 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Comprehensive Benchmarking Infrastructure for LLMs In Software Engineering
Jan 28, 2026Large language models for code are advancing fast, yet our ability to evaluate them lags behind. Current benchmarks focus on narrow tasks and single metrics, which hide critical gaps in robustness, interpretability, fairness, efficiency, and real-world usability. They also suffer from inconsistent data engineering practices, limited software engineering context, and widespread contamination issues. To understand these problems and chart a path forward, we combined an in-depth survey of existing benchmarks with insights gathered from a dedicated community workshop. We identified three core barriers to reliable evaluation: the absence of software-engineering-rich datasets, overreliance on ML-centric metrics, and the lack of standardized, reproducible data pipelines. Building on these findings, we introduce BEHELM, a holistic benchmarking infrastructure that unifies software-scenario specification with multi-metric evaluation. BEHELM provides a structured way to assess models across tasks, languages, input and output granularities, and key quality dimensions. Our goal is to reduce the overhead currently required to construct benchmarks while enabling a fair, realistic, and future-proof assessment of LLMs in software engineering.
* Short paper from bechmarking for software engineering workshop FSE2025
Detecting and Correcting Hallucinations in LLM-Generated Code via Deterministic AST Analysis
Jan 27, 2026Large Language Models (LLMs) for code generation boost productivity but frequently introduce Knowledge Conflicting Hallucinations (KCHs), subtle, semantic errors, such as non-existent API parameters, that evade linters and cause runtime failures. Existing mitigations like constrained decoding or non-deterministic LLM-in-the-loop repair are often unreliable for these errors. This paper investigates whether a deterministic, static-analysis framework can reliably detect \textit{and} auto-correct KCHs. We propose a post-processing framework that parses generated code into an Abstract Syntax Tree (AST) and validates it against a dynamically-generated Knowledge Base (KB) built via library introspection. This non-executing approach uses deterministic rules to find and fix both API and identifier-level conflicts. On a manually-curated dataset of 200 Python snippets, our framework detected KCHs with 100\% precision and 87.6\% recall (0.934 F1-score), and successfully auto-corrected 77.0\% of all identified hallucinations. Our findings demonstrate that this deterministic post-processing approach is a viable and reliable alternative to probabilistic repair, offering a clear path toward trustworthy code generation.
Tricky$^2$: Towards a Benchmark for Evaluating Human and LLM Error Interactions
Jan 26, 2026Large language models (LLMs) are increasingly integrated into software development workflows, yet they often introduce subtle logic or data-misuse errors that differ from human bugs. To study how these two error types interact, we construct Tricky$^2$, a hybrid dataset that augments the existing TrickyBugs corpus of human-written defects with errors injected by both GPT-5 and OpenAI-oss-20b across C++, Python, and Java programs. Our approach uses a taxonomy-guided prompting framework to generate machine-originated bugs while preserving original human defects and program structure. The resulting corpus spans human-only, LLM-only, and human+LLM splits, enabling analysis of mixed-origin error behavior, multi-bug repair robustness, and reliability in hybrid human-machine code. This paper outlines the dataset construction pipeline and illustrates its use through small-scale baseline evaluations of classification, localization, and repair tasks.
On Explaining (Large) Language Models For Code Using Global Code-Based Explanations
Mar 21, 2025In recent years, Language Models for Code (LLM4Code) have significantly changed the landscape of software engineering (SE) on downstream tasks, such as code generation, by making software development more efficient. Therefore, a growing interest has emerged in further evaluating these Language Models to homogenize the quality assessment of generated code. As the current evaluation process can significantly overreact on accuracy-based metrics, practitioners often seek methods to interpret LLM4Code outputs beyond canonical benchmarks. While the majority of research reports on code generation effectiveness in terms of expected ground truth, scant attention has been paid to LLMs' explanations. In essence, the decision-making process to generate code is hard to interpret. To bridge this evaluation gap, we introduce code rationales (Code$Q$), a technique with rigorous mathematical underpinning, to identify subsets of tokens that can explain individual code predictions. We conducted a thorough Exploratory Analysis to demonstrate the method's applicability and a User Study to understand the usability of code-based explanations. Our evaluation demonstrates that Code$Q$ is a powerful interpretability method to explain how (less) meaningful input concepts (i.e., natural language particle `at') highly impact output generation. Moreover, participants of this study highlighted Code$Q$'s ability to show a causal relationship between the input and output of the model with readable and informative explanations on code completion and test generation tasks. Additionally, Code$Q$ also helps to uncover model rationale, facilitating comparison with a human rationale to promote a fair level of trust and distrust in the model.
SnipGen: A Mining Repository Framework for Evaluating LLMs for Code
Feb 10, 2025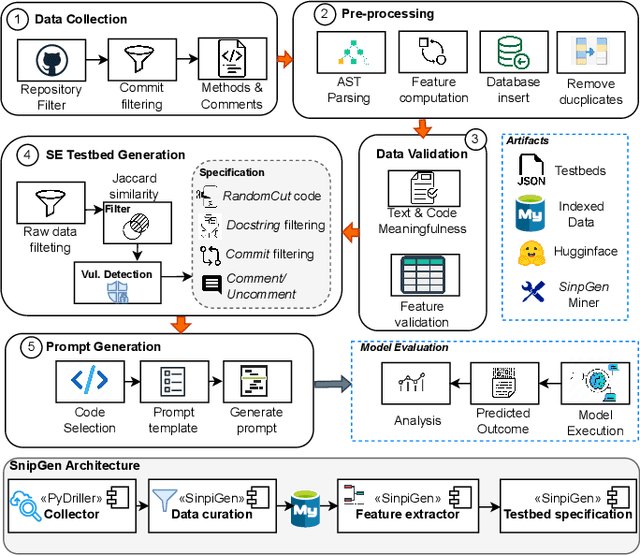
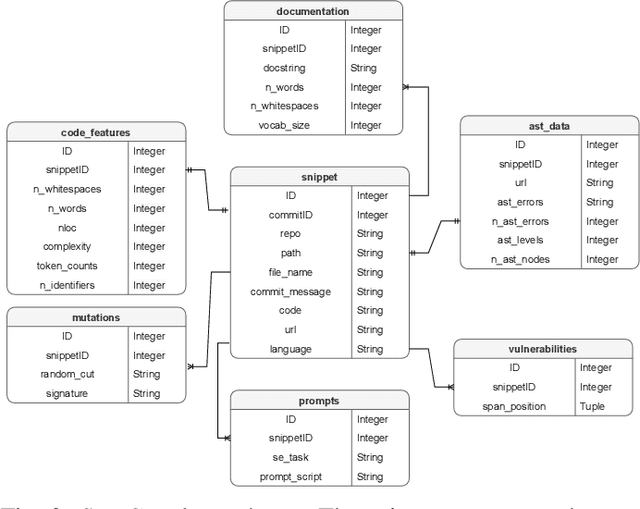


Language Models (LLMs), such as transformer-based neural networks trained on billions of parameters, have become increasingly prevalent in software engineering (SE). These models, trained on extensive datasets that include code repositories, exhibit remarkable capabilities for SE tasks. However, evaluating their effectiveness poses significant challenges, primarily due to the potential overlap between the datasets used for training and those employed for evaluation. To address this issue, we introduce SnipGen, a comprehensive repository mining framework designed to leverage prompt engineering across various downstream tasks for code generation. SnipGen aims to mitigate data contamination by generating robust testbeds and crafting tailored data points to assist researchers and practitioners in evaluating LLMs for code-related tasks. In our exploratory study, SnipGen mined approximately 227K data points from 338K recent code changes in GitHub commits, focusing on method-level granularity. SnipGen features a collection of prompt templates that can be combined to create a Chain-of-Thought-like sequence of prompts, enabling a nuanced assessment of LLMs' code generation quality. By providing the mining tool, the methodology, and the dataset, SnipGen empowers researchers and practitioners to rigorously evaluate and interpret LLMs' performance in software engineering contexts.
How Propense Are Large Language Models at Producing Code Smells? A Benchmarking Study
Dec 25, 2024



Large Language Models (LLMs) have shown significant potential in automating software engineering tasks, particularly in code generation. However, current evaluation benchmarks, which primarily focus on accuracy, fall short in assessing the quality of the code generated by these models, specifically their tendency to produce code smells. To address this limitation, we introduce CodeSmellEval, a benchmark designed to evaluate the propensity of LLMs for generating code smells. Our benchmark includes a novel metric: Propensity Smelly Score (PSC), and a curated dataset of method-level code smells: CodeSmellData. To demonstrate the use of CodeSmellEval, we conducted a case study with two state-of-the-art LLMs, CodeLlama and Mistral. The results reveal that both models tend to generate code smells, such as simplifiable-condition and consider-merging-isinstance. These findings highlight the effectiveness of our benchmark in evaluating LLMs, providing valuable insights into their reliability and their propensity to introduce code smells in code generation tasks.
On Interpreting the Effectiveness of Unsupervised Software Traceability with Information Theory
Dec 06, 2024



Traceability is a cornerstone of modern software development, ensuring system reliability and facilitating software maintenance. While unsupervised techniques leveraging Information Retrieval (IR) and Machine Learning (ML) methods have been widely used for predicting trace links, their effectiveness remains underexplored. In particular, these techniques often assume traceability patterns are present within textual data - a premise that may not hold universally. Moreover, standard evaluation metrics such as precision, recall, accuracy, or F1 measure can misrepresent the model performance when underlying data distributions are not properly analyzed. Given that automated traceability techniques tend to struggle to establish links, we need further insight into the information limits related to traceability artifacts. In this paper, we propose an approach, TraceXplainer, for using information theory metrics to evaluate and better understand the performance (limits) of unsupervised traceability techniques. Specifically, we introduce self-information, cross-entropy, and mutual information (MI) as metrics to measure the informativeness and reliability of traceability links. Through a comprehensive replication and analysis of well-studied datasets and techniques, we investigate the effectiveness of unsupervised techniques that predict traceability links using IR/ML. This application of TraceXplainer illustrates an imbalance in typical traceability datasets where the source code has on average 1.48 more information bits (i.e., entropy) than the linked documentation. Additionally, we demonstrate that an average MI of 4.81 bits, loss of 1.75, and noise of 0.28 bits signify that there are information-theoretic limits on the effectiveness of unsupervised traceability techniques. We hope these findings spur additional research on understanding the limits and progress of traceability research.
Towards More Trustworthy and Interpretable LLMs for Code through Syntax-Grounded Explanations
Jul 12, 2024



Trustworthiness and interpretability are inextricably linked concepts for LLMs. The more interpretable an LLM is, the more trustworthy it becomes. However, current techniques for interpreting LLMs when applied to code-related tasks largely focus on accuracy measurements, measures of how models react to change, or individual task performance instead of the fine-grained explanations needed at prediction time for greater interpretability, and hence trust. To improve upon this status quo, this paper introduces ASTrust, an interpretability method for LLMs of code that generates explanations grounded in the relationship between model confidence and syntactic structures of programming languages. ASTrust explains generated code in the context of syntax categories based on Abstract Syntax Trees and aids practitioners in understanding model predictions at both local (individual code snippets) and global (larger datasets of code) levels. By distributing and assigning model confidence scores to well-known syntactic structures that exist within ASTs, our approach moves beyond prior techniques that perform token-level confidence mapping by offering a view of model confidence that directly aligns with programming language concepts with which developers are familiar. To put ASTrust into practice, we developed an automated visualization that illustrates the aggregated model confidence scores superimposed on sequence, heat-map, and graph-based visuals of syntactic structures from ASTs. We examine both the practical benefit that ASTrust can provide through a data science study on 12 popular LLMs on a curated set of GitHub repos and the usefulness of ASTrust through a human study.
Benchmarking Causal Study to Interpret Large Language Models for Source Code
Aug 23, 2023



One of the most common solutions adopted by software researchers to address code generation is by training Large Language Models (LLMs) on massive amounts of source code. Although a number of studies have shown that LLMs have been effectively evaluated on popular accuracy metrics (e.g., BLEU, CodeBleu), previous research has largely overlooked the role of Causal Inference as a fundamental component of the interpretability of LLMs' performance. Existing benchmarks and datasets are meant to highlight the difference between the expected and the generated outcome, but do not take into account confounding variables (e.g., lines of code, prompt size) that equally influence the accuracy metrics. The fact remains that, when dealing with generative software tasks by LLMs, no benchmark is available to tell researchers how to quantify neither the causal effect of SE-based treatments nor the correlation of confounders to the model's performance. In an effort to bring statistical rigor to the evaluation of LLMs, this paper introduces a benchmarking strategy named Galeras comprised of curated testbeds for three SE tasks (i.e., code completion, code summarization, and commit generation) to help aid the interpretation of LLMs' performance. We illustrate the insights of our benchmarking strategy by conducting a case study on the performance of ChatGPT under distinct prompt engineering methods. The results of the case study demonstrate the positive causal influence of prompt semantics on ChatGPT's generative performance by an average treatment effect of $\approx 3\%$. Moreover, it was found that confounders such as prompt size are highly correlated with accuracy metrics ($\approx 0.412\%$). The end result of our case study is to showcase causal inference evaluations, in practice, to reduce confounding bias. By reducing the bias, we offer an interpretable solution for the accuracy metric under analysis.
Evaluating and Explaining Large Language Models for Code Using Syntactic Structures
Aug 07, 2023

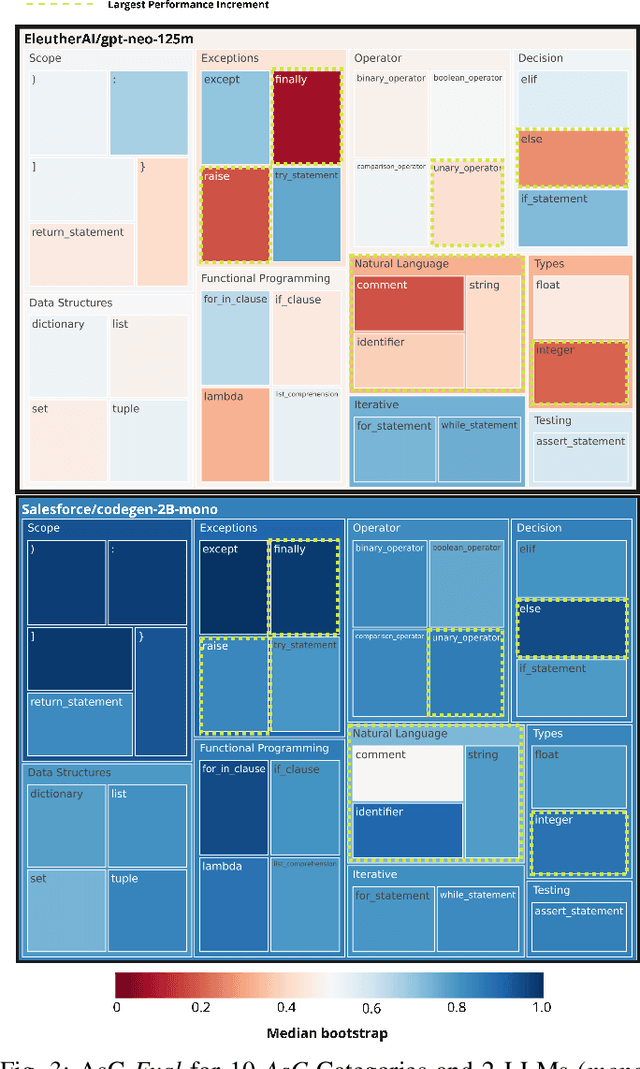

Large Language Models (LLMs) for code are a family of high-parameter, transformer-based neural networks pre-trained on massive datasets of both natural and programming languages. These models are rapidly being employed in commercial AI-based developer tools, such as GitHub CoPilot. However, measuring and explaining their effectiveness on programming tasks is a challenging proposition, given their size and complexity. The methods for evaluating and explaining LLMs for code are inextricably linked. That is, in order to explain a model's predictions, they must be reliably mapped to fine-grained, understandable concepts. Once this mapping is achieved, new methods for detailed model evaluations are possible. However, most current explainability techniques and evaluation benchmarks focus on model robustness or individual task performance, as opposed to interpreting model predictions. To this end, this paper introduces ASTxplainer, an explainability method specific to LLMs for code that enables both new methods for LLM evaluation and visualizations of LLM predictions that aid end-users in understanding model predictions. At its core, ASTxplainer provides an automated method for aligning token predictions with AST nodes, by extracting and aggregating normalized model logits within AST structures. To demonstrate the practical benefit of ASTxplainer, we illustrate the insights that our framework can provide by performing an empirical evaluation on 12 popular LLMs for code using a curated dataset of the most popular GitHub projects. Additionally, we perform a user study examining the usefulness of an ASTxplainer-derived visualization of model predictions aimed at enabling model users to explain predictions. The results of these studies illustrate the potential for ASTxplainer to provide insights into LLM effectiveness, and aid end-users in understanding predictions.