 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Semantically Equivalent Code Transformations Impact Membership Inference on LLMs for Code?
Dec 17, 2025The success of large language models for code relies on vast amounts of code data, including public open-source repositories, such as GitHub, and private, confidential code from companies. This raises concerns about intellectual property compliance and the potential unauthorized use of license-restricted code. While membership inference (MI) techniques have been proposed to detect such unauthorized usage, their effectiveness can be undermined by semantically equivalent code transformation techniques, which modify code syntax while preserving semantic. In this work, we systematically investigate whether semantically equivalent code transformation rules might be leveraged to evade MI detection. The results reveal that model accuracy drops by only 1.5% in the worst case for each rule, demonstrating that transformed datasets can effectively serve as substitutes for fine-tuning. Additionally, we find that one of the rules (RenameVariable) reduces MI success by 10.19%, highlighting its potential to obscure the presence of restricted code. To validate these findings, we conduct a causal analysis confirming that variable renaming has the strongest causal effect in disrupting MI detection. Notably, we find that combining multiple transformations does not further reduce MI effectiveness. Our results expose a critical loophole in license compliance enforcement for training large language models for code, showing that MI detection can be substantially weakened by transformation-based obfuscation techniques.
Understanding Privacy Risks in Code Models Through Training Dynamics: A Causal Approach
Dec 09, 2025Large language models for code (LLM4Code) have greatly improved developer productivity but also raise privacy concerns due to their reliance on open-source repositories containing abundant personally identifiable information (PII). Prior work shows that commercial models can reproduce sensitive PII, yet existing studies largely treat PII as a single category and overlook the heterogeneous risks among different types. We investigate whether distinct PII types vary in their likelihood of being learned and leaked by LLM4Code, and whether this relationship is causal. Our methodology includes building a dataset with diverse PII types, fine-tuning representative models of different scales, computing training dynamics on real PII data, and formulating a structural causal model to estimate the causal effect of learnability on leakage. Results show that leakage risks differ substantially across PII types and correlate with their training dynamics: easy-to-learn instances such as IP addresses exhibit higher leakage, while harder types such as keys and passwords leak less frequently. Ambiguous types show mixed behaviors. This work provides the first causal evidence that leakage risks are type-dependent and offers guidance for developing type-aware and learnability-aware defenses for LLM4Code.
On Explaining (Large) Language Models For Code Using Global Code-Based Explanations
Mar 21, 2025In recent years, Language Models for Code (LLM4Code) have significantly changed the landscape of software engineering (SE) on downstream tasks, such as code generation, by making software development more efficient. Therefore, a growing interest has emerged in further evaluating these Language Models to homogenize the quality assessment of generated code. As the current evaluation process can significantly overreact on accuracy-based metrics, practitioners often seek methods to interpret LLM4Code outputs beyond canonical benchmarks. While the majority of research reports on code generation effectiveness in terms of expected ground truth, scant attention has been paid to LLMs' explanations. In essence, the decision-making process to generate code is hard to interpret. To bridge this evaluation gap, we introduce code rationales (Code$Q$), a technique with rigorous mathematical underpinning, to identify subsets of tokens that can explain individual code predictions. We conducted a thorough Exploratory Analysis to demonstrate the method's applicability and a User Study to understand the usability of code-based explanations. Our evaluation demonstrates that Code$Q$ is a powerful interpretability method to explain how (less) meaningful input concepts (i.e., natural language particle `at') highly impact output generation. Moreover, participants of this study highlighted Code$Q$'s ability to show a causal relationship between the input and output of the model with readable and informative explanations on code completion and test generation tasks. Additionally, Code$Q$ also helps to uncover model rationale, facilitating comparison with a human rationale to promote a fair level of trust and distrust in the model.
SnipGen: A Mining Repository Framework for Evaluating LLMs for Code
Feb 10, 2025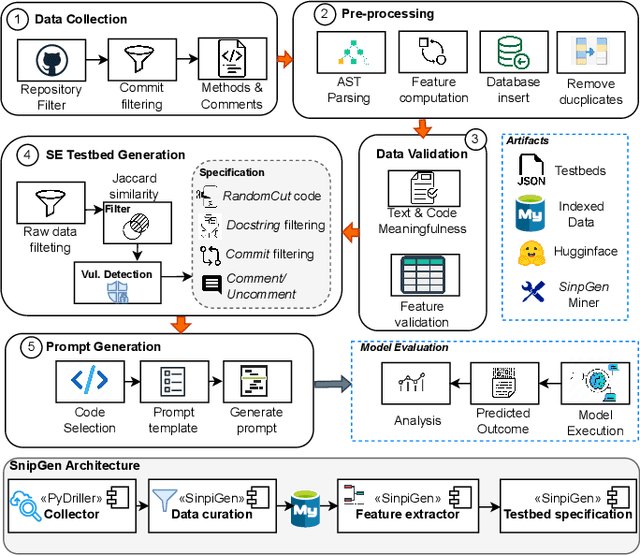
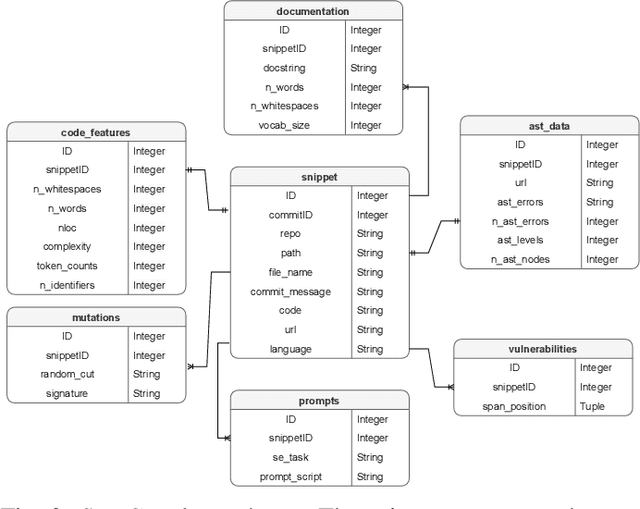


Language Models (LLMs), such as transformer-based neural networks trained on billions of parameters, have become increasingly prevalent in software engineering (SE). These models, trained on extensive datasets that include code repositories, exhibit remarkable capabilities for SE tasks. However, evaluating their effectiveness poses significant challenges, primarily due to the potential overlap between the datasets used for training and those employed for evaluation. To address this issue, we introduce SnipGen, a comprehensive repository mining framework designed to leverage prompt engineering across various downstream tasks for code generation. SnipGen aims to mitigate data contamination by generating robust testbeds and crafting tailored data points to assist researchers and practitioners in evaluating LLMs for code-related tasks. In our exploratory study, SnipGen mined approximately 227K data points from 338K recent code changes in GitHub commits, focusing on method-level granularity. SnipGen features a collection of prompt templates that can be combined to create a Chain-of-Thought-like sequence of prompts, enabling a nuanced assessment of LLMs' code generation quality. By providing the mining tool, the methodology, and the dataset, SnipGen empowers researchers and practitioners to rigorously evaluate and interpret LLMs' performance in software engineering contexts.
Toward Neurosymbolic Program Comprehension
Feb 03, 2025


Recent advancements in Large Language Models (LLMs) have paved the way for Large Code Models (LCMs), enabling automation in complex software engineering tasks, such as code generation, software testing, and program comprehension, among others. Tools like GitHub Copilot and ChatGPT have shown substantial benefits in supporting developers across various practices. However, the ambition to scale these models to trillion-parameter sizes, exemplified by GPT-4, poses significant challenges that limit the usage of Artificial Intelligence (AI)-based systems powered by large Deep Learning (DL) models. These include rising computational demands for training and deployment and issues related to trustworthiness, bias, and interpretability. Such factors can make managing these models impractical for many organizations, while their "black-box'' nature undermines key aspects, including transparency and accountability. In this paper, we question the prevailing assumption that increasing model parameters is always the optimal path forward, provided there is sufficient new data to learn additional patterns. In particular, we advocate for a Neurosymbolic research direction that combines the strengths of existing DL techniques (e.g., LLMs) with traditional symbolic methods--renowned for their reliability, speed, and determinism. To this end, we outline the core features and present preliminary results for our envisioned approach, aimed at establishing the first Neurosymbolic Program Comprehension (NsPC) framework to aid in identifying defective code components.
How Propense Are Large Language Models at Producing Code Smells? A Benchmarking Study
Dec 25, 2024



Large Language Models (LLMs) have shown significant potential in automating software engineering tasks, particularly in code generation. However, current evaluation benchmarks, which primarily focus on accuracy, fall short in assessing the quality of the code generated by these models, specifically their tendency to produce code smells. To address this limitation, we introduce CodeSmellEval, a benchmark designed to evaluate the propensity of LLMs for generating code smells. Our benchmark includes a novel metric: Propensity Smelly Score (PSC), and a curated dataset of method-level code smells: CodeSmellData. To demonstrate the use of CodeSmellEval, we conducted a case study with two state-of-the-art LLMs, CodeLlama and Mistral. The results reveal that both models tend to generate code smells, such as simplifiable-condition and consider-merging-isinstance. These findings highlight the effectiveness of our benchmark in evaluating LLMs, providing valuable insights into their reliability and their propensity to introduce code smells in code generation tasks.
Towards More Trustworthy and Interpretable LLMs for Code through Syntax-Grounded Explanations
Jul 12, 2024



Trustworthiness and interpretability are inextricably linked concepts for LLMs. The more interpretable an LLM is, the more trustworthy it becomes. However, current techniques for interpreting LLMs when applied to code-related tasks largely focus on accuracy measurements, measures of how models react to change, or individual task performance instead of the fine-grained explanations needed at prediction time for greater interpretability, and hence trust. To improve upon this status quo, this paper introduces ASTrust, an interpretability method for LLMs of code that generates explanations grounded in the relationship between model confidence and syntactic structures of programming languages. ASTrust explains generated code in the context of syntax categories based on Abstract Syntax Trees and aids practitioners in understanding model predictions at both local (individual code snippets) and global (larger datasets of code) levels. By distributing and assigning model confidence scores to well-known syntactic structures that exist within ASTs, our approach moves beyond prior techniques that perform token-level confidence mapping by offering a view of model confidence that directly aligns with programming language concepts with which developers are familiar. To put ASTrust into practice, we developed an automated visualization that illustrates the aggregated model confidence scores superimposed on sequence, heat-map, and graph-based visuals of syntactic structures from ASTs. We examine both the practical benefit that ASTrust can provide through a data science study on 12 popular LLMs on a curated set of GitHub repos and the usefulness of ASTrust through a human study.
Evaluating and Explaining Large Language Models for Code Using Syntactic Structures
Aug 07, 2023

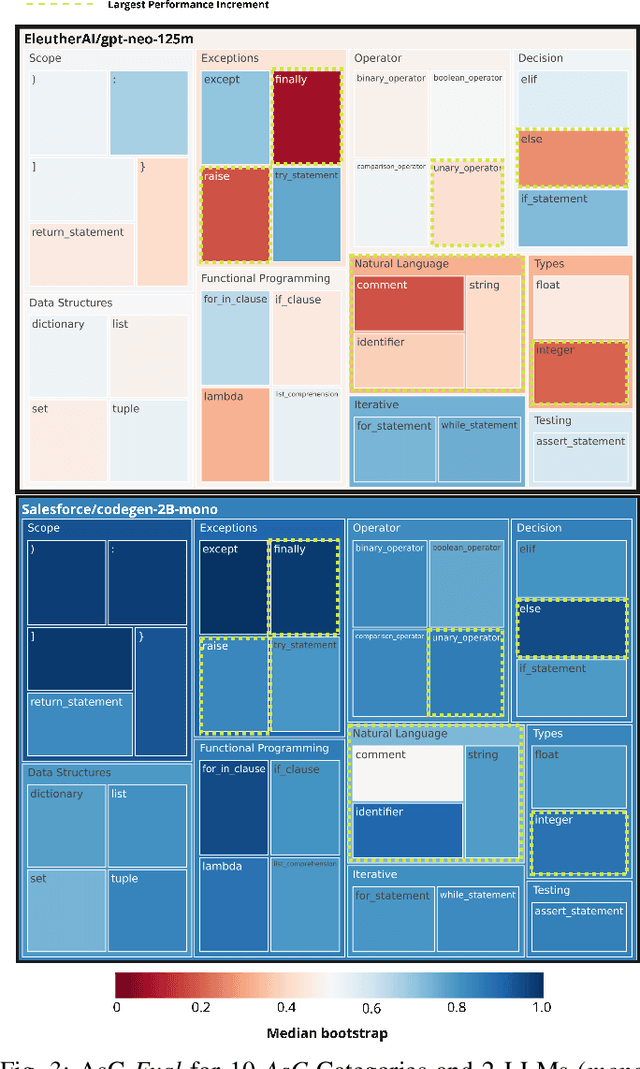

Large Language Models (LLMs) for code are a family of high-parameter, transformer-based neural networks pre-trained on massive datasets of both natural and programming languages. These models are rapidly being employed in commercial AI-based developer tools, such as GitHub CoPilot. However, measuring and explaining their effectiveness on programming tasks is a challenging proposition, given their size and complexity. The methods for evaluating and explaining LLMs for code are inextricably linked. That is, in order to explain a model's predictions, they must be reliably mapped to fine-grained, understandable concepts. Once this mapping is achieved, new methods for detailed model evaluations are possible. However, most current explainability techniques and evaluation benchmarks focus on model robustness or individual task performance, as opposed to interpreting model predictions. To this end, this paper introduces ASTxplainer, an explainability method specific to LLMs for code that enables both new methods for LLM evaluation and visualizations of LLM predictions that aid end-users in understanding model predictions. At its core, ASTxplainer provides an automated method for aligning token predictions with AST nodes, by extracting and aggregating normalized model logits within AST structures. To demonstrate the practical benefit of ASTxplainer, we illustrate the insights that our framework can provide by performing an empirical evaluation on 12 popular LLMs for code using a curated dataset of the most popular GitHub projects. Additionally, we perform a user study examining the usefulness of an ASTxplainer-derived visualization of model predictions aimed at enabling model users to explain predictions. The results of these studies illustrate the potential for ASTxplainer to provide insights into LLM effectiveness, and aid end-users in understanding predictions.