 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Learning via Random Walk with Jumps
Apr 14, 2026We study decentralized learning over networks where data are distributed across nodes without a central coordinator. Random walk learning is a token-based approach in which a single model is propagated across the network and updated at each visited node using local data, thereby incurring low communication and computational overheads. In weighted random-walk learning, the transition matrix is designed to achieve a desired sampling distribution, thereby speeding up convergence under data heterogeneity. We show that implementing weighted sampling via the Metropolis-Hastings algorithm can lead to a previously unexplored phenomenon we term entrapment. The random walk may become trapped in a small region of the network, resulting in highly correlated updates and severely degraded convergence. To address this issue, we propose Metropolis-Hastings with Levy jumps, which introduces occasional long-range transitions to restore exploration while respecting local information constraints. We establish a convergence rate that explicitly characterizes the roles of data heterogeneity, network spectral gap, and jump probability, and demonstrate through experiments that MHLJ effectively eliminates entrapment and significantly speeds up decentralized learning.
Syntactic Blind Spots: How Misalignment Leads to LLMs Mathematical Errors
Oct 02, 2025Large Language Models (LLMs) demonstrate strong mathematical problem-solving abilities but frequently fail on problems that deviate syntactically from their training distribution. We identify a systematic failure mode, syntactic blind spots, in which models misapply familiar reasoning strategies to problems that are semantically straightforward but phrased in unfamiliar ways. These errors are not due to gaps in mathematical competence, but rather reflect a brittle coupling between surface form and internal representation. To test this, we rephrase incorrectly answered questions using syntactic templates drawn from correct examples. These rephrasings, which preserve semantics while reducing structural complexity, often lead to correct answers. We quantify syntactic complexity using a metric based on Dependency Locality Theory (DLT), and show that higher DLT scores are associated with increased failure rates across multiple datasets. Our findings suggest that many reasoning errors stem from structural misalignment rather than conceptual difficulty, and that syntax-aware interventions can reveal and mitigate these inductive failures.
Optimizing Latent Dimension Allocation in Hierarchical VAEs: Balancing Attenuation and Information Retention for OOD Detection
Jun 11, 2025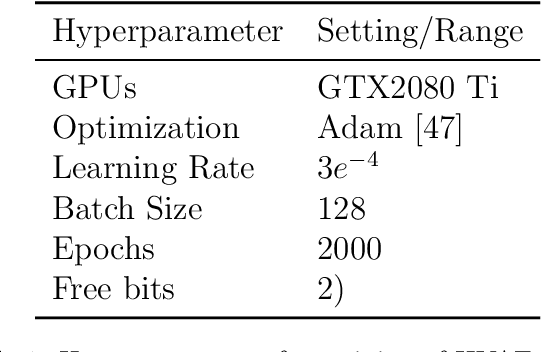
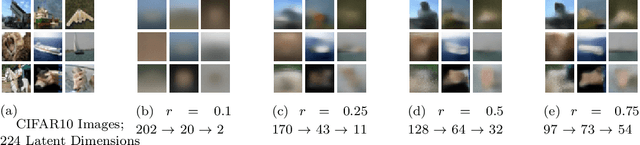
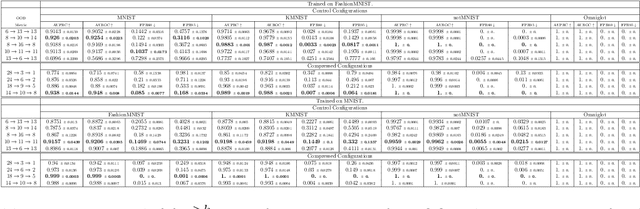
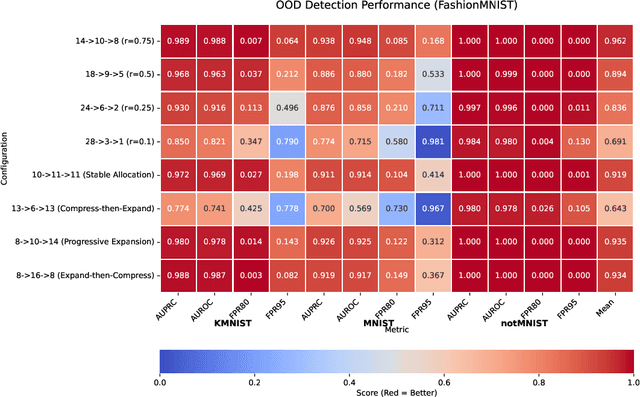
Out-of-distribution (OOD) detection is a critical task in machine learning, particularly for safety-critical applications where unexpected inputs must be reliably flagged. While hierarchical variational autoencoders (HVAEs) offer improved representational capacity over traditional VAEs, their performance is highly sensitive to how latent dimensions are distributed across layers. Existing approaches often allocate latent capacity arbitrarily, leading to ineffective representations or posterior collapse. In this work, we introduce a theoretically grounded framework for optimizing latent dimension allocation in HVAEs, drawing on principles from information theory to formalize the trade-off between information loss and representational attenuation. We prove the existence of an optimal allocation ratio $r^{\ast}$ under a fixed latent budget, and empirically show that tuning this ratio consistently improves OOD detection performance across datasets and architectures. Our approach outperforms baseline HVAE configurations and provides practical guidance for principled latent structure design, leading to more robust OOD detection with deep generative models.
"CASE: Contrastive Activation for Saliency Estimation
Jun 08, 2025

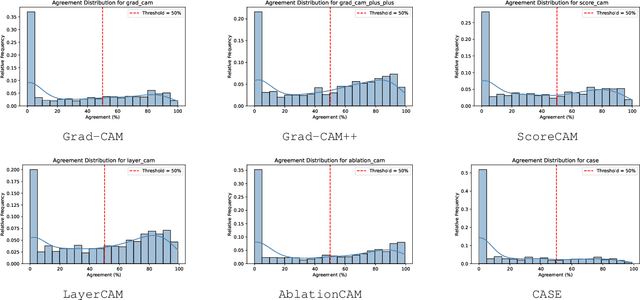
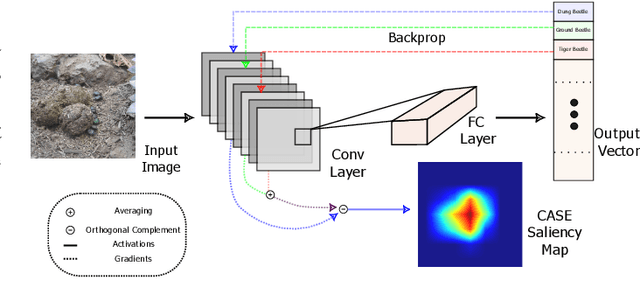
Saliency methods are widely used to visualize which input features are deemed relevant to a model's prediction. However, their visual plausibility can obscure critical limitations. In this work, we propose a diagnostic test for class sensitivity: a method's ability to distinguish between competing class labels on the same input. Through extensive experiments, we show that many widely used saliency methods produce nearly identical explanations regardless of the class label, calling into question their reliability. We find that class-insensitive behavior persists across architectures and datasets, suggesting the failure mode is structural rather than model-specific. Motivated by these findings, we introduce CASE, a contrastive explanation method that isolates features uniquely discriminative for the predicted class. We evaluate CASE using the proposed diagnostic and a perturbation-based fidelity test, and show that it produces faithful and more class-specific explanations than existing methods.
The Entrapment Problem in Random Walk Decentralized Learning
Jul 30, 2024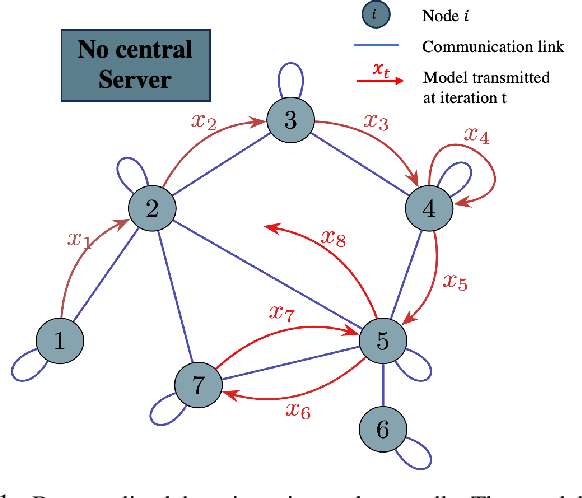
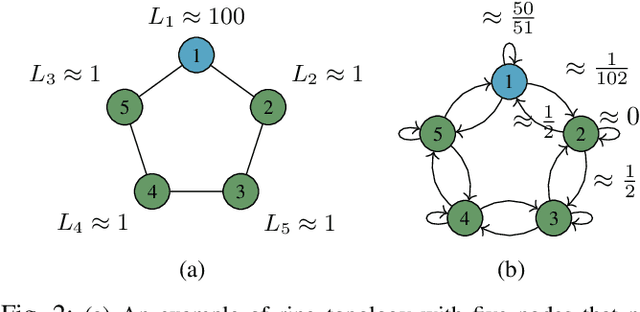
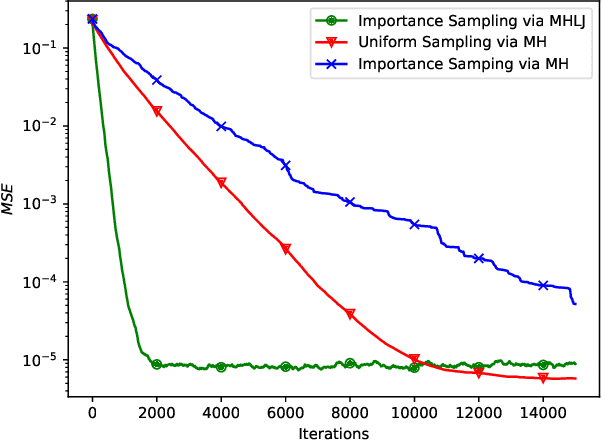
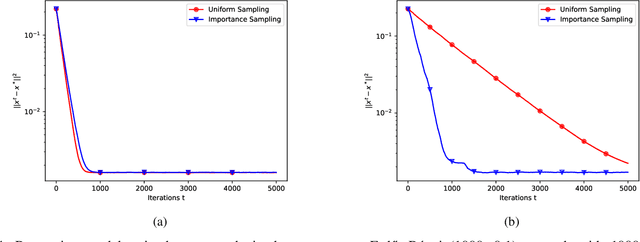
This paper explores decentralized learning in a graph-based setting, where data is distributed across nodes. We investigate a decentralized SGD algorithm that utilizes a random walk to update a global model based on local data. Our focus is on designing the transition probability matrix to speed up convergence. While importance sampling can enhance centralized learning, its decentralized counterpart, using the Metropolis-Hastings (MH) algorithm, can lead to the entrapment problem, where the random walk becomes stuck at certain nodes, slowing convergence. To address this, we propose the Metropolis-Hastings with L\'evy Jumps (MHLJ) algorithm, which incorporates random perturbations (jumps) to overcome entrapment. We theoretically establish the convergence rate and error gap of MHLJ and validate our findings through numerical experiments.
A DPLL Framework for Verifying Deep Neural Networks
Jul 17, 2023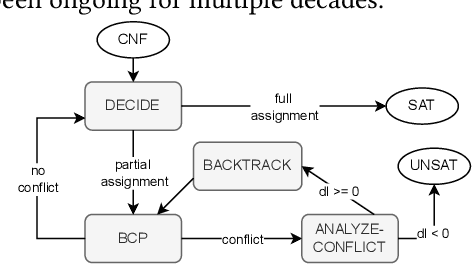
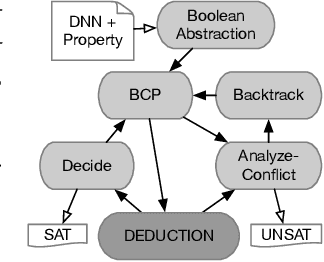

Deep Neural Networks (DNNs) have emerged as an effective approach to tackling real-world problems. However, like human-written software, automatically-generated DNNs can have bugs and be attacked. This thus attracts many recent interests in developing effective and scalable DNN verification techniques and tools. In this work, we introduce a NeuralSAT, a new constraint solving approach to DNN verification. The design of NeuralSAT follows the DPLL(T) algorithm used modern SMT solving, which includes (conflict) clause learning, abstraction, and theory solving, and thus NeuralSAT can be considered as an SMT framework for DNNs. Preliminary results show that the NeuralSAT prototype is competitive to the state-of-the-art. We hope, with proper optimization and engineering, NeuralSAT will carry the power and success of modern SAT/SMT solvers to DNN verification. NeuralSAT is avaliable from: https://github.com/dynaroars/neuralsat-solver
Deep Learning & Software Engineering: State of Research and Future Directions
Sep 17, 2020Given the current transformative potential of research that sits at the intersection of Deep Learning (DL) and Software Engineering (SE), an NSF-sponsored community workshop was conducted in co-location with the 34th IEEE/ACM International Conference on Automated Software Engineering (ASE'19) in San Diego, California. The goal of this workshop was to outline high priority areas for cross-cutting research. While a multitude of exciting directions for future work were identified, this report provides a general summary of the research areas representing the areas of highest priority which were discussed at the workshop. The intent of this report is to serve as a potential roadmap to guide future work that sits at the intersection of SE & DL.
Formal Language Constraints for Markov Decision Processes
Oct 02, 2019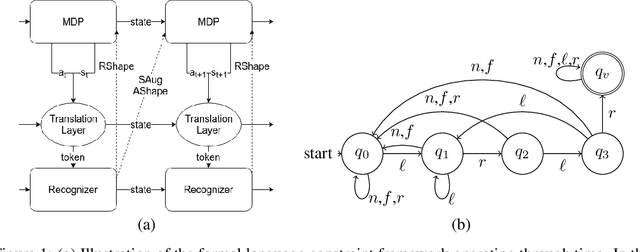
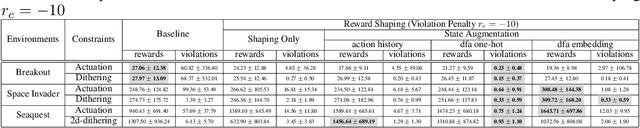
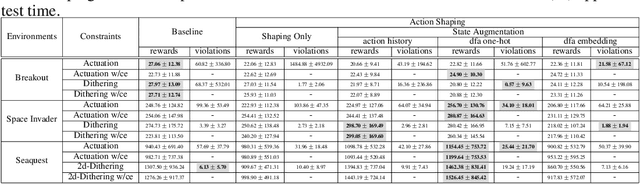

In order to satisfy safety conditions, a reinforcement learned (RL) agent maybe constrained from acting freely, e.g., to prevent trajectories that might cause unwanted behavior or physical damage in a robot. We propose a general framework for augmenting a Markov decision process (MDP) with constraints that are described in formal languages over sequences of MDP states and agent actions. Constraint enforcement is implemented by filtering the allowed action set or by applying potential-based reward shaping to implement hard and soft constraint enforcement, respectively. We instantiate this framework using deterministic finite automata to encode constraints and propose methods of augmenting MDP observations with the state of the constraint automaton for learning. We empirically evaluate these methods with a variety of constraints by training Deep Q-Networks in Atari games as well as Proximal Policy Optimization in MuJoCo environments. We experimentally find that our approaches are effective in significantly reducing or eliminating constraint violations with either minimal negative or, depending on the constraint, a clear positive impact on final performance.