our plugin and the impact of answers submitted to Stack Overflow with the help of 10 and 15 expert industrial developers, respectively. Our results indicate that decision trees, specifically J48, predicts a deficient question better than the other methods with 0.945 precision and 0.903 recall. We conclude that not only our plugin helps programmers contribute more easily to Stack Overflow, but also it improves the quality of answers.