 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Python Translation
Apr 16, 2025Python is one of the most commonly used programming languages in industry and education. Its English keywords and built-in functions/modules allow it to come close to pseudo-code in terms of its readability and ease of writing. However, those who do not speak English may not experience these advantages. In fact, they may even be hindered in their ability to understand Python code, as the English nature of its terms creates an additional layer of overhead. To that end, we introduce the task of automatically translating Python's natural modality (keywords, error types, identifiers, etc.) into other human languages. This presents a unique challenge, considering the abbreviated nature of these forms, as well as potential untranslatability of advanced mathematical/programming concepts across languages. We therefore create an automated pipeline to translate Python into other human languages, comparing strategies using machine translation and large language models. We then use this pipeline to acquire translations from five common Python libraries (pytorch, pandas, tensorflow, numpy, and random) in seven languages, and do a quality test on a subset of these terms in French, Greek, and Bengali. We hope this will provide a clearer path forward towards creating a universal Python, accessible to anyone regardless of nationality or language background.
Combining Language and App UI Analysis for the Automated Assessment of Bug Reproduction Steps
Feb 06, 2025



Bug reports are essential for developers to confirm software problems, investigate their causes, and validate fixes. Unfortunately, reports often miss important information or are written unclearly, which can cause delays, increased issue resolution effort, or even the inability to solve issues. One of the most common components of reports that are problematic is the steps to reproduce the bug(s) (S2Rs), which are essential to replicate the described program failures and reason about fixes. Given the proclivity for deficiencies in reported S2Rs, prior work has proposed techniques that assist reporters in writing or assessing the quality of S2Rs. However, automated understanding of S2Rs is challenging, and requires linking nuanced natural language phrases with specific, semantically related program information. Prior techniques often struggle to form such language to program connections - due to issues in language variability and limitations of information gleaned from program analyses. To more effectively tackle the problem of S2R quality annotation, we propose a new technique called AstroBR, which leverages the language understanding capabilities of LLMs to identify and extract the S2Rs from bug reports and map them to GUI interactions in a program state model derived via dynamic analysis. We compared AstroBR to a related state-of-the-art approach and we found that AstroBR annotates S2Rs 25.2% better (in terms of F1 score) than the baseline. Additionally, AstroBR suggests more accurate missing S2Rs than the baseline (by 71.4% in terms of F1 score).
On Interpreting the Effectiveness of Unsupervised Software Traceability with Information Theory
Dec 06, 2024



Traceability is a cornerstone of modern software development, ensuring system reliability and facilitating software maintenance. While unsupervised techniques leveraging Information Retrieval (IR) and Machine Learning (ML) methods have been widely used for predicting trace links, their effectiveness remains underexplored. In particular, these techniques often assume traceability patterns are present within textual data - a premise that may not hold universally. Moreover, standard evaluation metrics such as precision, recall, accuracy, or F1 measure can misrepresent the model performance when underlying data distributions are not properly analyzed. Given that automated traceability techniques tend to struggle to establish links, we need further insight into the information limits related to traceability artifacts. In this paper, we propose an approach, TraceXplainer, for using information theory metrics to evaluate and better understand the performance (limits) of unsupervised traceability techniques. Specifically, we introduce self-information, cross-entropy, and mutual information (MI) as metrics to measure the informativeness and reliability of traceability links. Through a comprehensive replication and analysis of well-studied datasets and techniques, we investigate the effectiveness of unsupervised techniques that predict traceability links using IR/ML. This application of TraceXplainer illustrates an imbalance in typical traceability datasets where the source code has on average 1.48 more information bits (i.e., entropy) than the linked documentation. Additionally, we demonstrate that an average MI of 4.81 bits, loss of 1.75, and noise of 0.28 bits signify that there are information-theoretic limits on the effectiveness of unsupervised traceability techniques. We hope these findings spur additional research on understanding the limits and progress of traceability research.
Towards More Trustworthy and Interpretable LLMs for Code through Syntax-Grounded Explanations
Jul 12, 2024



Trustworthiness and interpretability are inextricably linked concepts for LLMs. The more interpretable an LLM is, the more trustworthy it becomes. However, current techniques for interpreting LLMs when applied to code-related tasks largely focus on accuracy measurements, measures of how models react to change, or individual task performance instead of the fine-grained explanations needed at prediction time for greater interpretability, and hence trust. To improve upon this status quo, this paper introduces ASTrust, an interpretability method for LLMs of code that generates explanations grounded in the relationship between model confidence and syntactic structures of programming languages. ASTrust explains generated code in the context of syntax categories based on Abstract Syntax Trees and aids practitioners in understanding model predictions at both local (individual code snippets) and global (larger datasets of code) levels. By distributing and assigning model confidence scores to well-known syntactic structures that exist within ASTs, our approach moves beyond prior techniques that perform token-level confidence mapping by offering a view of model confidence that directly aligns with programming language concepts with which developers are familiar. To put ASTrust into practice, we developed an automated visualization that illustrates the aggregated model confidence scores superimposed on sequence, heat-map, and graph-based visuals of syntactic structures from ASTs. We examine both the practical benefit that ASTrust can provide through a data science study on 12 popular LLMs on a curated set of GitHub repos and the usefulness of ASTrust through a human study.
Semantic GUI Scene Learning and Video Alignment for Detecting Duplicate Video-based Bug Reports
Jul 11, 2024Video-based bug reports are increasingly being used to document bugs for programs centered around a graphical user interface (GUI). However, developing automated techniques to manage video-based reports is challenging as it requires identifying and understanding often nuanced visual patterns that capture key information about a reported bug. In this paper, we aim to overcome these challenges by advancing the bug report management task of duplicate detection for video-based reports. To this end, we introduce a new approach, called JANUS, that adapts the scene-learning capabilities of vision transformers to capture subtle visual and textual patterns that manifest on app UI screens - which is key to differentiating between similar screens for accurate duplicate report detection. JANUS also makes use of a video alignment technique capable of adaptive weighting of video frames to account for typical bug manifestation patterns. In a comprehensive evaluation on a benchmark containing 7,290 duplicate detection tasks derived from 270 video-based bug reports from 90 Android app bugs, the best configuration of our approach achieves an overall mRR/mAP of 89.8%/84.7%, and for the large majority of duplicate detection tasks, outperforms prior work by around 9% to a statistically significant degree. Finally, we qualitatively illustrate how the scene-learning capabilities provided by Janus benefits its performance.
AURORA: Navigating UI Tarpits via Automated Neural Screen Understanding
Apr 01, 2024Nearly a decade of research in software engineering has focused on automating mobile app testing to help engineers in overcoming the unique challenges associated with the software platform. Much of this work has come in the form of Automated Input Generation tools (AIG tools) that dynamically explore app screens. However, such tools have repeatedly been demonstrated to achieve lower-than-expected code coverage - particularly on sophisticated proprietary apps. Prior work has illustrated that a primary cause of these coverage deficiencies is related to so-called tarpits, or complex screens that are difficult to navigate. In this paper, we take a critical step toward enabling AIG tools to effectively navigate tarpits during app exploration through a new form of automated semantic screen understanding. We introduce AURORA, a technique that learns from the visual and textual patterns that exist in mobile app UIs to automatically detect common screen designs and navigate them accordingly. The key idea of AURORA is that there are a finite number of mobile app screen designs, albeit with subtle variations, such that the general patterns of different categories of UI designs can be learned. As such, AURORA employs a multi-modal, neural screen classifier that is able to recognize the most common types of UI screen designs. After recognizing a given screen, it then applies a set of flexible and generalizable heuristics to properly navigate the screen. We evaluated AURORA both on a set of 12 apps with known tarpits from prior work, and on a new set of five of the most popular apps from the Google Play store. Our results indicate that AURORA is able to effectively navigate tarpit screens, outperforming prior approaches that avoid tarpits by 19.6% in terms of method coverage. The improvements can be attributed to AURORA's UI design classification and heuristic navigation techniques.
MotorEase: Automated Detection of Motor Impairment Accessibility Issues in Mobile App UIs
Mar 20, 2024
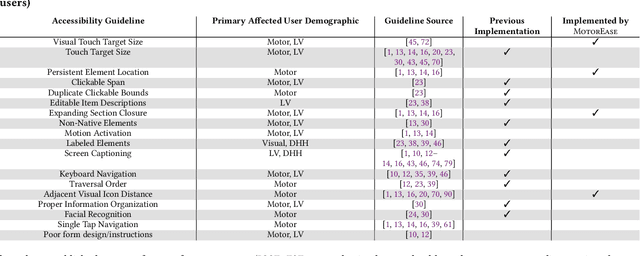

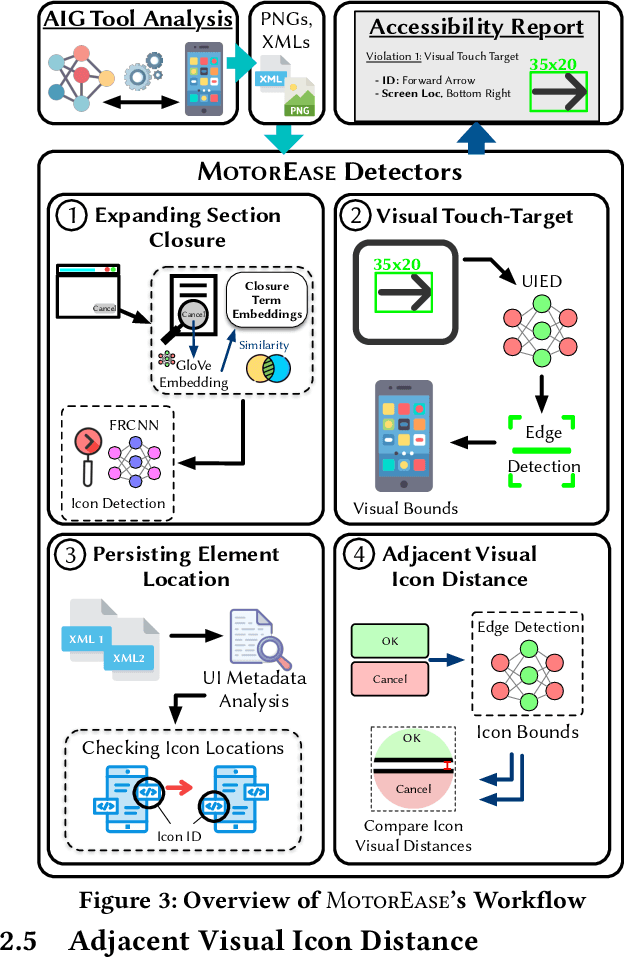
Recent research has begun to examine the potential of automatically finding and fixing accessibility issues that manifest in software. However, while recent work makes important progress, it has generally been skewed toward identifying issues that affect users with certain disabilities, such as those with visual or hearing impairments. However, there are other groups of users with different types of disabilities that also need software tooling support to improve their experience. As such, this paper aims to automatically identify accessibility issues that affect users with motor-impairments. To move toward this goal, this paper introduces a novel approach, called MotorEase, capable of identifying accessibility issues in mobile app UIs that impact motor-impaired users. Motor-impaired users often have limited ability to interact with touch-based devices, and instead may make use of a switch or other assistive mechanism -- hence UIs must be designed to support both limited touch gestures and the use of assistive devices. MotorEase adapts computer vision and text processing techniques to enable a semantic understanding of app UI screens, enabling the detection of violations related to four popular, previously unexplored UI design guidelines that support motor-impaired users, including: (i) visual touch target size, (ii) expanding sections, (iii) persisting elements, and (iv) adjacent icon visual distance. We evaluate MotorEase on a newly derived benchmark, called MotorCheck, that contains 555 manually annotated examples of violations to the above accessibility guidelines, across 1599 screens collected from 70 applications via a mobile app testing tool. Our experiments illustrate that MotorEase is able to identify violations with an average accuracy of ~90%, and a false positive rate of less than 9%, outperforming baseline techniques.
On Using GUI Interaction Data to Improve Text Retrieval-based Bug Localization
Oct 12, 2023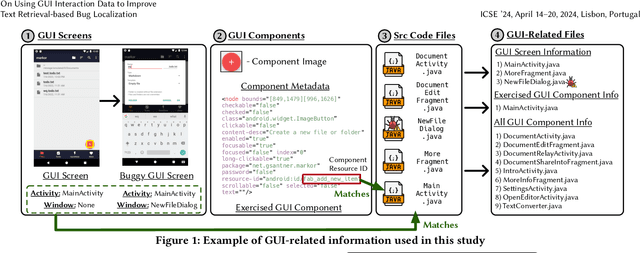



One of the most important tasks related to managing bug reports is localizing the fault so that a fix can be applied. As such, prior work has aimed to automate this task of bug localization by formulating it as an information retrieval problem, where potentially buggy files are retrieved and ranked according to their textual similarity with a given bug report. However, there is often a notable semantic gap between the information contained in bug reports and identifiers or natural language contained within source code files. For user-facing software, there is currently a key source of information that could aid in bug localization, but has not been thoroughly investigated - information from the GUI. We investigate the hypothesis that, for end user-facing applications, connecting information in a bug report with information from the GUI, and using this to aid in retrieving potentially buggy files, can improve upon existing techniques for bug localization. To examine this phenomenon, we conduct a comprehensive empirical study that augments four baseline techniques for bug localization with GUI interaction information from a reproduction scenario to (i) filter out potentially irrelevant files, (ii) boost potentially relevant files, and (iii) reformulate text-retrieval queries. To carry out our study, we source the current largest dataset of fully-localized and reproducible real bugs for Android apps, with corresponding bug reports, consisting of 80 bug reports from 39 popular open-source apps. Our results illustrate that augmenting traditional techniques with GUI information leads to a marked increase in effectiveness across multiple metrics, including a relative increase in Hits@10 of 13-18%. Additionally, through further analysis, we find that our studied augmentations largely complement existing techniques.
A Comparative Study of Transformer-based Neural Text Representation Techniques on Bug Triaging
Oct 10, 2023



Often, the first step in managing bug reports is related to triaging a bug to the appropriate developer who is best suited to understand, localize, and fix the target bug. Additionally, assigning a given bug to a particular part of a software project can help to expedite the fixing process. However, despite the importance of these activities, they are quite challenging, where days can be spent on the manual triaging process. Past studies have attempted to leverage the limited textual data of bug reports to train text classification models that automate this process -- to varying degrees of success. However, the textual representations and machine learning models used in prior work are limited by their expressiveness, often failing to capture nuanced textual patterns that might otherwise aid in the triaging process. Recently, large, transformer-based, pre-trained neural text representation techniques such as BERT have achieved greater performance in several natural language processing tasks. However, the potential for using these techniques to improve upon prior approaches for automated bug triaging is not well studied or understood. Therefore, in this paper we offer one of the first investigations that fine-tunes transformer-based language models for the task of bug triaging on four open source datasets, spanning a collective 53 years of development history with over 400 developers and over 150 software project components. Our study includes both a quantitative and qualitative analysis of effectiveness. Our findings illustrate that DeBERTa is the most effective technique across the triaging tasks of developer and component assignment, and the measured performance delta is statistically significant compared to other techniques. However, through our qualitative analysis, we also observe that each technique possesses unique abilities best suited to certain types of bug reports.
Evaluating and Explaining Large Language Models for Code Using Syntactic Structures
Aug 07, 2023

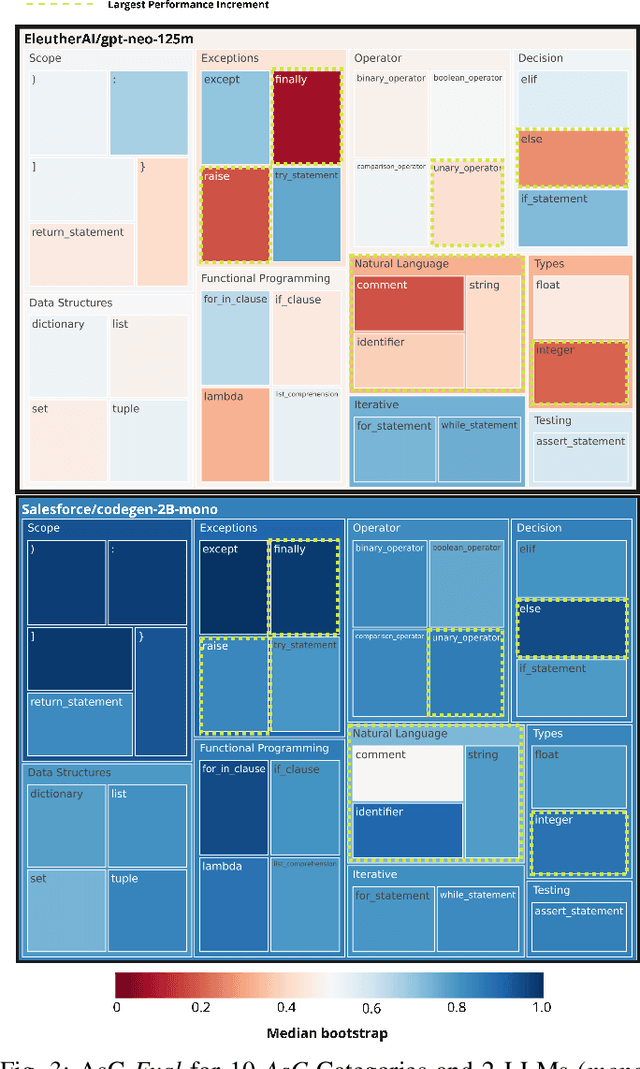

Large Language Models (LLMs) for code are a family of high-parameter, transformer-based neural networks pre-trained on massive datasets of both natural and programming languages. These models are rapidly being employed in commercial AI-based developer tools, such as GitHub CoPilot. However, measuring and explaining their effectiveness on programming tasks is a challenging proposition, given their size and complexity. The methods for evaluating and explaining LLMs for code are inextricably linked. That is, in order to explain a model's predictions, they must be reliably mapped to fine-grained, understandable concepts. Once this mapping is achieved, new methods for detailed model evaluations are possible. However, most current explainability techniques and evaluation benchmarks focus on model robustness or individual task performance, as opposed to interpreting model predictions. To this end, this paper introduces ASTxplainer, an explainability method specific to LLMs for code that enables both new methods for LLM evaluation and visualizations of LLM predictions that aid end-users in understanding model predictions. At its core, ASTxplainer provides an automated method for aligning token predictions with AST nodes, by extracting and aggregating normalized model logits within AST structures. To demonstrate the practical benefit of ASTxplainer, we illustrate the insights that our framework can provide by performing an empirical evaluation on 12 popular LLMs for code using a curated dataset of the most popular GitHub projects. Additionally, we perform a user study examining the usefulness of an ASTxplainer-derived visualization of model predictions aimed at enabling model users to explain predictions. The results of these studies illustrate the potential for ASTxplainer to provide insights into LLM effectiveness, and aid end-users in understanding predictions.