 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating and Explaining Large Language Models for Code Using Syntactic Structures
Aug 07, 2023

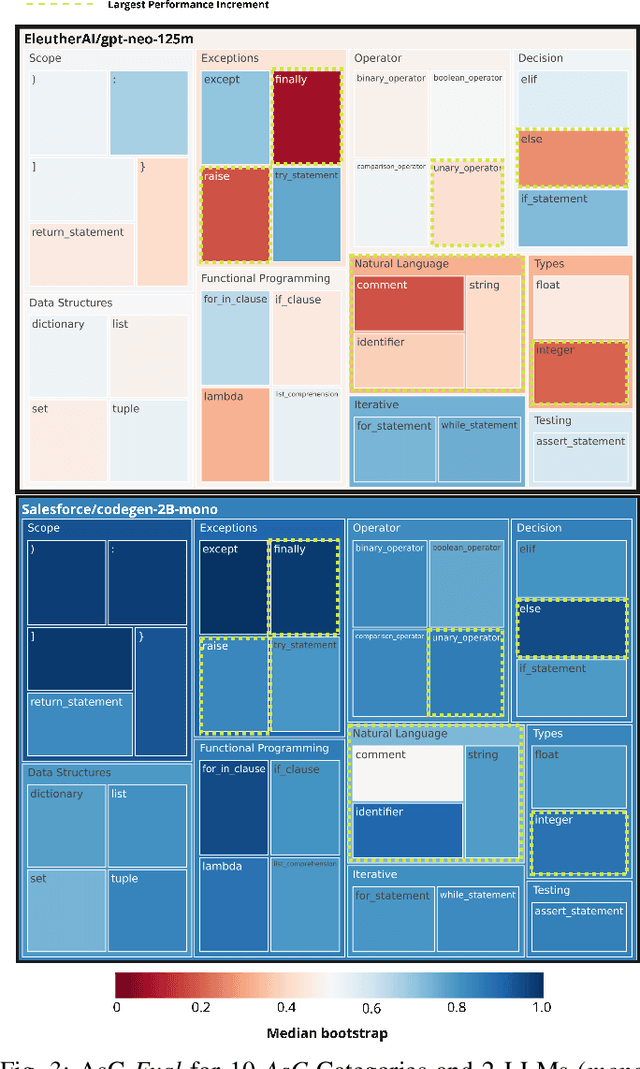

Large Language Models (LLMs) for code are a family of high-parameter, transformer-based neural networks pre-trained on massive datasets of both natural and programming languages. These models are rapidly being employed in commercial AI-based developer tools, such as GitHub CoPilot. However, measuring and explaining their effectiveness on programming tasks is a challenging proposition, given their size and complexity. The methods for evaluating and explaining LLMs for code are inextricably linked. That is, in order to explain a model's predictions, they must be reliably mapped to fine-grained, understandable concepts. Once this mapping is achieved, new methods for detailed model evaluations are possible. However, most current explainability techniques and evaluation benchmarks focus on model robustness or individual task performance, as opposed to interpreting model predictions. To this end, this paper introduces ASTxplainer, an explainability method specific to LLMs for code that enables both new methods for LLM evaluation and visualizations of LLM predictions that aid end-users in understanding model predictions. At its core, ASTxplainer provides an automated method for aligning token predictions with AST nodes, by extracting and aggregating normalized model logits within AST structures. To demonstrate the practical benefit of ASTxplainer, we illustrate the insights that our framework can provide by performing an empirical evaluation on 12 popular LLMs for code using a curated dataset of the most popular GitHub projects. Additionally, we perform a user study examining the usefulness of an ASTxplainer-derived visualization of model predictions aimed at enabling model users to explain predictions. The results of these studies illustrate the potential for ASTxplainer to provide insights into LLM effectiveness, and aid end-users in understanding predictions.