 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Understandability of Computational Notebooks through Code Metrics Analysis
Paper and Code
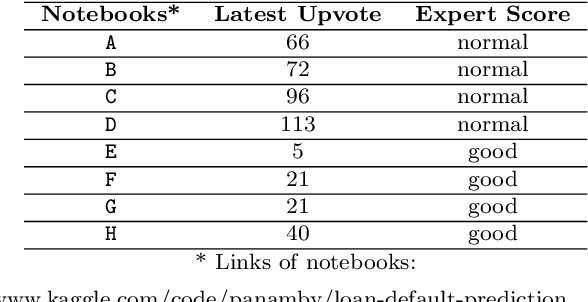
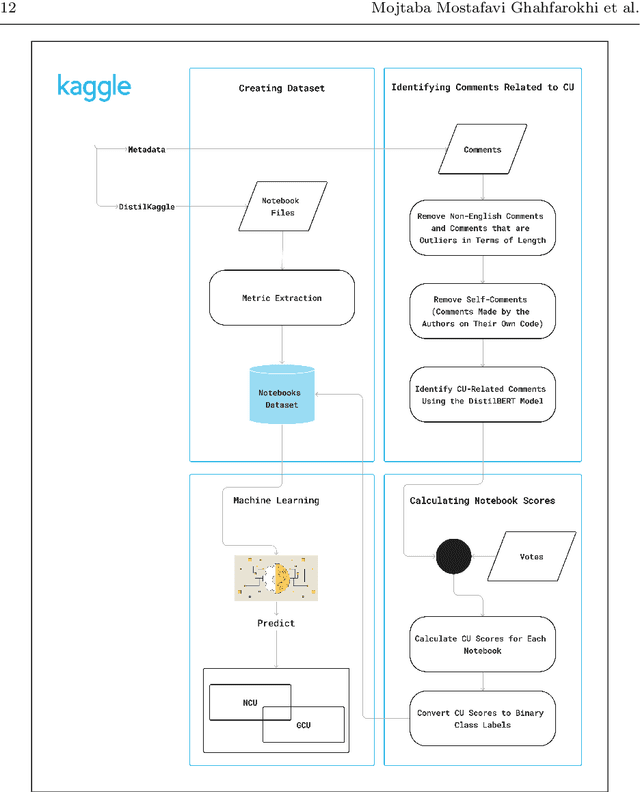
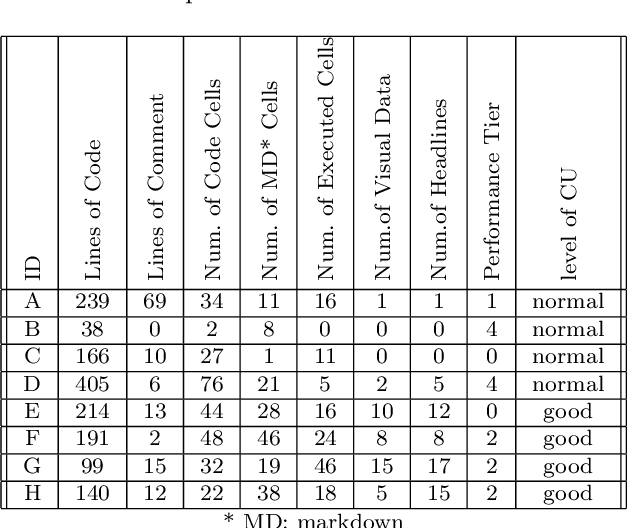
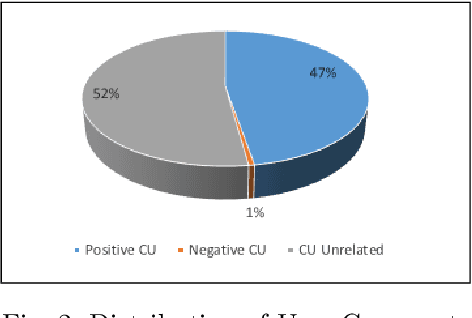
Computational notebooks have become the primary coding environment for data scientists. However, research on their code quality is still emerging, and the code shared is often of poor quality. Given the importance of maintenance and reusability, understanding the metrics that affect notebook code comprehensibility is crucial. Code understandability, a qualitative variable, is closely tied to user opinions. Traditional approaches to measuring it either use limited questionnaires to review a few code pieces or rely on metadata such as likes and votes in software repositories. Our approach enhances the measurement of Jupyter notebook understandability by leveraging user comments related to code understandability. As a case study, we used 542,051 Kaggle Jupyter notebooks from our previous research, named DistilKaggle. We employed a fine-tuned DistilBERT transformer to identify user comments associated with code understandability. We established a criterion called User Opinion Code Understandability (UOCU), which considers the number of relevant comments, upvotes on those comments, total notebook views, and total notebook upvotes. UOCU proved to be more effective than previous methods. Furthermore, we trained machine learning models to predict notebook code understandability based solely on their metrics. We collected 34 metrics for 132,723 final notebooks as features in our dataset, using UOCU as the label. Our predictive model, using the Random Forest classifier, achieved 89% accuracy in predicting the understandability levels of computational notebooks.