 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking AI Models in Software Engineering: A Review, Search Tool, and Enhancement Protocol
Mar 07, 2025
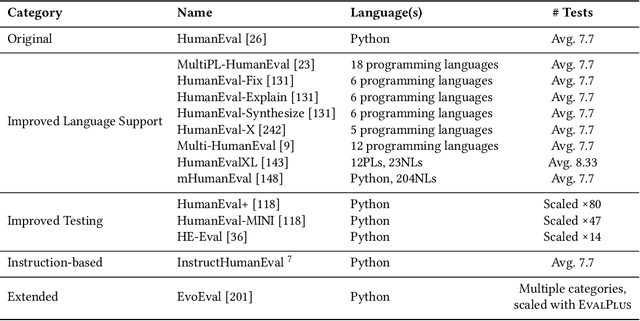

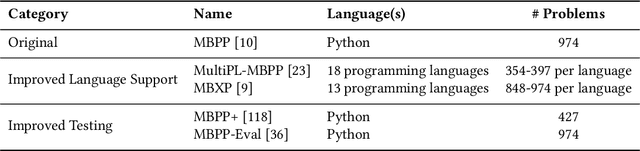
Benchmarks are essential for consistent evaluation and reproducibility. The integration of Artificial Intelligence into Software Engineering (AI4SE) has given rise to numerous benchmarks for tasks such as code generation and bug fixing. However, this surge presents challenges: (1) scattered benchmark knowledge across tasks, (2) difficulty in selecting relevant benchmarks, (3) the absence of a uniform standard for benchmark development, and (4) limitations of existing benchmarks. In this paper, we review 173 studies and identify 204 AI4SE benchmarks. We classify these benchmarks, analyze their limitations, and expose gaps in practices. Based on our review, we created BenchScout, a semantic search tool to find relevant benchmarks, using automated clustering of the contexts from associated studies. We conducted a user study with 22 participants to evaluate BenchScout's usability, effectiveness, and intuitiveness which resulted in average scores of 4.5, 4.0, and 4.1 out of 5. To advance benchmarking standards, we propose BenchFrame, a unified method to enhance benchmark quality. As a case study, we applied BenchFrame to the HumanEval benchmark and addressed its main limitations. This led to HumanEvalNext, featuring (1) corrected errors, (2) improved language conversion, (3) expanded test coverage, and (4) increased difficulty. We then evaluated ten state-of-the-art code language models on HumanEval, HumanEvalPlus, and HumanEvalNext. On HumanEvalNext, models showed a pass@1 score reduction of 31.22% and 19.94% compared to HumanEval and HumanEvalPlus, respectively.
Investigating the Performance of Language Models for Completing Code in Functional Programming Languages: a Haskell Case Study
Mar 22, 2024
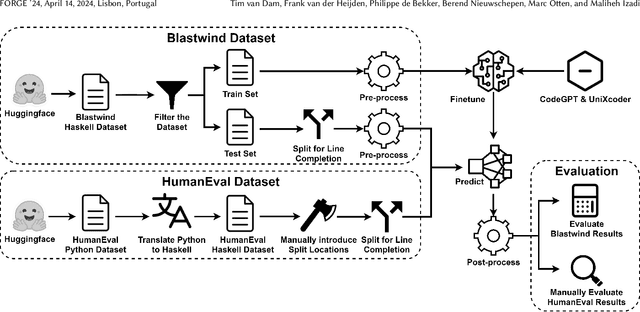

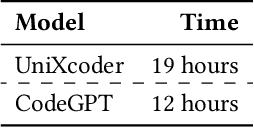
Language model-based code completion models have quickly grown in use, helping thousands of developers write code in many different programming languages. However, research on code completion models typically focuses on imperative languages such as Python and JavaScript, which results in a lack of representation for functional programming languages. Consequently, these models often perform poorly on functional languages such as Haskell. To investigate whether this can be alleviated, we evaluate the performance of two language models for code, CodeGPT and UniXcoder, on the functional programming language Haskell. We fine-tune and evaluate the models on Haskell functions sourced from a publicly accessible Haskell dataset on HuggingFace. Additionally, we manually evaluate the models using our novel translated HumanEval dataset. Our automatic evaluation shows that knowledge of imperative programming languages in the pre-training of LLMs may not transfer well to functional languages, but that code completion on functional languages is feasible. Consequently, this shows the need for more high-quality Haskell datasets. A manual evaluation on HumanEval-Haskell indicates CodeGPT frequently generates empty predictions and extra comments, while UniXcoder more often produces incomplete or incorrect predictions. Finally, we release HumanEval-Haskell, along with the fine-tuned models and all code required to reproduce our experiments on GitHub (https://github.com/AISE-TUDelft/HaskellCCEval).