 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Autonomous Agent Contributions in the Wild: Activity Patterns and Code Change over Time
Apr 01, 2026The rise of large language models for code has reshaped software development. Autonomous coding agents, able to create branches, open pull requests, and perform code reviews, now actively contribute to real-world projects. Their growing role offers a unique and timely opportunity to investigate AI-driven contributions and their effects on code quality, team dynamics, and software maintainability. In this work, we construct a novel dataset of approximately $110,000$ open-source pull requests, including associated commits, comments, reviews, issues, and file changes, collectively representing millions of lines of source code. We compare five popular coding agents, including OpenAI Codex, Claude Code, GitHub Copilot, Google Jules, and Devin, examining how their usage differs in various development aspects such as merge frequency, edited file types, and developer interaction signals, including comments and reviews. Furthermore, we emphasize that code authoring and review are only a small part of the larger software engineering process, as the resulting code must also be maintained and updated over time. Hence, we offer several longitudinal estimates of survival and churn rates for agent-generated versus human-authored code. Ultimately, our findings indicate an increasing agent activity in open-source projects, although their contributions are associated with more churn over time compared to human-authored code.
Model See, Model Do? Exposure-Aware Evaluation of Bug-vs-Fix Preference in Code LLMs
Jan 15, 2026Large language models are increasingly used for code generation and debugging, but their outputs can still contain bugs, that originate from training data. Distinguishing whether an LLM prefers correct code, or a familiar incorrect version might be influenced by what it's been exposed to during training. We introduce an exposure-aware evaluation framework that quantifies how prior exposure to buggy versus fixed code influences a model's preference. Using the ManySStuBs4J benchmark, we apply Data Portraits for membership testing on the Stack-V2 corpus to estimate whether each buggy and fixed variant was seen during training. We then stratify examples by exposure and compare model preference using code completion as well as multiple likelihood-based scoring metrics We find that most examples (67%) have neither variant in the training data, and when only one is present, fixes are more frequently present than bugs. In model generations, models reproduce buggy lines far more often than fixes, with bug-exposed examples amplifying this tendency and fix-exposed examples showing only marginal improvement. In likelihood scoring, minimum and maximum token-probability metrics consistently prefer the fixed code across all conditions, indicating a stable bias toward correct fixes. In contrast, metrics like the Gini coefficient reverse preference when only the buggy variant was seen. Our results indicate that exposure can skew bug-fix evaluations and highlight the risk that LLMs may propagate memorised errors in practice.
Localized Calibrated Uncertainty in Code Language Models
Dec 31, 2025Large Language models (LLMs) can generate complicated source code from natural language prompts. However, LLMs can generate output that deviates from what the user wants, requiring supervision and editing. To support this process, we offer techniques to localize where generations might be misaligned from user intent. We first create a dataset of "Minimal Intent Aligning Patches" of repaired LLM generated programs. Each program uses test cases to verify correctness. After creating a dataset of programs, we measure how well various techniques can assign a well-calibrated probability to indicate which parts of code will be edited in a minimal patch (i.e., give a probability that corresponds with empirical odds it is edited). We compare white-box probing (where we propose a technique for efficient arbitrary-span querying), against black-box reflective and self-consistency based approaches. We find probes with a small supervisor model can achieve low calibration error and Brier Skill Score of approx 0.2 estimating edited lines on code generated by models many orders of magnitude larger. We discuss the generalizability of the techniques, and the connections to AI oversight and control, finding a probe trained only on code shows some signs of generalizing to natural language errors if new probability scaling is allowed.
Do LLMs Trust the Code They Write?
Dec 08, 2025
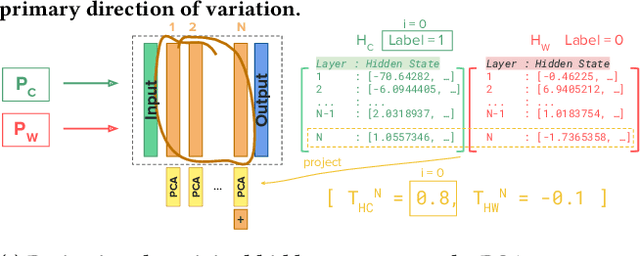
Despite the effectiveness of large language models (LLMs) for code generation, they often output incorrect code. One reason is that model output probabilities are often not well-correlated with correctness, and reflect only the final output of the generation process. Inspired by findings that LLMs internally encode concepts like truthfulness, this paper explores if LLMs similarly represent code correctness. Specifically, we identify a correctness representation inside LLMs by contrasting the hidden states between pairs of correct and incorrect code for the same programming tasks. By experimenting on four LLMs, we show that exploiting this extracted correctness representation outperforms standard log-likelihood ranking, as well as verbalized model confidence. Furthermore, we explore how this internal correctness signal can be used to select higher-quality code samples, without requiring test execution. Ultimately, this work demonstrates how leveraging internal representations can enhance code generation systems and make LLMs more reliable, thus improving confidence in automatically generated code.
Does In-IDE Calibration of Large Language Models work at Scale?
Oct 26, 2025



The introduction of large language models into integrated development environments (IDEs) is revolutionizing software engineering, yet it poses challenges to the usefulness and reliability of Artificial Intelligence-generated code. Post-hoc calibration of internal model confidences aims to align probabilities with an acceptability measure. Prior work suggests calibration can improve alignment, but at-scale evidence is limited. In this work, we investigate the feasibility of applying calibration of code models to an in-IDE context. We study two aspects of the problem: (1) the technical method for implementing confidence calibration and improving the reliability of code generation models, and (2) the human-centered design principles for effectively communicating reliability signal to developers. First, we develop a scalable and flexible calibration framework which can be used to obtain calibration weights for open-source models using any dataset, and evaluate whether calibrators improve the alignment between model confidence and developer acceptance behavior. Through a large-scale analysis of over 24 million real-world developer interactions across multiple programming languages, we find that a general, post-hoc calibration model based on Platt-scaling does not, on average, improve the reliability of model confidence signals. We also find that while dynamically personalizing calibration to individual users can be effective, its effectiveness is highly dependent on the volume of user interaction data. Second, we conduct a multi-phase design study with 3 expert designers and 153 professional developers, combining scenario-based design, semi-structured interviews, and survey validation, revealing a clear preference for presenting reliability signals via non-numerical, color-coded indicators within the in-editor code generation workflow.
Quality and Trust in LLM-generated Code
Feb 09, 2024



Machine learning models are widely used but can also often be wrong. Users would benefit from a reliable indication of whether a given output from a given model should be trusted, so a rational decision can be made whether to use the output or not. For example, outputs can be associated with a confidence measure; if this confidence measure is strongly associated with likelihood of correctness, then the model is said to be well-calibrated. In this case, for example, high-confidence outputs could be safely accepted, and low-confidence outputs rejected. Calibration has so far been studied in non-generative (e.g., classification) settings, especially in Software Engineering. However, generated code can quite often be wrong: Developers need to know when they should e.g., directly use, use after careful review, or discard model-generated code; thus Calibration is vital in generative settings. However, the notion of correctness of generated code is non-trivial, and thus so is Calibration. In this paper we make several contributions. We develop a framework for evaluating the Calibration of code-generating models. We consider several tasks, correctness criteria, datasets, and approaches, and find that by and large generative code models are not well-calibrated out of the box. We then show how Calibration can be improved, using standard methods such as Platt scaling. Our contributions will lead to better-calibrated decision-making in the current use of code generated by language models, and offers a framework for future research to further improve calibration methods for generative models in Software Engineering.
Towards Understanding What Code Language Models Learned
Jun 20, 2023



Pre-trained language models are effective in a variety of natural language tasks, but it has been argued their capabilities fall short of fully learning meaning or understanding language. To understand the extent to which language models can learn some form of meaning, we investigate their ability to capture semantics of code beyond superficial frequency and co-occurrence. In contrast to previous research on probing models for linguistic features, we study pre-trained models in a setting that allows for objective and straightforward evaluation of a model's ability to learn semantics. In this paper, we examine whether such models capture the semantics of code, which is precisely and formally defined. Through experiments involving the manipulation of code fragments, we show that code pre-trained models of code learn a robust representation of the computational semantics of code that goes beyond superficial features of form alone
Code to Comment "Translation": Data, Metrics, Baselining & Evaluation
Oct 03, 2020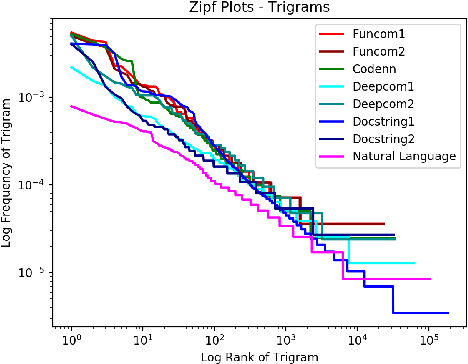
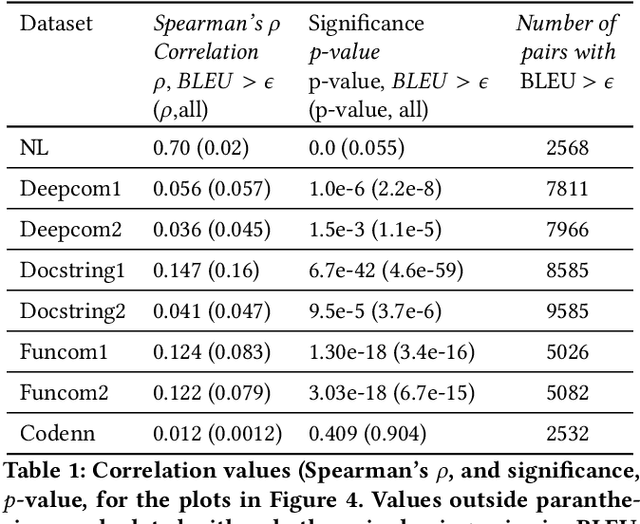
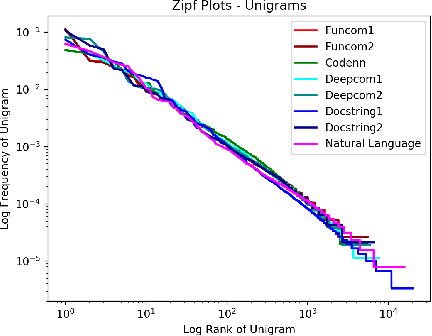
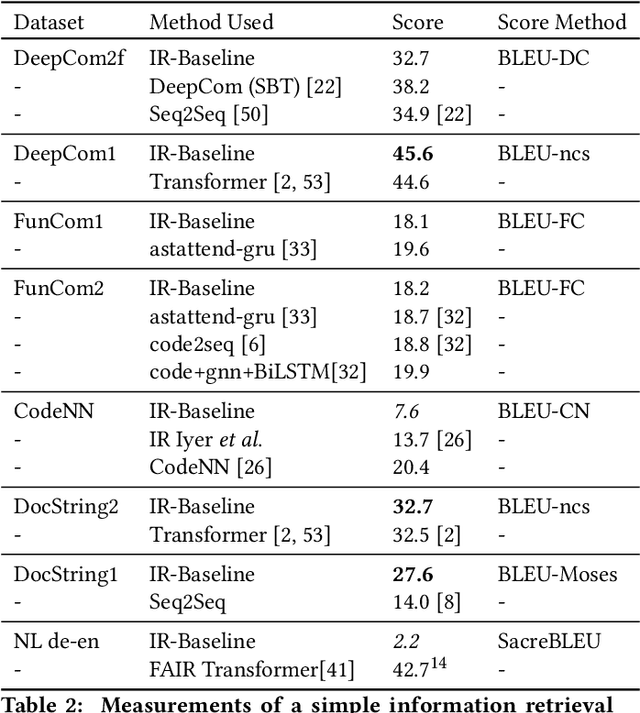
The relationship of comments to code, and in particular, the task of generating useful comments given the code, has long been of interest. The earliest approaches have been based on strong syntactic theories of comment-structures, and relied on textual templates. More recently, researchers have applied deep learning methods to this task, and specifically, trainable generative translation models which are known to work very well for Natural Language translation (e.g., from German to English). We carefully examine the underlying assumption here: that the task of generating comments sufficiently resembles the task of translating between natural languages, and so similar models and evaluation metrics could be used. We analyze several recent code-comment datasets for this task: CodeNN, DeepCom, FunCom, and DocString. We compare them with WMT19, a standard dataset frequently used to train state of the art natural language translators. We found some interesting differences between the code-comment data and the WMT19 natural language data. Next, we describe and conduct some studies to calibrate BLEU (which is commonly used as a measure of comment quality). using "affinity pairs" of methods, from different projects, in the same project, in the same class, etc; Our study suggests that the current performance on some datasets might need to be improved substantially. We also argue that fairly naive information retrieval (IR) methods do well enough at this task to be considered a reasonable baseline. Finally, we make some suggestions on how our findings might be used in future research in this area.
Deep Learning & Software Engineering: State of Research and Future Directions
Sep 17, 2020Given the current transformative potential of research that sits at the intersection of Deep Learning (DL) and Software Engineering (SE), an NSF-sponsored community workshop was conducted in co-location with the 34th IEEE/ACM International Conference on Automated Software Engineering (ASE'19) in San Diego, California. The goal of this workshop was to outline high priority areas for cross-cutting research. While a multitude of exciting directions for future work were identified, this report provides a general summary of the research areas representing the areas of highest priority which were discussed at the workshop. The intent of this report is to serve as a potential roadmap to guide future work that sits at the intersection of SE & DL.
Do People Prefer "Natural" code?
Oct 08, 2019
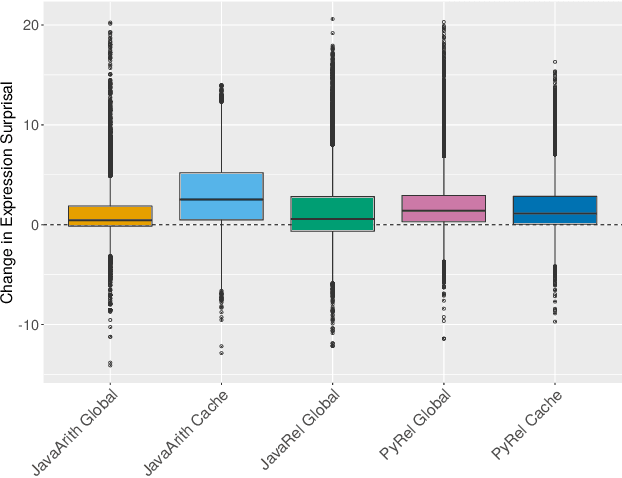
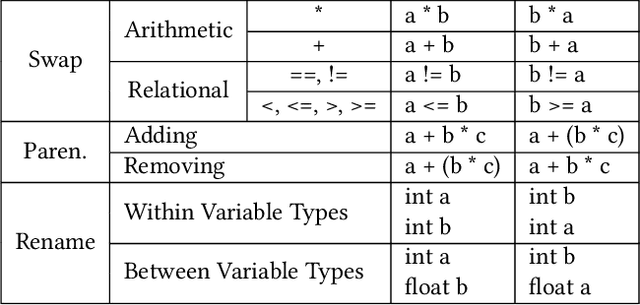
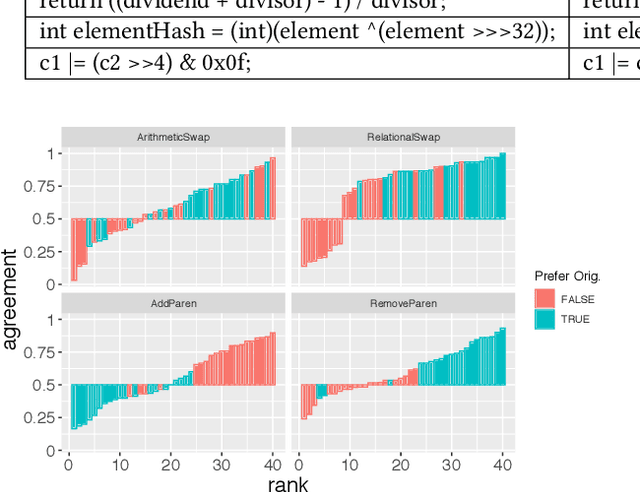
Natural code is known to be very repetitive (much more so than natural language corpora); furthermore, this repetitiveness persists, even after accounting for the simpler syntax of code. However, programming languages are very expressive, allowing a great many different ways (all clear and unambiguous) to express even very simple computations. So why is natural code repetitive? We hypothesize that the reasons for this lie in fact that code is bimodal: it is executed by machines, but also read by humans. This bimodality, we argue, leads developers to write code in certain preferred ways that would be familiar to code readers. To test this theory, we 1) model familiarity using a language model estimated over a large training corpus and 2) run an experiment applying several meaning preserving transformations to Java and Python expressions in a distinct test corpus to see if forms more familiar to readers (as predicted by the language models) are in fact the ones actually written. We find that these transformations generally produce program structures that are less common in practice, supporting the theory that the high repetitiveness in code is a matter of deliberate preference. Finally, 3) we use a human subject study to show alignment between language model score and human preference for the first time in code, providing support for using this measure to improve code.