 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Comprehensive Benchmarking Infrastructure for LLMs In Software Engineering
Jan 28, 2026Large language models for code are advancing fast, yet our ability to evaluate them lags behind. Current benchmarks focus on narrow tasks and single metrics, which hide critical gaps in robustness, interpretability, fairness, efficiency, and real-world usability. They also suffer from inconsistent data engineering practices, limited software engineering context, and widespread contamination issues. To understand these problems and chart a path forward, we combined an in-depth survey of existing benchmarks with insights gathered from a dedicated community workshop. We identified three core barriers to reliable evaluation: the absence of software-engineering-rich datasets, overreliance on ML-centric metrics, and the lack of standardized, reproducible data pipelines. Building on these findings, we introduce BEHELM, a holistic benchmarking infrastructure that unifies software-scenario specification with multi-metric evaluation. BEHELM provides a structured way to assess models across tasks, languages, input and output granularities, and key quality dimensions. Our goal is to reduce the overhead currently required to construct benchmarks while enabling a fair, realistic, and future-proof assessment of LLMs in software engineering.
* Short paper from bechmarking for software engineering workshop FSE2025
Toward Explaining Large Language Models in Software Engineering Tasks
Dec 23, 2025Recent progress in Large Language Models (LLMs) has substantially advanced the automation of software engineering (SE) tasks, enabling complex activities such as code generation and code summarization. However, the black-box nature of LLMs remains a major barrier to their adoption in high-stakes and safety-critical domains, where explainability and transparency are vital for trust, accountability, and effective human supervision. Despite increasing interest in explainable AI for software engineering, existing methods lack domain-specific explanations aligned with how practitioners reason about SE artifacts. To address this gap, we introduce FeatureSHAP, the first fully automated, model-agnostic explainability framework tailored to software engineering tasks. Based on Shapley values, FeatureSHAP attributes model outputs to high-level input features through systematic input perturbation and task-specific similarity comparisons, while remaining compatible with both open-source and proprietary LLMs. We evaluate FeatureSHAP on two bi-modal SE tasks: code generation and code summarization. The results show that FeatureSHAP assigns less importance to irrelevant input features and produces explanations with higher fidelity than baseline methods. A practitioner survey involving 37 participants shows that FeatureSHAP helps practitioners better interpret model outputs and make more informed decisions. Collectively, FeatureSHAP represents a meaningful step toward practical explainable AI in software engineering. FeatureSHAP is available at https://github.com/deviserlab/FeatureSHAP.
Toward Neurosymbolic Program Comprehension
Feb 03, 2025


Recent advancements in Large Language Models (LLMs) have paved the way for Large Code Models (LCMs), enabling automation in complex software engineering tasks, such as code generation, software testing, and program comprehension, among others. Tools like GitHub Copilot and ChatGPT have shown substantial benefits in supporting developers across various practices. However, the ambition to scale these models to trillion-parameter sizes, exemplified by GPT-4, poses significant challenges that limit the usage of Artificial Intelligence (AI)-based systems powered by large Deep Learning (DL) models. These include rising computational demands for training and deployment and issues related to trustworthiness, bias, and interpretability. Such factors can make managing these models impractical for many organizations, while their "black-box'' nature undermines key aspects, including transparency and accountability. In this paper, we question the prevailing assumption that increasing model parameters is always the optimal path forward, provided there is sufficient new data to learn additional patterns. In particular, we advocate for a Neurosymbolic research direction that combines the strengths of existing DL techniques (e.g., LLMs) with traditional symbolic methods--renowned for their reliability, speed, and determinism. To this end, we outline the core features and present preliminary results for our envisioned approach, aimed at establishing the first Neurosymbolic Program Comprehension (NsPC) framework to aid in identifying defective code components.
The Rise and Fall of Software Engineering
Jun 14, 2024Over the last ten years, the realm of Artificial Intelligence (AI) has experienced an explosion of revolutionary breakthroughs, transforming what seemed like a far-off dream into a reality that is now deeply embedded in our everyday lives. AI's widespread impact is revolutionizing virtually all aspects of human life, and software engineering (SE) is no exception. As we explore this changing landscape, we are faced with questions about what the future holds for SE and how AI will reshape the roles, duties, and methodologies within the field. The introduction of these groundbreaking technologies highlights the inevitable shift towards a new paradigm, suggesting a future where AI's capabilities may redefine the boundaries of SE, potentially even more than human input. In this paper, we aim at outlining the key elements that, based on our expertise, are vital for the smooth integration of AI into SE, all while preserving the intrinsic human creativity that has been the driving force behind the field. First, we provide a brief description of SE and AI evolution. Afterward, we delve into the intricate interplay between AI-driven automation and human innovation, exploring how these two components can work together to advance SE practices to new methods and standards.
Towards Automatically Addressing Self-Admitted Technical Debt: How Far Are We?
Aug 17, 2023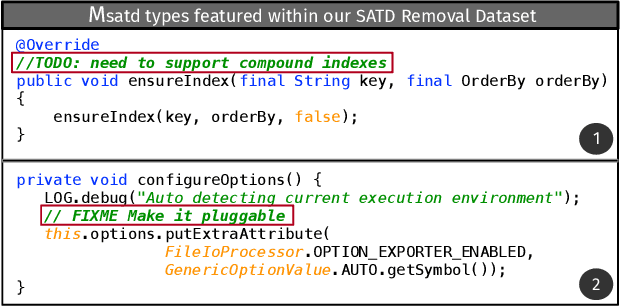

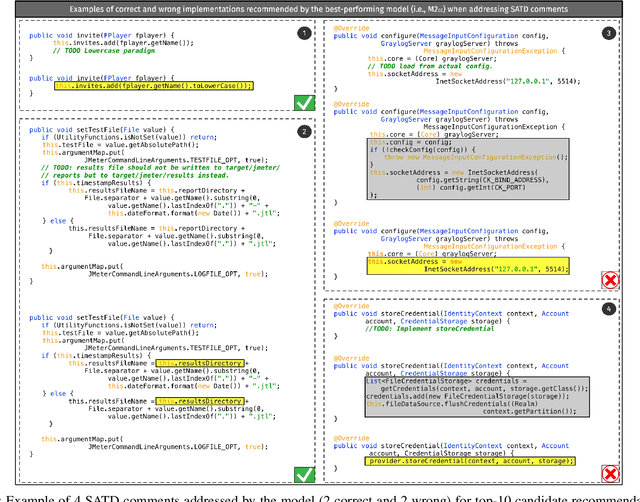
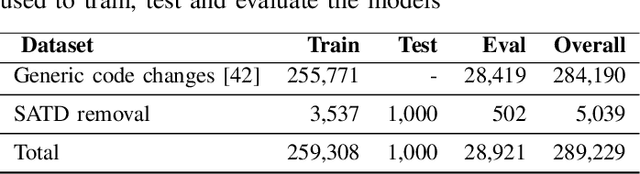
Upon evolving their software, organizations and individual developers have to spend a substantial effort to pay back technical debt, i.e., the fact that software is released in a shape not as good as it should be, e.g., in terms of functionality, reliability, or maintainability. This paper empirically investigates the extent to which technical debt can be automatically paid back by neural-based generative models, and in particular models exploiting different strategies for pre-training and fine-tuning. We start by extracting a dateset of 5,039 Self-Admitted Technical Debt (SATD) removals from 595 open-source projects. SATD refers to technical debt instances documented (e.g., via code comments) by developers. We use this dataset to experiment with seven different generative deep learning (DL) model configurations. Specifically, we compare transformers pre-trained and fine-tuned with different combinations of training objectives, including the fixing of generic code changes, SATD removals, and SATD-comment prompt tuning. Also, we investigate the applicability in this context of a recently-available Large Language Model (LLM)-based chat bot. Results of our study indicate that the automated repayment of SATD is a challenging task, with the best model we experimented with able to automatically fix ~2% to 8% of test instances, depending on the number of attempts it is allowed to make. Given the limited size of the fine-tuning dataset (~5k instances), the model's pre-training plays a fundamental role in boosting performance. Also, the ability to remove SATD steadily drops if the comment documenting the SATD is not provided as input to the model. Finally, we found general-purpose LLMs to not be a competitive approach for addressing SATD.