 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Attention Pattern Discovery at Scale in Large Language Models
Apr 04, 2026Large language models have found success by scaling up capabilities to work in general settings. The same can unfortunately not be said for interpretability methods. The current trend in mechanistic interpretability is to provide precise explanations of specific behaviors in controlled settings. These often do not generalize, or are too resource intensive for larger studies. In this work we propose to study repeated behaviors in large language models by mining completion scenarios in Java code datasets, through exploiting the structured nature of code. We collect the attention patterns generated in the attention heads to demonstrate that they are scalable signals for global interpretability of model components. We show that vision models offer a promising direction for analyzing attention patterns at scale. To demonstrate this, we introduce the Attention Pattern - Masked Autoencoder(AP-MAE), a vision transformer-based model that efficiently reconstructs masked attention patterns. Experiments on StarCoder2 show that AP-MAE (i) reconstructs masked attention patterns with high accuracy, (ii) generalizes across unseen models with minimal degradation, (iii) reveals recurring patterns across inferences, (iv) predicts whether a generation will be correct without access to ground truth, with accuracies ranging from 55% to 70% depending on the task, and (v) enables targeted interventions that increase accuracy by 13.6% when applied selectively, but cause collapse when applied excessively. These results establish attention patterns as a scalable signal for interpretability and demonstrate that AP-MAE provides a transferable foundation for both analysis and intervention in large language models. Beyond its standalone value, AP-MAE also serves as a selection procedure to guide fine-grained mechanistic approaches. We release code and models to support future work in large-scale interpretability.
* Accepted to TMLR
Investigating Autonomous Agent Contributions in the Wild: Activity Patterns and Code Change over Time
Apr 01, 2026The rise of large language models for code has reshaped software development. Autonomous coding agents, able to create branches, open pull requests, and perform code reviews, now actively contribute to real-world projects. Their growing role offers a unique and timely opportunity to investigate AI-driven contributions and their effects on code quality, team dynamics, and software maintainability. In this work, we construct a novel dataset of approximately $110,000$ open-source pull requests, including associated commits, comments, reviews, issues, and file changes, collectively representing millions of lines of source code. We compare five popular coding agents, including OpenAI Codex, Claude Code, GitHub Copilot, Google Jules, and Devin, examining how their usage differs in various development aspects such as merge frequency, edited file types, and developer interaction signals, including comments and reviews. Furthermore, we emphasize that code authoring and review are only a small part of the larger software engineering process, as the resulting code must also be maintained and updated over time. Hence, we offer several longitudinal estimates of survival and churn rates for agent-generated versus human-authored code. Ultimately, our findings indicate an increasing agent activity in open-source projects, although their contributions are associated with more churn over time compared to human-authored code.
TriCEGAR: A Trace-Driven Abstraction Mechanism for Agentic AI
Jan 30, 2026Agentic AI systems act through tools and evolve their behavior over long, stochastic interaction traces. This setting complicates assurance, because behavior depends on nondeterministic environments and probabilistic model outputs. Prior work introduced runtime verification for agentic AI via Dynamic Probabilistic Assurance (DPA), learning an MDP online and model checking quantitative properties. A key limitation is that developers must manually define the state abstraction, which couples verification to application-specific heuristics and increases adoption friction. This paper proposes TriCEGAR, a trace-driven abstraction mechanism that automates state construction from execution logs and supports online construction of an agent behavioral MDP. TriCEGAR represents abstractions as predicate trees learned from traces and refined using counterexamples. We describe a framework-native implementation that (i) captures typed agent lifecycle events, (ii) builds abstractions from traces, (iii) constructs an MDP, and (iv) performs probabilistic model checking to compute bounds such as Pmax(success) and Pmin(failure). We also show how run likelihoods enable anomaly detection as a guardrailing signal.
Model See, Model Do? Exposure-Aware Evaluation of Bug-vs-Fix Preference in Code LLMs
Jan 15, 2026Large language models are increasingly used for code generation and debugging, but their outputs can still contain bugs, that originate from training data. Distinguishing whether an LLM prefers correct code, or a familiar incorrect version might be influenced by what it's been exposed to during training. We introduce an exposure-aware evaluation framework that quantifies how prior exposure to buggy versus fixed code influences a model's preference. Using the ManySStuBs4J benchmark, we apply Data Portraits for membership testing on the Stack-V2 corpus to estimate whether each buggy and fixed variant was seen during training. We then stratify examples by exposure and compare model preference using code completion as well as multiple likelihood-based scoring metrics We find that most examples (67%) have neither variant in the training data, and when only one is present, fixes are more frequently present than bugs. In model generations, models reproduce buggy lines far more often than fixes, with bug-exposed examples amplifying this tendency and fix-exposed examples showing only marginal improvement. In likelihood scoring, minimum and maximum token-probability metrics consistently prefer the fixed code across all conditions, indicating a stable bias toward correct fixes. In contrast, metrics like the Gini coefficient reverse preference when only the buggy variant was seen. Our results indicate that exposure can skew bug-fix evaluations and highlight the risk that LLMs may propagate memorised errors in practice.
Does In-IDE Calibration of Large Language Models work at Scale?
Oct 26, 2025



The introduction of large language models into integrated development environments (IDEs) is revolutionizing software engineering, yet it poses challenges to the usefulness and reliability of Artificial Intelligence-generated code. Post-hoc calibration of internal model confidences aims to align probabilities with an acceptability measure. Prior work suggests calibration can improve alignment, but at-scale evidence is limited. In this work, we investigate the feasibility of applying calibration of code models to an in-IDE context. We study two aspects of the problem: (1) the technical method for implementing confidence calibration and improving the reliability of code generation models, and (2) the human-centered design principles for effectively communicating reliability signal to developers. First, we develop a scalable and flexible calibration framework which can be used to obtain calibration weights for open-source models using any dataset, and evaluate whether calibrators improve the alignment between model confidence and developer acceptance behavior. Through a large-scale analysis of over 24 million real-world developer interactions across multiple programming languages, we find that a general, post-hoc calibration model based on Platt-scaling does not, on average, improve the reliability of model confidence signals. We also find that while dynamically personalizing calibration to individual users can be effective, its effectiveness is highly dependent on the volume of user interaction data. Second, we conduct a multi-phase design study with 3 expert designers and 153 professional developers, combining scenario-based design, semi-structured interviews, and survey validation, revealing a clear preference for presenting reliability signals via non-numerical, color-coded indicators within the in-editor code generation workflow.
A Qualitative Investigation into LLM-Generated Multilingual Code Comments and Automatic Evaluation Metrics
May 21, 2025Large Language Models are essential coding assistants, yet their training is predominantly English-centric. In this study, we evaluate the performance of code language models in non-English contexts, identifying challenges in their adoption and integration into multilingual workflows. We conduct an open-coding study to analyze errors in code comments generated by five state-of-the-art code models, CodeGemma, CodeLlama, CodeQwen1.5, GraniteCode, and StarCoder2 across five natural languages: Chinese, Dutch, English, Greek, and Polish. Our study yields a dataset of 12,500 labeled generations, which we publicly release. We then assess the reliability of standard metrics in capturing comment \textit{correctness} across languages and evaluate their trustworthiness as judgment criteria. Through our open-coding investigation, we identified a taxonomy of 26 distinct error categories in model-generated code comments. They highlight variations in language cohesion, informativeness, and syntax adherence across different natural languages. Our analysis shows that, while these models frequently produce partially correct comments, modern neural metrics fail to reliably differentiate meaningful completions from random noise. Notably, the significant score overlap between expert-rated correct and incorrect comments calls into question the effectiveness of these metrics in assessing generated comments.
Code Red! On the Harmfulness of Applying Off-the-shelf Large Language Models to Programming Tasks
Apr 02, 2025



Nowadays, developers increasingly rely on solutions powered by Large Language Models (LLM) to assist them with their coding tasks. This makes it crucial to align these tools with human values to prevent malicious misuse. In this paper, we propose a comprehensive framework for assessing the potential harmfulness of LLMs within the software engineering domain. We begin by developing a taxonomy of potentially harmful software engineering scenarios and subsequently, create a dataset of prompts based on this taxonomy. To systematically assess the responses, we design and validate an automatic evaluator that classifies the outputs of a variety of LLMs both open-source and closed-source models, as well as general-purpose and code-specific LLMs. Furthermore, we investigate the impact of models size, architecture family, and alignment strategies on their tendency to generate harmful content. The results show significant disparities in the alignment of various LLMs for harmlessness. We find that some models and model families, such as Openhermes, are more harmful than others and that code-specific models do not perform better than their general-purpose counterparts. Notably, some fine-tuned models perform significantly worse than their base-models due to their design choices. On the other side, we find that larger models tend to be more helpful and are less likely to respond with harmful information. These results highlight the importance of targeted alignment strategies tailored to the unique challenges of software engineering tasks and provide a foundation for future work in this critical area.
Human-AI Experience in Integrated Development Environments: A Systematic Literature Review
Mar 08, 2025The integration of Artificial Intelligence (AI) into Integrated Development Environments (IDEs) is reshaping software development, fundamentally altering how developers interact with their tools. This shift marks the emergence of Human-AI Experience in Integrated Development Environment (in-IDE HAX), a field that explores the evolving dynamics of Human-Computer Interaction in AI-assisted coding environments. Despite rapid adoption, research on in-IDE HAX remains fragmented which highlights the need for a unified overview of current practices, challenges, and opportunities. To provide a structured overview of existing research, we conduct a systematic literature review of 89 studies, summarizing current findings and outlining areas for further investigation. Our findings reveal that AI-assisted coding enhances developer productivity but also introduces challenges, such as verification overhead, automation bias, and over-reliance, particularly among novice developers. Furthermore, concerns about code correctness, security, and maintainability highlight the urgent need for explainability, verification mechanisms, and adaptive user control. Although recent advances have driven the field forward, significant research gaps remain, including a lack of longitudinal studies, personalization strategies, and AI governance frameworks. This review provides a foundation for advancing in-IDE HAX research and offers guidance for responsibly integrating AI into software development.
Benchmarking AI Models in Software Engineering: A Review, Search Tool, and Enhancement Protocol
Mar 07, 2025
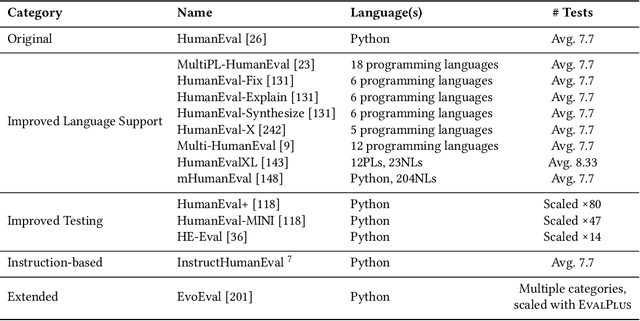

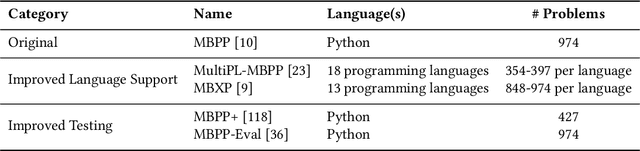
Benchmarks are essential for consistent evaluation and reproducibility. The integration of Artificial Intelligence into Software Engineering (AI4SE) has given rise to numerous benchmarks for tasks such as code generation and bug fixing. However, this surge presents challenges: (1) scattered benchmark knowledge across tasks, (2) difficulty in selecting relevant benchmarks, (3) the absence of a uniform standard for benchmark development, and (4) limitations of existing benchmarks. In this paper, we review 173 studies and identify 204 AI4SE benchmarks. We classify these benchmarks, analyze their limitations, and expose gaps in practices. Based on our review, we created BenchScout, a semantic search tool to find relevant benchmarks, using automated clustering of the contexts from associated studies. We conducted a user study with 22 participants to evaluate BenchScout's usability, effectiveness, and intuitiveness which resulted in average scores of 4.5, 4.0, and 4.1 out of 5. To advance benchmarking standards, we propose BenchFrame, a unified method to enhance benchmark quality. As a case study, we applied BenchFrame to the HumanEval benchmark and addressed its main limitations. This led to HumanEvalNext, featuring (1) corrected errors, (2) improved language conversion, (3) expanded test coverage, and (4) increased difficulty. We then evaluated ten state-of-the-art code language models on HumanEval, HumanEvalPlus, and HumanEvalNext. On HumanEvalNext, models showed a pass@1 score reduction of 31.22% and 19.94% compared to HumanEval and HumanEvalPlus, respectively.
The Heap: A Contamination-Free Multilingual Code Dataset for Evaluating Large Language Models
Jan 16, 2025
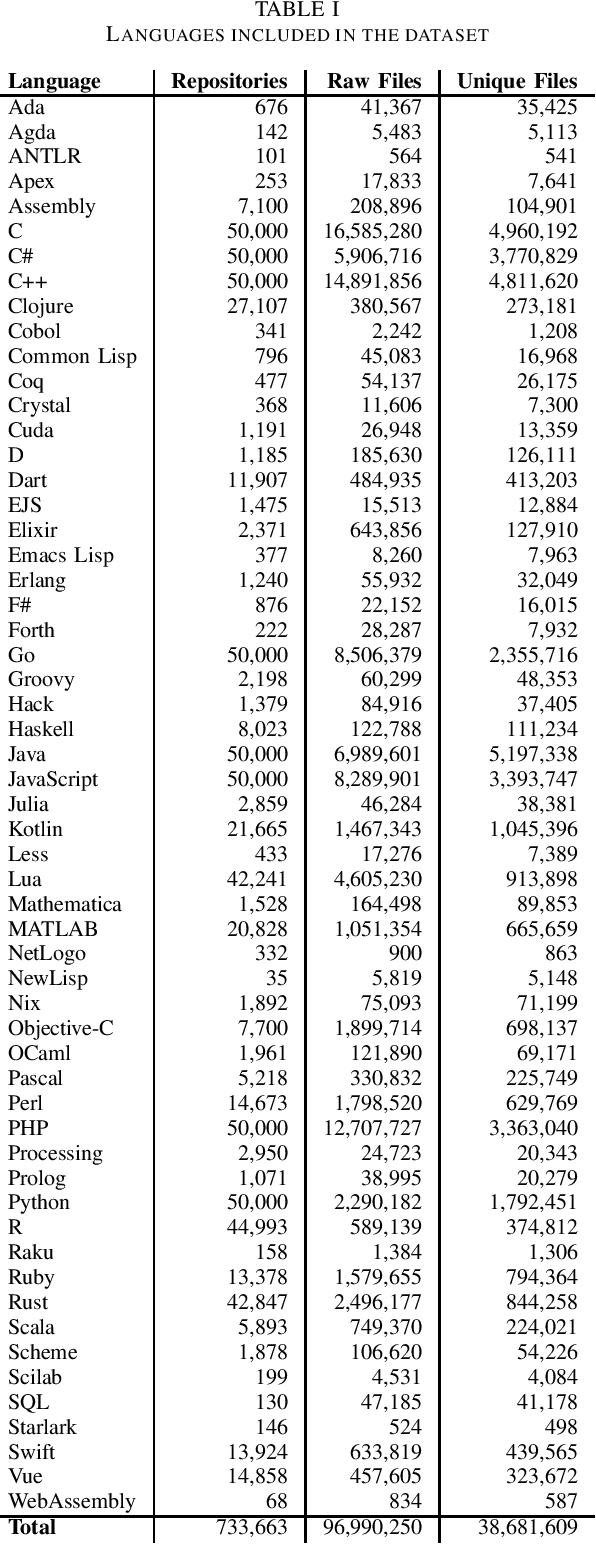
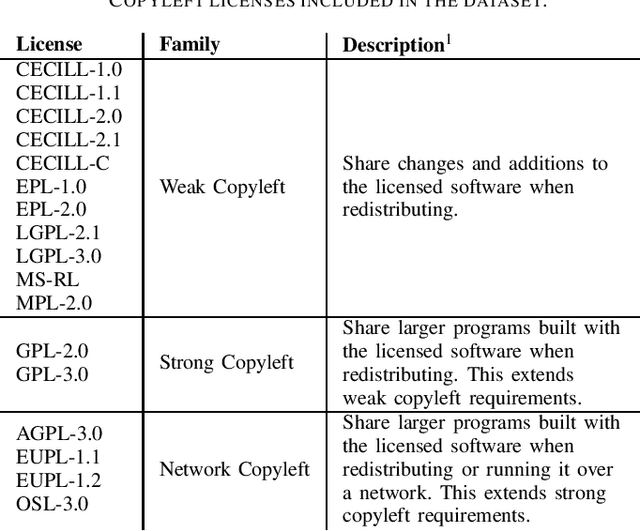

The recent rise in the popularity of large language models has spurred the development of extensive code datasets needed to train them. This has left limited code available for collection and use in the downstream investigation of specific behaviors, or evaluation of large language models without suffering from data contamination. To address this problem, we release The Heap, a large multilingual dataset covering 57 programming languages that has been deduplicated with respect to other open datasets of code, enabling researchers to conduct fair evaluations of large language models without significant data cleaning overhead.