 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Autonomous Agent Contributions in the Wild: Activity Patterns and Code Change over Time
Apr 01, 2026The rise of large language models for code has reshaped software development. Autonomous coding agents, able to create branches, open pull requests, and perform code reviews, now actively contribute to real-world projects. Their growing role offers a unique and timely opportunity to investigate AI-driven contributions and their effects on code quality, team dynamics, and software maintainability. In this work, we construct a novel dataset of approximately $110,000$ open-source pull requests, including associated commits, comments, reviews, issues, and file changes, collectively representing millions of lines of source code. We compare five popular coding agents, including OpenAI Codex, Claude Code, GitHub Copilot, Google Jules, and Devin, examining how their usage differs in various development aspects such as merge frequency, edited file types, and developer interaction signals, including comments and reviews. Furthermore, we emphasize that code authoring and review are only a small part of the larger software engineering process, as the resulting code must also be maintained and updated over time. Hence, we offer several longitudinal estimates of survival and churn rates for agent-generated versus human-authored code. Ultimately, our findings indicate an increasing agent activity in open-source projects, although their contributions are associated with more churn over time compared to human-authored code.
The Heap: A Contamination-Free Multilingual Code Dataset for Evaluating Large Language Models
Jan 16, 2025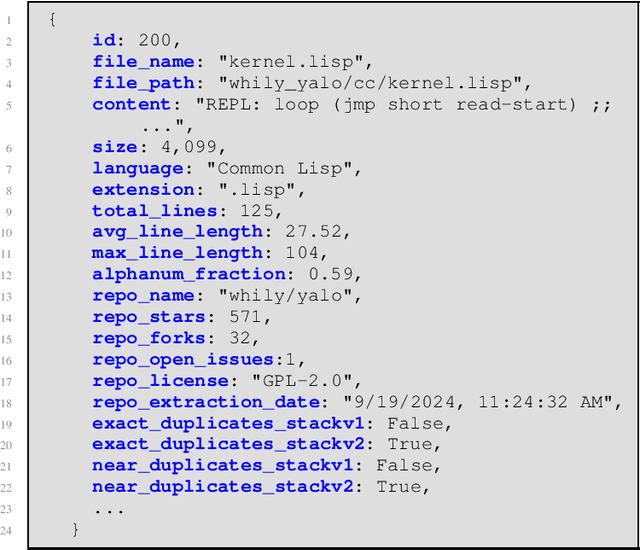
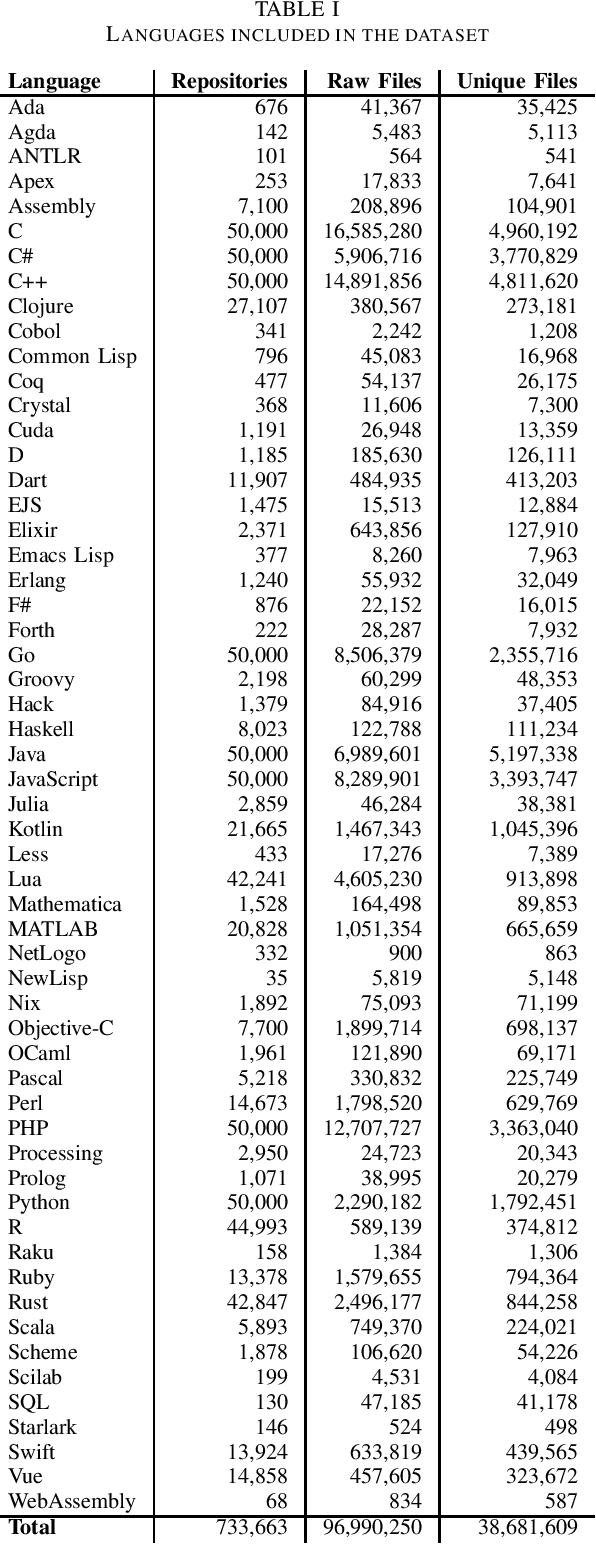
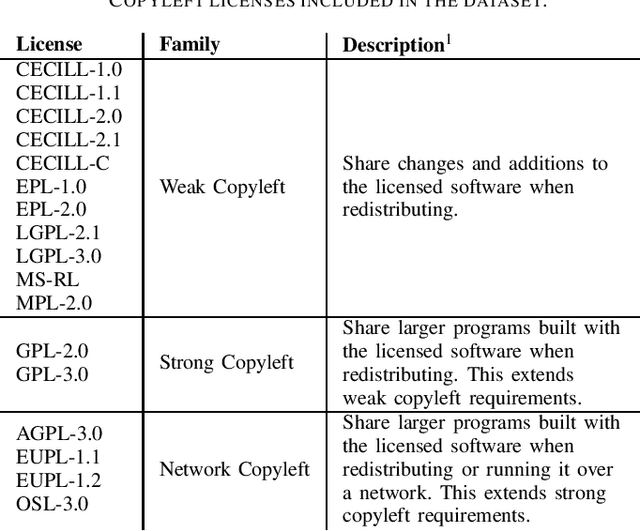

The recent rise in the popularity of large language models has spurred the development of extensive code datasets needed to train them. This has left limited code available for collection and use in the downstream investigation of specific behaviors, or evaluation of large language models without suffering from data contamination. To address this problem, we release The Heap, a large multilingual dataset covering 57 programming languages that has been deduplicated with respect to other open datasets of code, enabling researchers to conduct fair evaluations of large language models without significant data cleaning overhead.
Language Models for Code Completion: A Practical Evaluation
Feb 25, 2024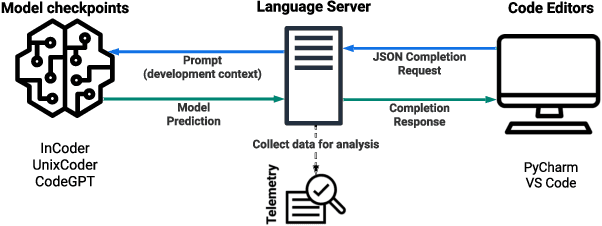
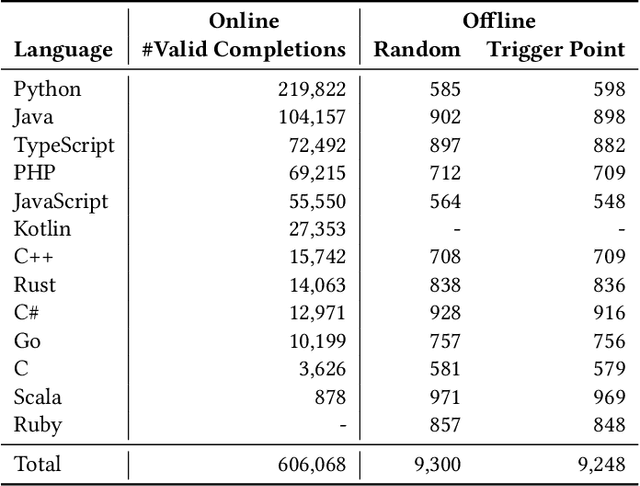

Transformer-based language models for automatic code completion have shown great promise so far, yet the evaluation of these models rarely uses real data. This study provides both quantitative and qualitative assessments of three public code language models when completing real-world code. We first developed an open-source IDE extension, Code4Me, for the online evaluation of the models. We collected real auto-completion usage data for over a year from more than 1200 users, resulting in over 600K valid completions. These models were then evaluated using six standard metrics across twelve programming languages. Next, we conducted a qualitative study of 1690 real-world completion requests to identify the reasons behind the poor model performance. A comparative analysis of the models' performance in online and offline settings was also performed, using benchmark synthetic datasets and two masking strategies. Our findings suggest that while developers utilize code completion across various languages, the best results are achieved for mainstream languages such as Python and Java. InCoder outperformed the other models across all programming languages, highlighting the significance of training data and objectives. Our study also revealed that offline evaluations do not accurately reflect real-world scenarios. Upon qualitative analysis of the model's predictions, we found that 66.3% of failures were due to the models' limitations, 24.4% occurred due to inappropriate model usage in a development context, and 9.3% were valid requests that developers overwrote. Given these findings, we propose several strategies to overcome the current limitations. These include refining training objectives, improving resilience to typographical errors, adopting hybrid approaches, and enhancing implementations and usability.